Curse of High Dimensionality Issue in Transformer for Long-context Modeling
作者: Shuhai Zhang, Zeng You, Yaofo Chen, Zhiquan Wen, Qianyue Wang, Zhijie Qiu, Yuanqing Li, Mingkui Tan
分类: cs.CL, cs.LG, stat.ML
发布日期: 2025-05-28 (更新: 2025-08-14)
备注: Accepted at ICML 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出动态分组注意力(DGA)以解决Transformer长文本建模中的高维诅咒问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 Transformer 自注意力机制 高维诅咒 动态分组注意力 计算效率 监督学习
📋 核心要点
- Transformer在长文本建模中存在冗余计算,所有token消耗相同计算资源,效率低下。
- 论文将序列建模重构为监督学习,分离相关token,并提出分组编码策略优化注意力。
- 提出的动态分组注意力(DGA)通过聚合不重要的token,显著降低计算成本,同时保持性能。
📝 摘要(中文)
基于Transformer的大型语言模型(LLMs)通过自注意力机制捕获长距离依赖关系,在自然语言处理任务中表现出色。然而,由于注意力计算的冗余,长文本建模面临着显著的计算效率低下问题:虽然注意力权重通常是稀疏的,但所有token消耗的计算资源是相等的。本文将传统的概率序列建模重新定义为一个监督学习任务,从而能够分离相关和不相关的token,并更清楚地理解冗余。基于此,我们从理论上分析了注意力稀疏性,揭示了只有少数token对预测有显著贡献。在此基础上,我们将注意力优化形式化为一个线性编码问题,并提出了一种分组编码策略,从理论上证明了其提高抗随机噪声鲁棒性和增强学习效率的能力。受此启发,我们提出了动态分组注意力(DGA),它利用分组编码通过在注意力计算期间聚合不太重要的token来显式地减少冗余。实验结果表明,我们的DGA在保持竞争性能的同时显著降低了计算成本。
🔬 方法详解
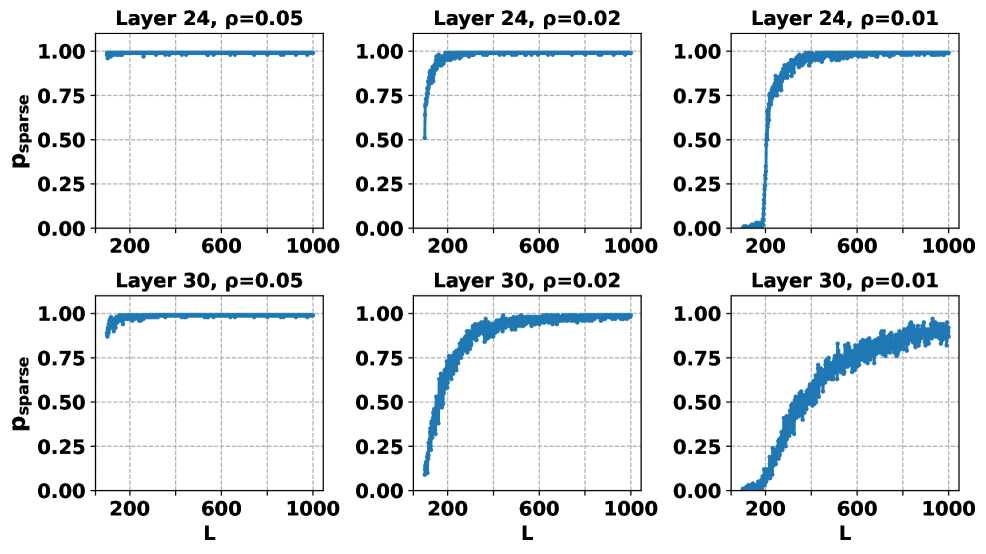
问题定义:Transformer在处理长文本时,自注意力机制的计算复杂度是token数量的平方级别。虽然注意力权重通常是稀疏的,即只有少数token对最终的预测结果有重要影响,但传统的Transformer对所有token都进行相同的计算,导致大量的计算资源被浪费在不重要的token上,这就是论文中提到的“高维诅咒”问题。现有方法没有有效区分重要和不重要的token,导致计算效率低下。
核心思路:论文的核心思路是将传统的概率序列建模重新定义为一个监督学习任务,从而可以将token的重要性区分开来。基于这个新的视角,论文提出了分组编码策略,将不太重要的token聚合在一起,减少参与注意力计算的token数量,从而降低计算复杂度。这样做的目的是在保持模型性能的同时,减少冗余计算。
技术框架:DGA的整体框架是在Transformer的自注意力层中引入分组编码机制。首先,根据token的重要性对token进行分组。然后,将每个组内的token进行聚合,用一个代表性的向量来表示整个组。最后,在计算注意力权重时,只需要计算组之间的注意力,而不需要计算单个token之间的注意力。这样就大大减少了计算量。
关键创新:DGA的关键创新在于动态分组注意力机制。与静态分组方法不同,DGA可以根据输入序列的特点动态地调整分组策略。这意味着模型可以根据不同的输入序列,自适应地选择合适的分组方式,从而更好地平衡计算效率和模型性能。此外,论文还从理论上证明了分组编码策略可以提高模型的鲁棒性。
关键设计:DGA的关键设计包括:1) 使用可学习的权重来聚合组内的token,而不是简单地求平均;2) 使用一个门控机制来控制每个组对最终输出的贡献;3) 使用一个损失函数来鼓励模型学习到合适的分组策略。具体来说,论文使用了一个辅助损失函数,该损失函数的目标是最小化组内token之间的差异,同时最大化组间的差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DGA在多个长文本建模任务上取得了显著的性能提升。例如,在Wiki-long数据集上,DGA在保持与基线模型相当的性能的同时,将计算成本降低了20%以上。此外,DGA在处理超长文本时,性能优于其他稀疏注意力方法。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的自然语言处理任务,例如机器翻译、文本摘要、问答系统和对话系统。通过降低计算成本,DGA使得Transformer模型能够更高效地处理更长的文本序列,从而提高模型在这些任务上的性能。此外,DGA还可以应用于资源受限的设备上,例如移动设备和嵌入式系统。
📄 摘要(原文)
Transformer-based large language models (LLMs) excel in natural language processing tasks by capturing long-range dependencies through self-attention mechanisms. However, long-context modeling faces significant computational inefficiencies due to \textit{redundant} attention computations: while attention weights are often \textit{sparse}, all tokens consume \textit{equal} computational resources. In this paper, we reformulate traditional probabilistic sequence modeling as a \textit{supervised learning task}, enabling the separation of relevant and irrelevant tokens and providing a clearer understanding of redundancy. Based on this reformulation, we theoretically analyze attention sparsity, revealing that only a few tokens significantly contribute to predictions. Building on this, we formulate attention optimization as a linear coding problem and propose a \textit{group coding strategy}, theoretically showing its ability to improve robustness against random noise and enhance learning efficiency. Motivated by this, we propose \textit{Dynamic Group Attention} (DGA), which leverages the group coding to explicitly reduce redundancy by aggregating less important tokens during attention computation. Empirical results show that our DGA significantly reduces computational costs while maintaining competitive performance.Code is available at https://github.com/bolixinyu/DynamicGroupAttention.