Multi-MLLM Knowledge Distillation for Out-of-Context News Detection
作者: Yimeng Gu, Zhao Tong, Ignacio Castro, Shu Wu, Gareth Tyson
分类: cs.CL, cs.MM
发布日期: 2025-05-28
💡 一句话要点
提出多模态大语言模型知识蒸馏以解决低资源环境下的新闻检测问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 知识蒸馏 上下文外新闻 低资源学习 信息验证
📋 核心要点
- 现有多模态大语言模型在检测上下文外新闻时,零样本性能有限,需依赖大量标注数据和高成本API。
- 本文提出通过多个教师模型生成标签和推理,采用两阶段知识蒸馏框架,提升小型模型的性能。
- 实验表明,使用不到10%的标注数据,本文方法在性能上达到了当前的最先进水平。
📝 摘要(中文)
多模态的上下文外新闻是一种利用图像在原始上下文之外传播的错误信息。现有方法在零样本性能上表现有限,通常需要丰富的标签微调或昂贵的API调用来提升性能,这在低资源场景中并不实用。本文旨在以更高效的方式提升小型多模态大语言模型的性能。我们首先通过多个教师模型生成标签预测和相应的推理,构建教师知识。然后引入两阶段知识蒸馏框架,将这些知识转移到学生模型中。实验结果表明,该方法在使用不到10%的标注数据的情况下,达到了最先进的性能。
🔬 方法详解
问题定义:本文解决的是多模态上下文外新闻检测中的低资源问题,现有方法在零样本性能上表现不佳,依赖大量标注数据和高成本API调用。
核心思路:通过多个教师模型生成标签预测和推理,构建知识库,并采用两阶段知识蒸馏框架将知识转移到学生模型,以提高小型模型的性能。
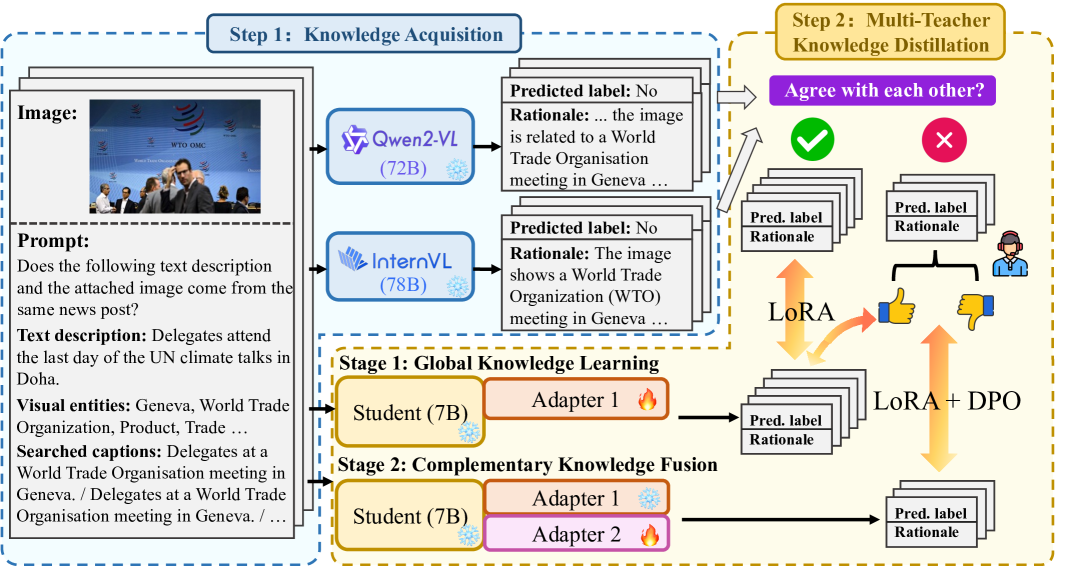
技术框架:整体架构分为两个阶段:第一阶段使用LoRA微调学生模型,第二阶段在教师预测存在冲突的数据点上,结合LoRA微调和DPO进一步微调学生模型。
关键创新:最重要的创新在于提出了两阶段知识蒸馏策略,能够在减少标注成本的同时,帮助学生模型识别更复杂的模式。
关键设计:在第一阶段,使用LoRA微调,第二阶段结合DPO,针对教师模型预测冲突的数据进行微调,确保学生模型能够学习到更细微的模式。
🖼️ 关键图片
📊 实验亮点
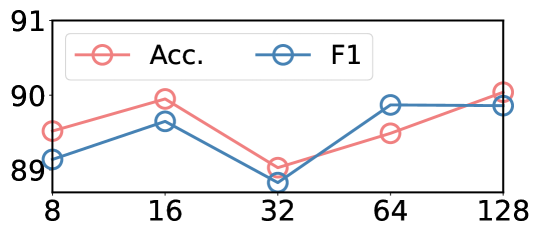
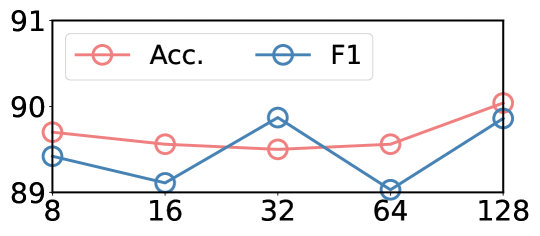
实验结果显示,本文方法在使用不到10%的标注数据的情况下,达到了最先进的性能,相较于基线模型,性能提升显著,展示了知识蒸馏在低资源环境中的有效性。
🎯 应用场景
该研究的潜在应用领域包括新闻媒体、社交网络和信息验证等。通过提升小型多模态模型的性能,能够在资源有限的情况下有效检测和识别错误信息,具有重要的社会价值和实际影响。
📄 摘要(原文)
Multimodal out-of-context news is a type of misinformation in which the image is used outside of its original context. Many existing works have leveraged multimodal large language models (MLLMs) for detecting out-of-context news. However, observing the limited zero-shot performance of smaller MLLMs, they generally require label-rich fine-tuning and/or expensive API calls to GPT models to improve the performance, which is impractical in low-resource scenarios. In contrast, we aim to improve the performance of small MLLMs in a more label-efficient and cost-effective manner. To this end, we first prompt multiple teacher MLLMs to generate both label predictions and corresponding rationales, which collectively serve as the teachers' knowledge. We then introduce a two-stage knowledge distillation framework to transfer this knowledge to a student MLLM. In Stage 1, we apply LoRA fine-tuning to the student model using all training data. In Stage 2, we further fine-tune the student model using both LoRA fine-tuning and DPO on the data points where teachers' predictions conflict. This two-stage strategy reduces annotation costs and helps the student model uncover subtle patterns in more challenging cases. Experimental results demonstrate that our approach achieves state-of-the-art performance using less than 10% labeled data.