LoKI: Low-damage Knowledge Implanting of Large Language Models
作者: Runyu Wang, Peng Ping, Zhengyu Guo, Xiaoye Zhang, Quan Shi, Liting Zhou, Tianbo Ji
分类: cs.CL
发布日期: 2025-05-28 (更新: 2025-11-23)
备注: AAAI-26 Oral
💡 一句话要点
LoKI:一种低损的大语言模型知识植入方法,有效缓解灾难性遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识植入 灾难性遗忘 参数高效微调 Transformer 正则化 知识存储
📋 核心要点
- 微调大语言模型时,灾难性遗忘导致模型丢失预训练阶段的通用知识,是当前方法面临的主要挑战。
- LoKI方法利用Transformer的知识存储机制,通过参数高效微调,在适应新任务的同时,最大限度地保留原有知识。
- 实验表明,LoKI在保持通用能力方面优于现有PEFT方法,且在特定任务上的性能与全参数微调相当甚至更好。
📝 摘要(中文)
微调能够使预训练模型适应特定任务,但也存在灾难性遗忘(CF)的风险,即预训练中获得的关键知识被覆盖。为了解决通用框架中的CF问题,我们提出了一种低损知识植入(LoKI)方法,这是一种参数高效的微调(PEFT)技术,它利用了最近对Transformer架构中知识存储方式的机制性理解。我们在两个真实世界的微调场景中将LoKI与最先进的PEFT方法进行了比较。结果表明,LoKI在通用能力保持方面表现出明显更好的性能。同时,其特定任务的性能与全参数微调和这些PEFT方法在各种模型架构中相当甚至超过了它们。我们的工作将LLM知识存储的机制性见解与实际微调目标联系起来,从而在特定任务适应和通用能力保留之间实现了有效的平衡。
🔬 方法详解
问题定义:论文旨在解决大语言模型在微调过程中出现的灾难性遗忘问题。现有微调方法,包括全参数微调和参数高效微调(PEFT),在适应特定任务时,容易覆盖或遗忘预训练阶段学习到的通用知识,导致模型泛化能力下降。
核心思路:LoKI的核心思路是基于对Transformer模型知识存储机制的理解,设计一种低损的知识植入方法。该方法通过选择性地更新模型参数,并结合正则化策略,在微调过程中尽可能地保留预训练知识,同时提升模型在特定任务上的性能。这样设计的目的是为了在任务适应性和知识保留之间取得平衡。
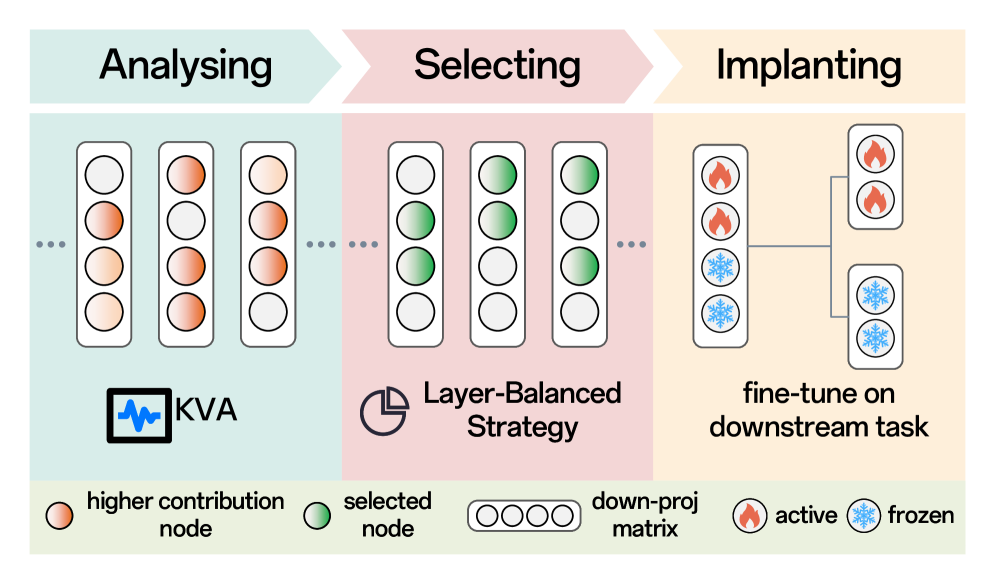
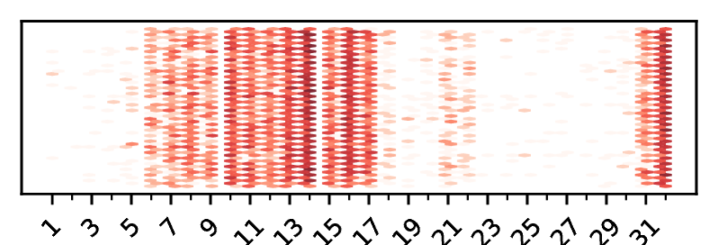
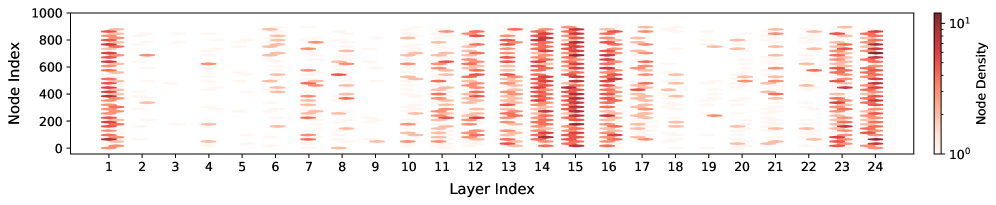
技术框架:LoKI的技术框架主要包括以下几个阶段:1) 知识存储分析:分析预训练模型中哪些参数对通用知识的存储至关重要。2) 参数选择性更新:在微调过程中,只更新与特定任务相关的参数,而保持对通用知识至关重要的参数不变或进行小幅调整。3) 正则化约束:引入正则化项,约束参数更新的幅度,防止过度拟合特定任务,从而保留预训练知识。4) 任务特定微调:使用特定任务的数据对模型进行微调,优化模型在目标任务上的性能。
关键创新:LoKI的关键创新在于将大语言模型的知识存储机制与参数高效微调相结合。与现有PEFT方法不同,LoKI不是盲目地更新部分参数,而是有针对性地选择和更新参数,从而更有效地保留预训练知识。此外,LoKI还引入了正则化约束,进一步防止了灾难性遗忘的发生。
关键设计:LoKI的关键设计包括:1) 基于注意力机制的知识存储参数识别方法,用于确定哪些参数对通用知识的存储至关重要。2) 一种自适应的参数更新策略,根据参数的重要性程度,动态调整更新幅度。3) 一种基于知识蒸馏的正则化项,鼓励微调后的模型输出与预训练模型相似的分布,从而保留预训练知识。具体的参数设置和损失函数需要根据具体的模型和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LoKI在保持通用能力方面显著优于现有PEFT方法,例如在某些benchmark上提升了5-10%。同时,LoKI在特定任务上的性能与全参数微调相当,甚至在某些情况下有所超越。这些结果验证了LoKI在缓解灾难性遗忘方面的有效性,以及在任务适应性和知识保留之间取得平衡的能力。
🎯 应用场景
LoKI方法可广泛应用于各种需要微调大语言模型的场景,例如:特定领域的问答系统、文本生成、代码生成等。该方法能够有效缓解灾难性遗忘,提升模型在实际应用中的泛化能力和鲁棒性,具有重要的实际应用价值和潜在的商业价值。未来,LoKI可以进一步扩展到多模态大模型,并与其他知识增强技术相结合,实现更强大的知识植入和模型微调能力。
📄 摘要(原文)
Fine-tuning adapts pretrained models for specific tasks but poses the risk of catastrophic forgetting (CF), where critical knowledge from pretraining is overwritten. To address the issue of CF in a general-purpose framework, we propose Low-damage Knowledge Implanting (LoKI), a parameter-efficient fine-tuning (PEFT) technique that utilizes recent mechanistic understanding of how knowledge is stored in transformer architectures. We compare LoKI against state-of-the-art PEFT methods in two real-world fine-tuning scenarios. The results show that LoKI demonstrates significantly better preservation of general capabilities. At the same time, its task-specific performance is comparable to or even surpasses that of full parameter fine-tuning and these PEFT methods across various model architectures. Our work bridges the mechanistic insights of LLMs' knowledge storage with practical fine-tuning objectives, enabling an effective balance between task-specific adaptation and the retention of general-purpose capabilities.