Text2Grad: Reinforcement Learning from Natural Language Feedback
作者: Hanyang Wang, Lu Wang, Chaoyun Zhang, Tianjun Mao, Si Qin, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
分类: cs.CL, cs.AI
发布日期: 2025-05-28 (更新: 2026-01-27)
备注: The code for our method is available at https://github.com/microsoft/Text2Grad
期刊: ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
Text2Grad:利用自然语言反馈进行强化学习,实现细粒度梯度更新。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自然语言反馈 梯度更新 文本生成 可解释性
📋 核心要点
- 传统RLHF依赖粗糙标量奖励,缺乏细粒度反馈,导致学习效率低且过程不透明。
- Text2Grad将自然语言反馈转化为token跨度级别的梯度,直接优化模型策略中的问题部分。
- 实验表明,Text2Grad在摘要、代码生成和问答任务中,性能优于传统RLHF和prompt方法。
📝 摘要(中文)
传统的RLHF使用粗糙的标量奖励优化语言模型,掩盖了成功或失败背后细粒度的原因,导致学习缓慢且不透明。最近的研究通过提示或反思,利用文本评论来增强RL,提高了可解释性,但没有触及模型参数。我们引入Text2Grad,一种强化学习范式,将自由形式的文本反馈转化为跨度级别的梯度。给定人类(或程序)的评论,Text2Grad将每个反馈短语与相关的token跨度对齐,将这些对齐转换为可微分的奖励信号,并执行梯度更新,直接优化模型策略中存在问题的部分。这产生了精确的、反馈条件下的调整,而不是全局的推动。Text2Grad通过三个组件实现:(1)高质量的反馈注释流程,将评论与token跨度配对;(2)细粒度的奖励模型,在生成解释性评论的同时,预测答案的跨度级别奖励;(3)跨度级别的策略优化器,反向传播自然语言梯度。在摘要、代码生成和问答任务中,Text2Grad始终优于标量奖励RL和仅提示的基线,提供了更高的任务指标和更丰富的可解释性。我们的结果表明,自然语言反馈不仅可以作为解释,还可以作为细粒度对齐的可操作训练信号。我们的方法代码可在https://github.com/microsoft/Text2Grad获取。
🔬 方法详解
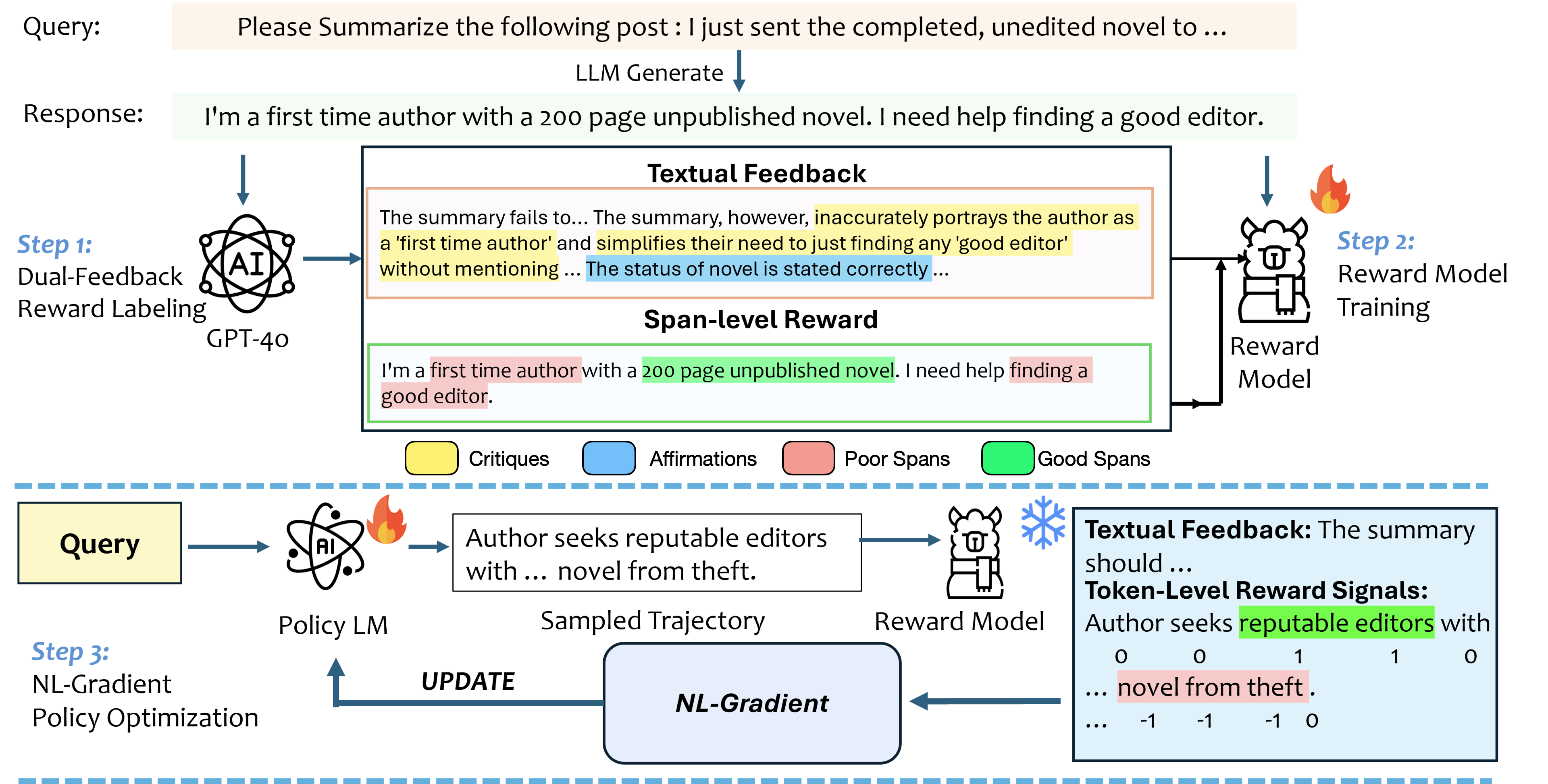
问题定义:现有RLHF方法使用标量奖励,无法提供细粒度的反馈信息,导致模型学习效率低下,难以理解模型行为。此外,基于prompt的文本反馈方法虽然提高了可解释性,但无法直接更新模型参数。
核心思路:Text2Grad的核心思想是将自然语言反馈转化为可微分的梯度信号,并将其应用于模型参数的更新。通过将反馈与token跨度对齐,可以实现对模型策略的细粒度调整,从而提高学习效率和可解释性。
技术框架:Text2Grad包含三个主要模块:(1)反馈注释流程:用于收集高质量的文本反馈,并将反馈与token跨度进行对齐。(2)奖励模型:用于预测答案的跨度级别奖励,并生成解释性评论。(3)策略优化器:用于将奖励信号反向传播到模型参数,实现细粒度的策略更新。整体流程是,模型生成答案,人工或程序提供反馈,反馈经过注释和奖励模型处理后,生成梯度信号,用于更新模型参数。
关键创新:Text2Grad的关键创新在于将自然语言反馈转化为可操作的梯度信号,实现了细粒度的策略优化。与传统的标量奖励RLHF方法相比,Text2Grad能够更精确地调整模型策略,提高学习效率和可解释性。与基于prompt的文本反馈方法相比,Text2Grad能够直接更新模型参数,实现更有效的学习。
关键设计:反馈注释流程需要设计合适的标注规范,确保反馈与token跨度之间的对齐质量。奖励模型需要设计合适的网络结构和损失函数,以准确预测跨度级别奖励并生成高质量的解释性评论。策略优化器需要设计合适的梯度计算方法,以确保梯度信号能够有效地传递到模型参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Text2Grad在摘要、代码生成和问答任务中,始终优于标量奖励RL和仅提示的基线。例如,在摘要任务中,Text2Grad相比传统RLHF方法,ROUGE指标提升显著。此外,Text2Grad还提供了更丰富的可解释性,能够清晰地展示模型策略的改进过程。
🎯 应用场景
Text2Grad具有广泛的应用前景,可用于优化各种生成式模型,例如文本摘要、代码生成、机器翻译和对话系统。通过利用自然语言反馈,可以提高模型的性能、可解释性和安全性。此外,Text2Grad还可以用于个性化学习和教育领域,根据学生的反馈提供定制化的指导。
📄 摘要(原文)
Traditional RLHF optimizes language models with coarse, scalar rewards that mask the fine-grained reasons behind success or failure, leading to slow and opaque learning. Recent work augments RL with textual critiques through prompting or reflection, improving interpretability but leaving model parameters untouched. We introduce Text2Grad, a reinforcement-learning paradigm that turns free-form textual feedback into span-level gradients. Given human (or programmatic) critiques, Text2Grad aligns each feedback phrase with the relevant token spans, converts these alignments into differentiable reward signals, and performs gradient updates that directly refine the offending portions of the model's policy. This yields precise, feedback-conditioned adjustments instead of global nudges. Text2Grad is realized through three components: (1) a high-quality feedback-annotation pipeline that pairs critiques with token spans; (2) a fine-grained reward model that predicts span-level reward on answers while generating explanatory critiques; and (3) a span-level policy optimizer that back-propagates natural-language gradients. Across summarization, code generation, and question answering, Text2Grad consistently surpasses scalar-reward RL and prompt-only baselines, providing both higher task metrics and richer interpretability. Our results suggest that natural-language feedback can serve not only as explanations, but also as actionable training signals for fine-grained alignment. The code for our method is available at https://github.com/microsoft/Text2Grad.