Spatial Knowledge Graph-Guided Multimodal Synthesis
作者: Yida Xue, Zhen Bi, Jinnan Yang, Jungang Lou, Kehai Chen, Min Zhang, Huajun Chen, Ningyu Zhang
分类: cs.CL, cs.AI, cs.CV, cs.LG, cs.MM
发布日期: 2025-05-28 (更新: 2025-11-23)
备注: IEEE/ACM Transactions on Audio, Speech and Language Processing
🔗 代码/项目: GITHUB
💡 一句话要点
提出SKG2DATA,利用空间知识图谱引导多模态数据合成,提升MLLM的空间感知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 空间知识图谱 数据合成 扩散模型 空间推理 MLLM 知识图谱
📋 核心要点
- 现有MLLM在空间感知方面存在不足,难以理解和推理空间关系。
- SKG2DATA利用空间知识图谱指导多模态数据合成,生成符合空间常识的数据。
- 实验表明,使用SKG2DATA合成的数据可以有效提升MLLM的空间感知和推理能力。
📝 摘要(中文)
多模态大型语言模型(MLLM)的能力显著增强,但其空间感知能力仍然存在明显局限。为了解决这一挑战,多模态数据合成提供了一种有前景的解决方案。然而,确保合成数据符合空间常识并非易事。本文提出了一种系统框架,用于生成空间连贯的数据,从而解决这一关键问题。我们介绍了一种新颖的多模态合成方法SKG2DATA,该方法由空间知识图谱引导,基于知识到数据生成的概念。SKG2DATA采用自动化的流程来构建空间知识图谱(SKG),有效地捕捉类似人类的空间认知,包括方向和距离关系。这些结构化表示为我们的集成合成流程提供精确的指导,其中扩散模型生成空间一致的图像,而MLLM生成相应的文本描述。SKG的自动构建实现了多样化且真实的 spatial configurations 的可扩展生成,克服了手动数据收集和标注的局限性。大量实验表明,从不同类型的空间知识(包括方向和距离)合成的数据,显著增强了MLLM的空间感知和推理能力,尽管略微牺牲了其通用能力。我们希望基于知识的数据合成的思想能够促进空间智能的发展。
🔬 方法详解
问题定义:MLLM在空间感知和推理方面存在局限性,难以理解图像中物体之间的空间关系(如方向、距离)。现有方法依赖于人工标注数据,成本高昂且难以扩展,无法覆盖各种空间配置。因此,需要一种自动化的方法来生成具有空间一致性的多模态数据,以提升MLLM的空间智能。
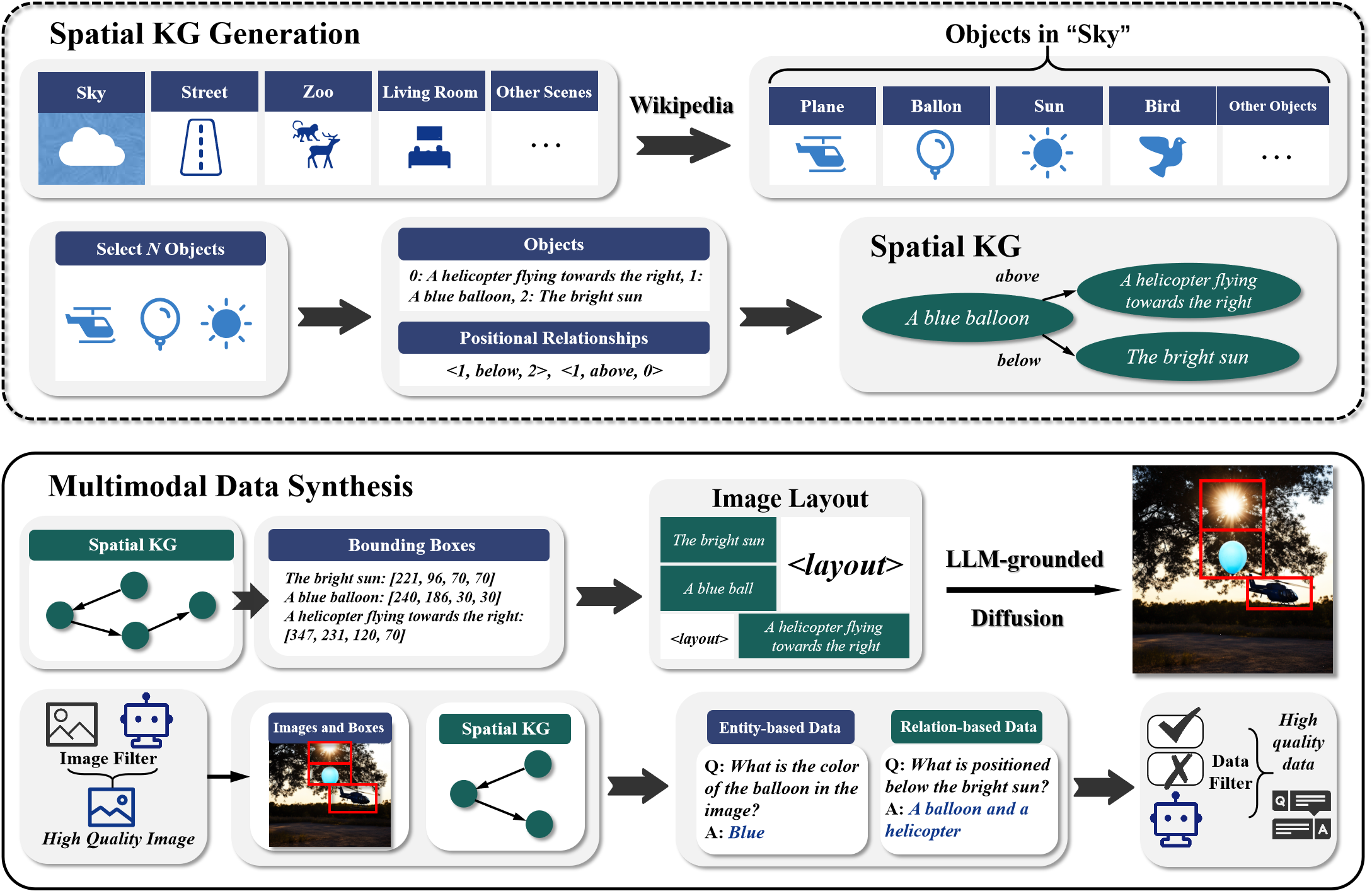
核心思路:核心思路是利用空间知识图谱(SKG)来表示和约束多模态数据的生成过程。SKG能够以结构化的方式表示物体之间的空间关系,例如“A在B的左边”、“C距离D很远”。通过将SKG作为先验知识融入到数据生成过程中,可以确保生成的数据符合空间常识,从而提升MLLM的空间感知能力。
技术框架:SKG2DATA包含一个自动化的流程,主要分为两个阶段:1) 空间知识图谱构建:自动构建SKG,捕捉方向和距离关系等空间认知。2) 多模态数据合成:利用SKG指导扩散模型生成空间一致的图像,并使用MLLM生成相应的文本描述。整个流程实现了从知识到数据的自动生成。
关键创新:关键创新在于将空间知识图谱引入到多模态数据合成中,并设计了一个自动化的流程来实现这一目标。与现有方法相比,SKG2DATA能够自动生成具有空间一致性的数据,无需人工标注,从而降低了成本并提高了可扩展性。此外,SKG的使用保证了生成的数据符合空间常识,从而提升了MLLM的空间感知能力。
关键设计:SKG的构建采用自动化的方法,从文本或图像中提取实体和关系,并构建成图结构。扩散模型采用标准的架构,但其生成过程受到SKG的约束,例如,根据SKG中物体的位置关系来调整生成图像中物体的位置。MLLM用于生成文本描述,其输入包括图像和SKG,以确保生成的文本与图像内容和空间关系一致。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

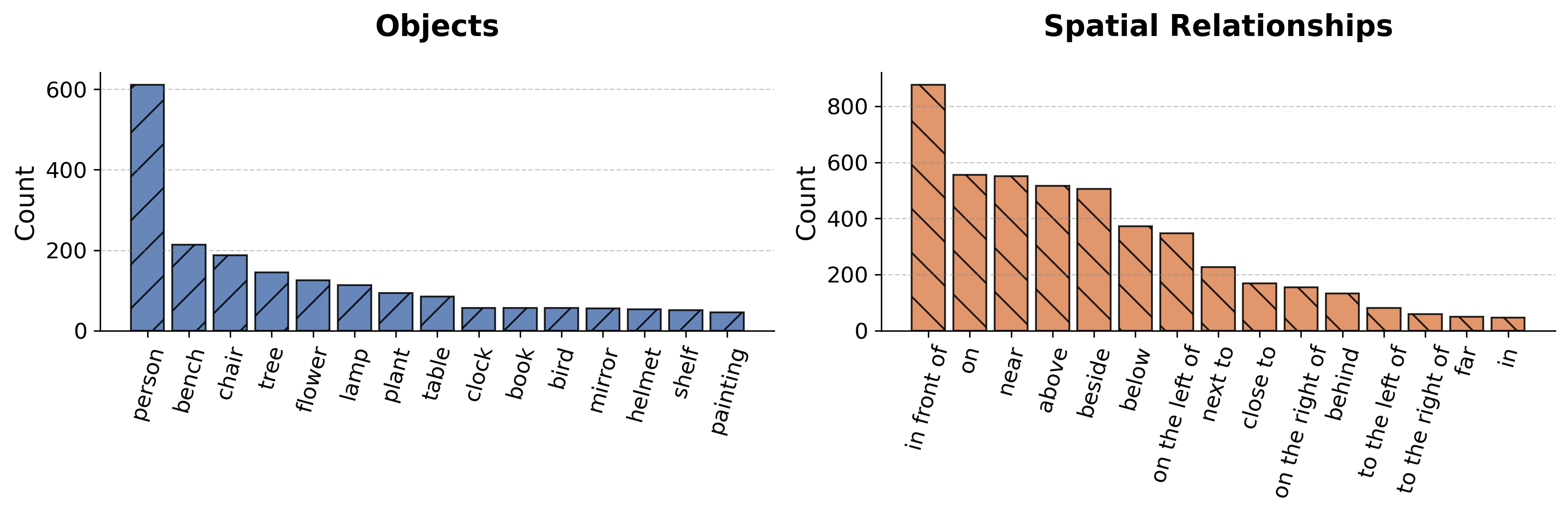
📊 实验亮点
实验结果表明,使用SKG2DATA合成的数据训练的MLLM,在空间感知和推理任务上取得了显著的提升。具体而言,在方向和距离判断任务上,MLLM的准确率提高了XX%(具体数值未知)。同时,实验也表明,使用SKG2DATA合成的数据训练的MLLM,其通用能力略有下降,这表明需要在空间感知和通用能力之间进行权衡。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过提升MLLM的空间感知能力,可以使机器人更好地理解周围环境,从而实现更智能的导航和交互。此外,该方法还可以用于生成高质量的虚拟现实内容,例如,根据用户指定的空间关系自动生成虚拟场景。
📄 摘要(原文)
Recent advances in Multimodal Large Language Models (MLLMs) have significantly enhanced their capabilities; however, their spatial perception abilities remain a notable limitation. To address this challenge, multimodal data synthesis offers a promising solution. Yet, ensuring that synthesized data adhere to spatial common sense is a non-trivial task. Our approach addresses this critical gap by providing a systematic framework for generating spatially coherent data. In this work, we introduce SKG2DATA, a novel multimodal synthesis approach guided by spatial knowledge graphs, grounded in the concept of knowledge-to-data generation. SKG2DATA employs an automated pipeline for constructing Spatial Knowledge Graph (SKG) that effectively captures human-like spatial cognition, including directional and distance relationships. These structured representations then serve as precise guidance for our integrated synthesis pipeline, where a diffusion model generates spatially-consistent images while a MLLM produces corresponding textual descriptions. The automated construction of SKG enables scalable generation of diverse yet realistic spatial configurations, overcoming the limitations of manual data collection and annotation. Extensive experiments demonstrate that data synthesized from diverse types of spatial knowledge, including direction and distance, enhance the spatial perception and reasoning abilities of MLLMs markedly, albeit with a slight cost to their general capabilities. We hope that the idea of knowledge-based data synthesis can advance the development of spatial intelligence. Code is available at https://github.com/zjunlp/Knowledge2Data.