First SFT, Second RL, Third UPT: Continual Improving Multi-Modal LLM Reasoning via Unsupervised Post-Training
作者: Lai Wei, Yuting Li, Chen Wang, Yue Wang, Linghe Kong, Weiran Huang, Lichao Sun
分类: cs.CL, cs.AI, cs.CV, cs.LG
发布日期: 2025-05-28 (更新: 2025-10-27)
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MM-UPT框架,通过无监督后训练持续提升多模态LLM的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 无监督学习 后训练 自奖励 数据自生成 推理能力
📋 核心要点
- 现有MLLM的后训练依赖有监督微调或强化学习,需要昂贵的人工标注多模态数据,资源不可持续。
- MM-UPT框架采用无监督后训练,基于GRPO,使用自奖励机制,无需外部监督即可持续提升模型推理能力。
- 实验表明,MM-UPT能有效提升Qwen2.5-VL-7B在MathVista和We-Math等数据集上的推理性能,并探索了数据自生成的可扩展性。
📝 摘要(中文)
本文提出了一种名为MM-UPT的简单而有效的框架,用于多模态大型语言模型(MLLM)的无监督后训练,能够在没有任何外部监督的情况下实现持续的自我改进。MM-UPT的训练方法基于GRPO,用基于多数投票的自奖励机制取代了传统的奖励信号。实验表明,这种训练方法有效地提高了Qwen2.5-VL-7B的推理能力(例如,在MathVista上从66.3%提升到72.9%,在We-Math上从62.9%提升到68.7%),使用的是没有ground truth标签的标准数据集。为了进一步探索可扩展性,我们将框架扩展到数据自生成设置,设计了两种策略来提示MLLM自行合成新的训练样本。额外的实验表明,将这些合成数据与无监督训练方法相结合也可以提高性能,突出了可扩展自我改进的一种有前景的方法。总的来说,MM-UPT为MLLM的自主增强提供了一种新的范例,在缺乏外部监督的情况下,作为初始SFT和RL之后的关键第三步。
🔬 方法详解
问题定义:现有方法在提升多模态大型语言模型(MLLM)的推理能力时,通常依赖于有监督微调(SFT)或强化学习(RL)。这两种方法都需要大量人工标注的多模态数据,成本高昂且难以持续。因此,如何在无监督的条件下,持续提升MLLM的推理能力是一个重要的研究问题。
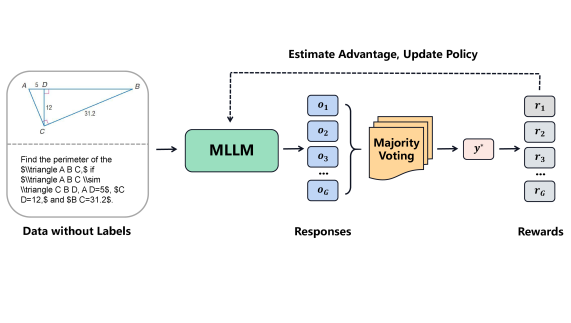
核心思路:MM-UPT的核心思路是利用无监督后训练,让MLLM在没有人工标注数据的情况下,通过自我学习和改进来提升推理能力。具体来说,它采用了一种基于多数投票的自奖励机制,让模型自己评估生成结果的质量,并以此作为训练信号。这种方法避免了对外部奖励信号的依赖,实现了真正的无监督学习。
技术框架:MM-UPT框架主要包含以下几个阶段:1) 使用SFT和RL对MLLM进行预训练;2) 使用MM-UPT进行无监督后训练,该阶段的核心是基于GRPO的训练方法,用自奖励机制取代传统奖励信号;3) 可选的数据自生成阶段,利用MLLM生成新的训练样本,进一步提升模型性能。整体流程是先通过有监督和强化学习进行初步训练,然后通过无监督后训练进行持续改进,并可以结合数据自生成来提高可扩展性。
关键创新:MM-UPT最重要的技术创新点在于其无监督后训练的范式。与传统的有监督或强化学习方法不同,MM-UPT不需要任何人工标注的数据,而是通过自奖励机制让模型自己学习和改进。这种方法降低了训练成本,提高了模型的可扩展性。此外,数据自生成策略也为进一步提升模型性能提供了新的途径。
关键设计:MM-UPT的关键设计包括:1) 基于GRPO的训练方法,使用多数投票机制生成自奖励信号;2) 数据自生成策略,包括提示MLLM生成新的训练样本;3) 损失函数的设计,需要保证模型在自学习过程中能够稳定收敛。具体的参数设置和网络结构细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
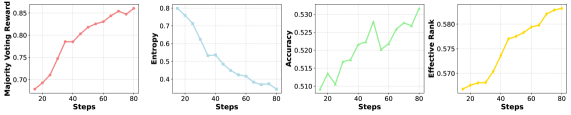
MM-UPT在Qwen2.5-VL-7B模型上取得了显著的性能提升。在MathVista数据集上,模型性能从66.3%提升到72.9%,提升了6.6个百分点;在We-Math数据集上,模型性能从62.9%提升到68.7%,提升了5.8个百分点。这些结果表明,MM-UPT能够有效地提升MLLM的推理能力,且无需人工标注数据。
🎯 应用场景
MM-UPT框架具有广泛的应用前景,可用于各种多模态大型语言模型的自主增强,尤其适用于缺乏标注数据的场景。例如,可以应用于智能客服、自动驾驶、医疗诊断等领域,提升模型在复杂环境下的推理和决策能力。该研究为实现更智能、更自主的AI系统奠定了基础。
📄 摘要(原文)
Improving Multi-modal Large Language Models (MLLMs) in the post-training stage typically relies on supervised fine-tuning (SFT) or reinforcement learning (RL), which require expensive and manually annotated multi-modal data--an ultimately unsustainable resource. This limitation has motivated a growing interest in unsupervised paradigms as a third stage of post-training after SFT and RL. While recent efforts have explored this direction, their methods are complex and difficult to iterate. To address this, we propose MM-UPT, a simple yet effective framework for unsupervised post-training of MLLMs, enabling continual self-improvement without any external supervision. The training method of MM-UPT builds upon GRPO, replacing traditional reward signals with a self-rewarding mechanism based on majority voting over multiple sampled responses. Our experiments demonstrate that such training method effectively improves the reasoning ability of Qwen2.5-VL-7B (e.g., 66.3\%$\rightarrow$72.9\% on MathVista, 62.9\%$\rightarrow$68.7\% on We-Math), using standard dataset without ground truth labels. To further explore scalability, we extend our framework to a data self-generation setting, designing two strategies that prompt the MLLM to synthesize new training samples on its own. Additional experiments show that combining these synthetic data with the unsupervised training method can also boost performance, highlighting a promising approach for scalable self-improvement. Overall, MM-UPT offers a new paradigm for autonomous enhancement of MLLMs, serving as a critical third step after initial SFT and RL in the absence of external supervision. Our code is available at https://github.com/waltonfuture/MM-UPT.