ArgInstruct: Specialized Instruction Fine-Tuning for Computational Argumentation
作者: Maja Stahl, Timon Ziegenbein, Joonsuk Park, Henning Wachsmuth
分类: cs.CL
发布日期: 2025-05-28
💡 一句话要点
ArgInstruct:面向计算论证的专用指令微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算论证 指令微调 大型语言模型 自然语言处理 领域专用 自指令学习
📋 核心要点
- 现有指令跟随LLM在处理需要领域知识的任务时面临挑战,尤其是在计算论证领域。
- 本文提出CA专用指令微调方法,通过构建CA任务指令集并微调LLM,提升其在CA领域的性能。
- 实验表明,该方法显著提升LLM在CA任务上的表现,同时保持其在通用NLP任务上的性能。
📝 摘要(中文)
本文提出了一种针对计算论证(CA)领域的专用指令微调方法,旨在提升大型语言模型(LLM)处理CA任务的能力,同时保持其通用性。通过回顾现有的CA研究,作者为105个CA任务设计了自然语言指令。在此基础上,构建了一个CA专用基准,用于全面评估LLM解决各种CA任务的能力。作者合成了52k个与CA相关的指令,并调整了self-instruct过程,以训练一个CA专用指令跟随LLM。实验结果表明,CA专用指令微调显著提高了LLM在已见和未见CA任务上的性能,同时保持了在SuperNI通用NLP任务上的性能。
🔬 方法详解
问题定义:现有的大型语言模型在处理计算论证(CA)任务时,虽然具备一定的泛化能力,但由于缺乏领域知识,性能往往不尽如人意。现有的方法难以有效地将通用语言模型的知识迁移到特定的CA任务中,导致模型在处理复杂的论证结构和推理时表现不足。
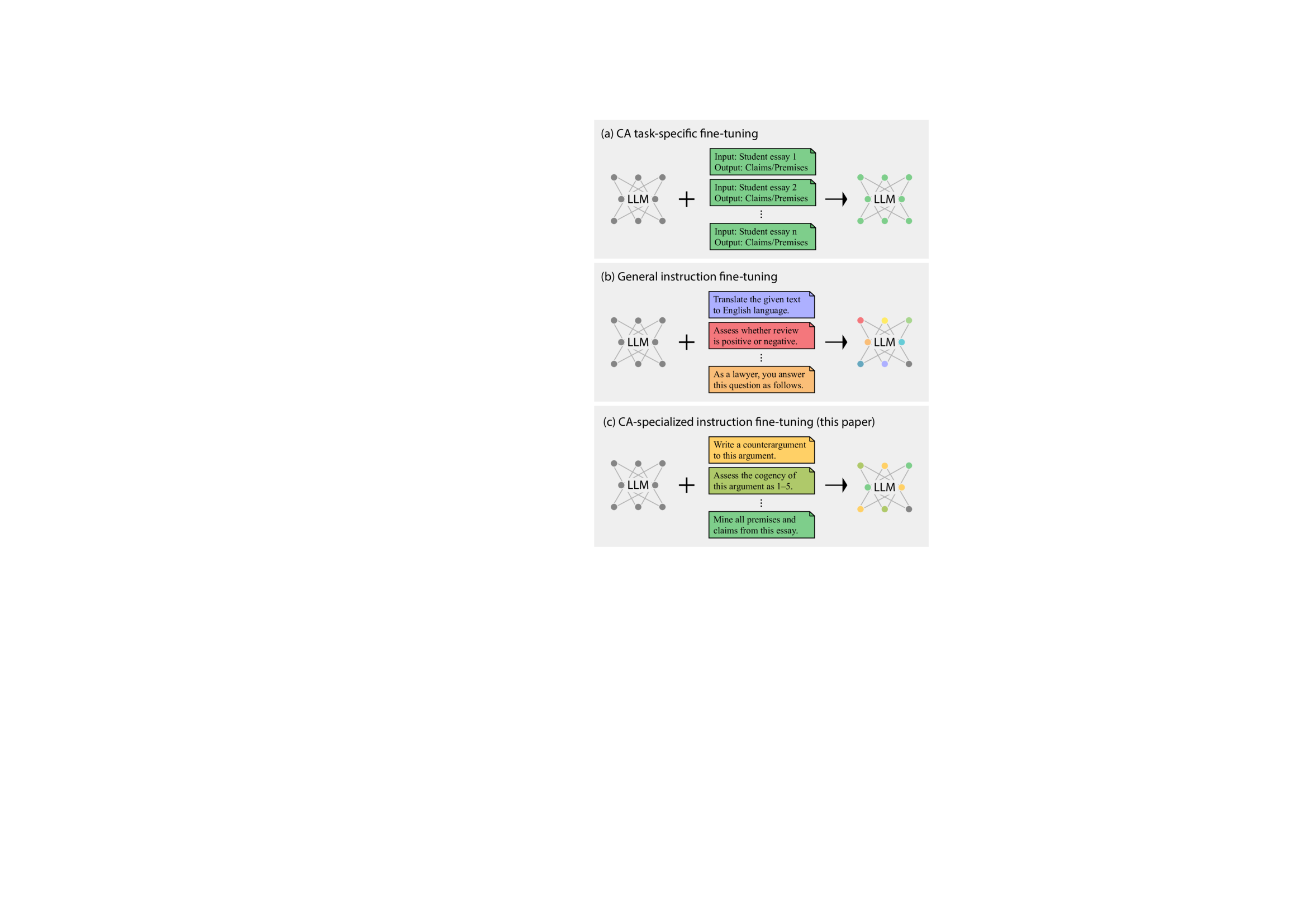
核心思路:本文的核心思路是利用指令微调(Instruction Fine-tuning)的方法,使LLM能够更好地理解和执行CA任务。通过构建一个包含大量CA任务指令的数据集,并对LLM进行微调,使其能够学习到CA领域的特定知识和推理模式。这样,LLM就能更好地处理各种CA任务,并提高其性能。
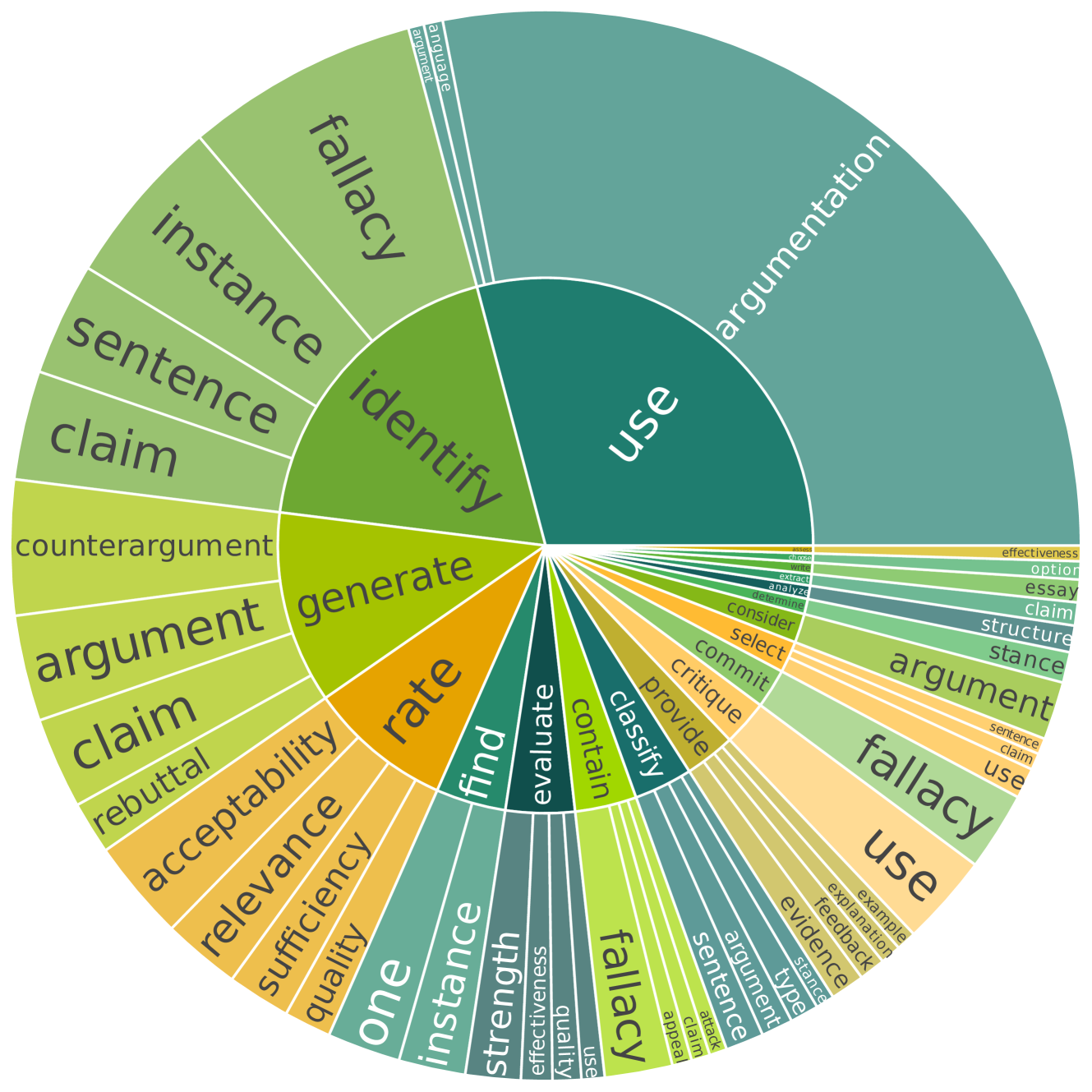
技术框架:整体框架包括以下几个主要步骤:1) 任务定义与指令构建:回顾现有CA研究,定义105个CA任务,并为每个任务设计自然语言指令。2) 数据合成:基于定义的任务和指令,利用self-instruct方法合成52k个CA相关指令。3) 模型微调:使用合成的CA指令数据对LLM进行微调,得到CA专用指令跟随LLM。4) 基准测试与评估:构建CA专用基准,评估微调后的LLM在已见和未见CA任务上的性能,并与通用NLP基准进行对比。
关键创新:该方法最重要的创新在于针对计算论证领域进行了专门的指令微调。与通用的指令微调方法不同,本文专注于CA领域,构建了专门的CA任务指令集,并针对性地训练LLM。这种领域专用微调能够更有效地提升LLM在CA任务上的性能。
关键设计:在数据合成阶段,采用了self-instruct方法,通过迭代的方式生成更多的CA相关指令。在模型微调阶段,使用了标准的指令微调流程,并针对CA任务的特点进行了一些调整。具体的参数设置和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CA专用指令微调显著提高了LLM在已见和未见CA任务上的性能。具体来说,在CA专用基准测试中,微调后的LLM在多个CA任务上取得了显著的性能提升。同时,该方法保持了LLM在SuperNI通用NLP任务上的性能,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于自动论证挖掘、论证评估、论证生成等多个领域。例如,可以利用该模型自动分析文本中的论证结构,评估论证的质量,或者生成具有说服力的论证文本。该研究有助于提高自动化论证系统的性能,并促进人机协作在论证领域的应用。
📄 摘要(原文)
Training large language models (LLMs) to follow instructions has significantly enhanced their ability to tackle unseen tasks. However, despite their strong generalization capabilities, instruction-following LLMs encounter difficulties when dealing with tasks that require domain knowledge. This work introduces a specialized instruction fine-tuning for the domain of computational argumentation (CA). The goal is to enable an LLM to effectively tackle any unseen CA tasks while preserving its generalization capabilities. Reviewing existing CA research, we crafted natural language instructions for 105 CA tasks to this end. On this basis, we developed a CA-specific benchmark for LLMs that allows for a comprehensive evaluation of LLMs' capabilities in solving various CA tasks. We synthesized 52k CA-related instructions, adapting the self-instruct process to train a CA-specialized instruction-following LLM. Our experiments suggest that CA-specialized instruction fine-tuning significantly enhances the LLM on both seen and unseen CA tasks. At the same time, performance on the general NLP tasks of the SuperNI benchmark remains stable.