Latent Reasoning via Sentence Embedding Prediction
作者: Hyeonbin Hwang, Byeongguk Jeon, Seungone Kim, Jiyeon Kim, Hoyeon Chang, Sohee Yang, Seungpil Won, Dohaeng Lee, Youbin Ahn, Minjoon Seo
分类: cs.CL, cs.AI
发布日期: 2025-05-28 (更新: 2025-10-11)
备注: Previously titled "Let's Predict Sentence by Sentence"; Presented @ COLM RAM 2 Workshop (Oral)
💡 一句话要点
提出基于句子嵌入预测的潜在推理框架,提升语言模型的抽象推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 抽象推理 句子嵌入 自回归预测 表示学习
📋 核心要点
- 现有自回归语言模型在token级别生成,缺乏对句子、命题等高层抽象概念的直接推理能力。
- 论文提出一种基于句子嵌入预测的潜在推理框架,使语言模型能够在句子级别的抽象空间中进行推理。
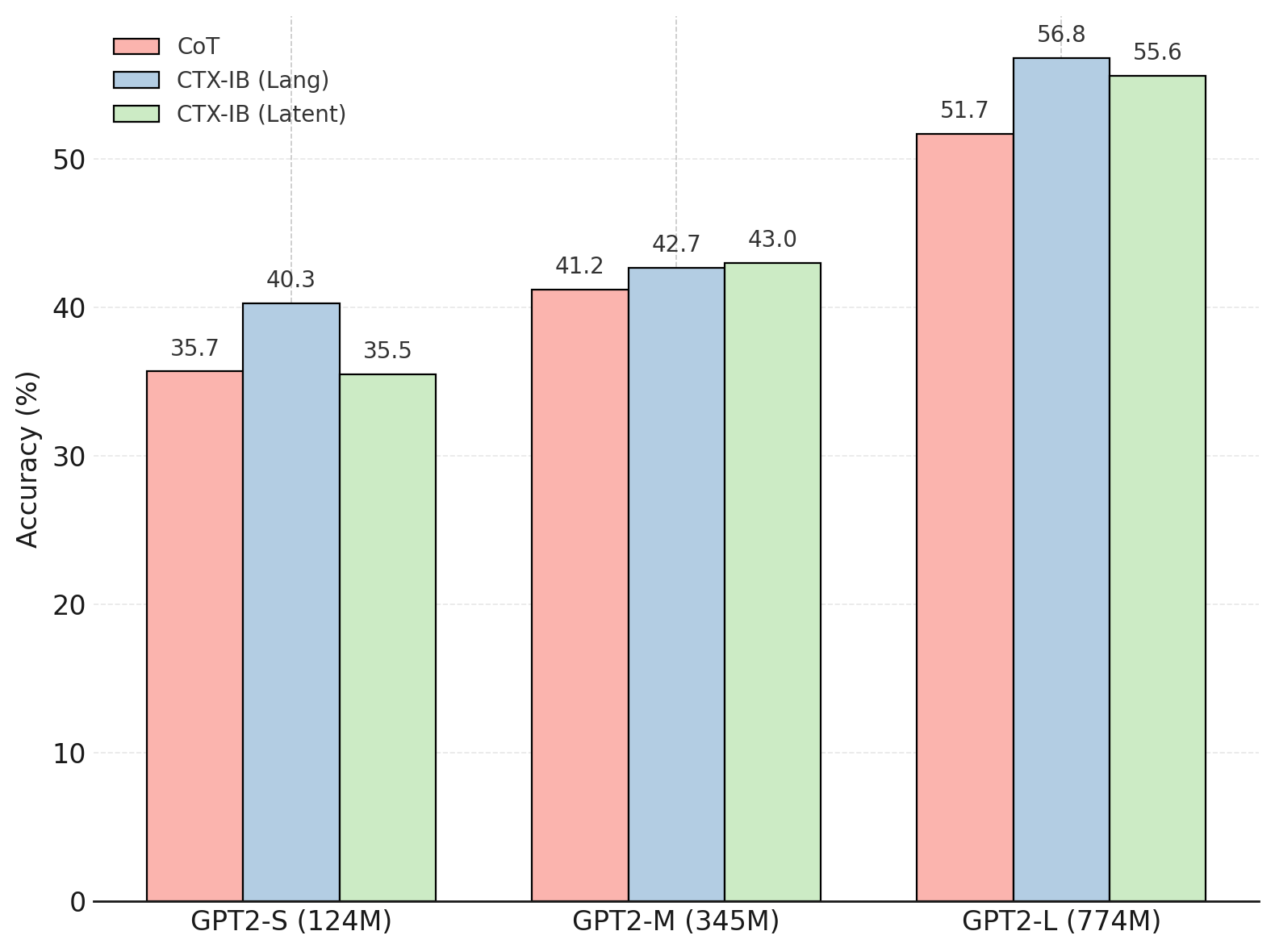
- 实验表明,该方法在多个领域表现出与思维链相当的性能,并显著降低了推理所需的计算资源。
📝 摘要(中文)
自回归语言模型一次生成一个token,而人类的推理则在高层次的抽象概念(句子、命题和概念)上进行。本文探讨了预训练语言模型是否可以通过构建其学习到的表示,提升到这种抽象的推理空间。我们提出了一个框架,通过自回归地预测下一个句子的连续嵌入,使预训练的token级语言模型适应于在句子空间中操作。我们探索了两种受经典表示学习启发的嵌入范式:1)语义嵌入,通过自编码学习以保留表面含义;2)上下文嵌入,通过下一句预测进行训练以编码预期结构。我们在两种推理模式下评估了这两种嵌入:离散化,在重新编码之前将每个预测的嵌入解码为文本;连续,完全在嵌入空间中进行推理以提高效率。在数学、逻辑、常识和规划四个领域中,连续推理下的上下文嵌入表现出与思维链(CoT)相当的性能,同时平均减少了一半的推理时间FLOPs。我们还展示了可扩展性和模块化适应的早期迹象。最后,为了可视化潜在轨迹,我们引入了SentenceLens,一种将中间模型状态解码为可解释句子的诊断工具。总之,我们的结果表明,预训练的语言模型可以有效地过渡到潜在嵌入空间中的抽象、结构化推理。
🔬 方法详解
问题定义:现有自回归语言模型主要在token级别进行操作,无法直接对句子、命题等高层次的语义单元进行推理。这限制了模型在需要复杂推理的任务中的表现,并且效率较低。现有方法,如思维链(Chain-of-Thought, CoT),虽然可以提升推理能力,但计算成本较高。
核心思路:论文的核心思路是将预训练语言模型提升到句子级别的抽象推理空间。通过让模型预测下一个句子的嵌入表示,而不是直接预测下一个token,模型可以学习到句子之间的关系和上下文信息,从而实现更高效和抽象的推理。
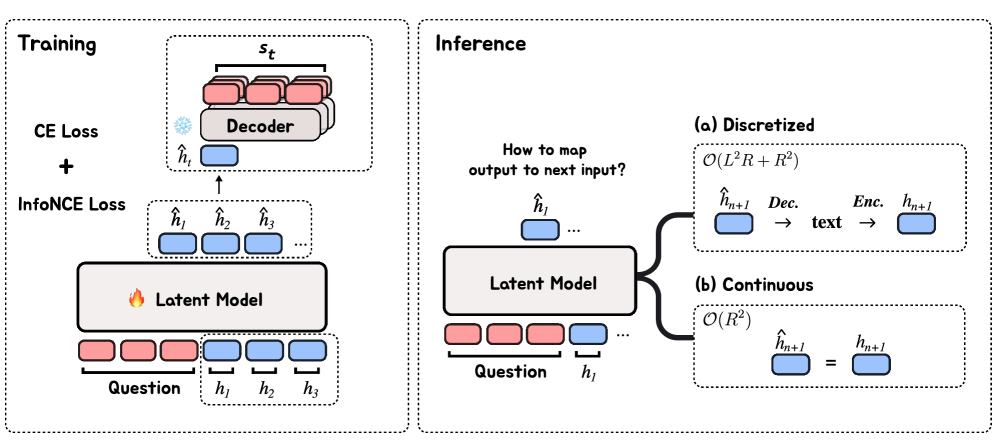
技术框架:该框架包含以下主要模块:1) 预训练的token级语言模型;2) 句子编码器,用于将句子编码为连续的嵌入表示;3) 自回归预测模块,用于预测下一个句子的嵌入表示;4) 解码器(可选),用于将预测的嵌入表示解码回文本。整体流程是:首先,使用句子编码器将输入句子编码为嵌入表示。然后,自回归预测模块根据当前句子的嵌入表示预测下一个句子的嵌入表示。最后,可以选择使用解码器将预测的嵌入表示解码回文本。
关键创新:该论文的关键创新在于将token级别的语言模型提升到句子级别的抽象推理空间,通过预测句子嵌入来实现推理。与传统的token级别推理相比,这种方法更加高效,并且能够更好地捕捉句子之间的关系。此外,论文还探索了两种不同的嵌入范式:语义嵌入和上下文嵌入,并提出了连续推理和离散化推理两种推理模式。
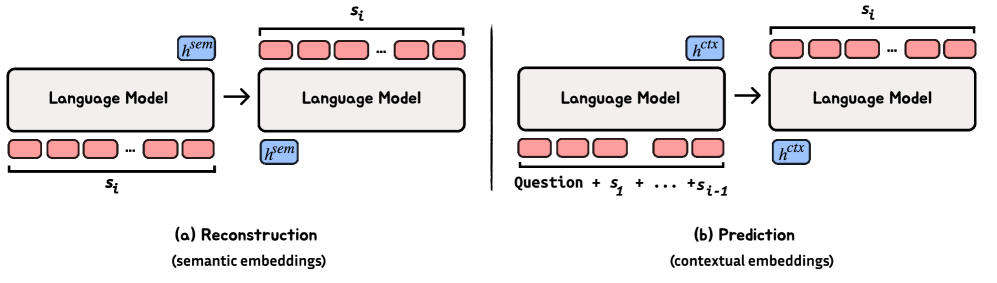
关键设计:论文探索了两种嵌入范式:语义嵌入(通过自编码器学习)和上下文嵌入(通过下一句预测学习)。自回归预测模块可以使用Transformer等结构。损失函数可以采用均方误差(MSE)等。在连续推理模式下,模型直接在嵌入空间中进行推理,避免了token级别的生成和解码,从而提高了效率。SentenceLens工具用于可视化潜在轨迹,帮助理解模型的推理过程。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在数学、逻辑、常识和规划四个领域中,使用上下文嵌入和连续推理的方法,可以达到与思维链(CoT)相当的性能,同时平均减少了一半的推理时间FLOPs。这表明该方法在提高推理效率方面具有显著优势。SentenceLens工具的可视化结果也为理解模型的推理过程提供了有价值的 insights。
🎯 应用场景
该研究成果可应用于需要复杂推理的自然语言处理任务,如数学问题求解、逻辑推理、常识推理和规划等。通过提高推理效率和抽象能力,可以使语言模型在这些任务中表现更好。此外,该方法还可以用于构建更智能的对话系统和智能助手,使其能够更好地理解用户的意图并进行推理。
📄 摘要(原文)
Autoregressive language models (LMs) generate one token at a time, yet human reasoning operates over higher-level abstractions - sentences, propositions, and concepts. This contrast raises a central question- Can LMs likewise learn to reason over structured semantic units rather than raw token sequences? In this work, we investigate whether pretrained LMs can be lifted into such abstract reasoning spaces by building on their learned representations. We present a framework that adapts a pretrained token-level LM to operate in sentence space by autoregressively predicting continuous embeddings of next sentences. We explore two embedding paradigms inspired by classical representation learning: 1) semantic embeddings, learned via autoencoding to preserve surface meaning; and 2) contextual embeddings, trained via next-sentence prediction to encode anticipatory structure. We evaluate both under two inference regimes: Discretized, which decodes each predicted embedding into text before re-encoding; and Continuous, which reasons entirely in embedding space for improved efficiency. Across four domains - mathematics, logic, commonsense, and planning - contextual embeddings under continuous inference show competitive performance with Chain-of-Thought (CoT) while reducing inference-time FLOPs on average by half. We also present early signs of scalability and modular adaptation. Finally, to visualize latent trajectories, we introduce SentenceLens, a diagnostic tool that decodes intermediate model states into interpretable sentences. Together, our results indicate that pretrained LMs can effectively transition to abstract, structured reasoning within latent embedding spaces.