The Price of a Second Thought: On the Evaluation of Reasoning Efficiency in Large Language Models
作者: Siqi Fan, Bowen Qin, Peng Han, Shuo Shang, Yequan Wang, Aixin Sun
分类: cs.CL
发布日期: 2025-05-28 (更新: 2025-10-14)
备注: Added new experiments and revised the manuscript for clarity
💡 一句话要点
提出COTHINK:一种提升大语言模型推理效率的框架,降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理效率 思维模型 指令模型 计算成本
📋 核心要点
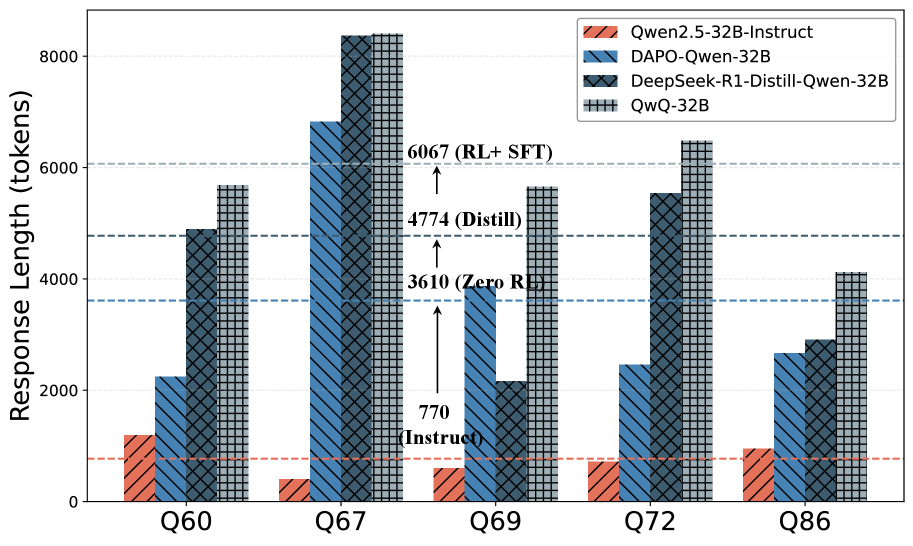
- 现有思维模型在简单问题上过度推理,导致计算资源浪费,而现有评估方法未能充分考虑问题难度和中间计算成本。
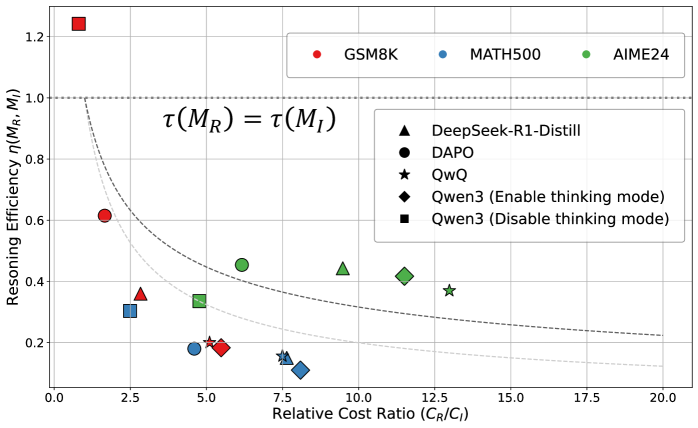
- 论文提出将推理效率定义为思维模型相对于指令模型的相对度量,指令模型作为基线,以此来评估推理效率。
- 实验结果表明,指令模型效率更高,且问题难度影响效率。基于此,提出了COTHINK框架,显著降低了token使用量。
📝 摘要(中文)
本文关注到,通过强化学习和反向检查CoT训练的思维模型,在简单问题上过度思考,浪费计算资源。现有基于token效率的评估方法不完整,忽略了问题难度和中间计算成本。论文将推理效率形式化为思维模型相对于指令模型的相对度量,并将指令模型视为最小努力的基线。对四个思维模型和多个基准的系统研究表明:(i) 指令模型总体上效率更高;(ii) 问题难度影响效率,思维模型在简单问题上浪费计算,但在较难问题上提供价值。基于此,论文提出COTHINK,一个简单的两阶段流程:指令模型起草简要大纲,思维模型扩展它。在GSM8K、MATH500和AIME24上,COTHINK在保持四个思维模型准确性的同时,减少了21.1%的token使用量,并且与强大的效率基线相比仍具有竞争力。
🔬 方法详解
问题定义:现有的大语言模型,特别是那些使用强化学习或反向检查CoT(Chain-of-Thought)训练的“思维模型”,在解决简单问题时常常表现出“过度思考”的现象。这意味着它们会生成过长的输出,即使对于可以直接回答的问题也是如此,从而导致不必要的计算资源浪费。现有的评估方法,例如基于token效率的评估,无法全面衡量推理效率,因为它们忽略了问题本身的难度以及中间计算步骤的成本。
核心思路:论文的核心思路是将推理效率定义为一种相对度量,即思维模型相对于指令模型的效率。指令模型被视为“最小努力”的基线,因为它直接尝试回答问题而不进行复杂的推理过程。通过比较思维模型和指令模型在相同问题上的表现,可以更准确地评估思维模型的推理效率。如果思维模型在简单问题上花费了大量的计算资源,而指令模型能够以更少的资源获得相同或更好的结果,那么就可以认为思维模型的效率较低。
技术框架:论文提出的COTHINK框架是一个两阶段的流程:第一阶段,使用一个指令模型(Instruct Model)来生成一个简要的大纲,这个大纲是对问题解决思路的初步规划。第二阶段,使用一个思维模型(Thinking Model)来扩展这个大纲,生成最终的答案。这个框架旨在利用指令模型的高效性和思维模型的推理能力,从而在保证准确性的同时,降低计算成本。
关键创新:COTHINK的关键创新在于其两阶段的设计,它将问题解决过程分解为大纲生成和内容扩展两个步骤,并分别由不同的模型来完成。这种分解使得可以针对不同的步骤选择最合适的模型,从而优化整体的推理效率。与传统的思维模型相比,COTHINK避免了在简单问题上进行不必要的复杂推理,从而节省了计算资源。
关键设计:COTHINK框架的关键设计在于如何有效地利用指令模型生成的大纲。大纲的质量直接影响到思维模型的推理效率和最终答案的准确性。论文中可能涉及如何设计指令模型,如何生成高质量的大纲,以及如何将大纲有效地传递给思维模型等技术细节。此外,如何平衡两个阶段的计算资源分配,以及如何选择合适的指令模型和思维模型,也是需要考虑的关键设计因素。具体的参数设置、损失函数和网络结构等细节信息未知,需要查阅原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,COTHINK框架在GSM8K、MATH500和AIME24等基准测试中,能够在保持准确性的前提下,将token使用量降低21.1%。与现有的效率基线相比,COTHINK也表现出具有竞争力的性能。这些结果表明,COTHINK是一种有效的提高大语言模型推理效率的方法。
🎯 应用场景
该研究成果可应用于各种需要大语言模型进行推理的场景,例如数学问题求解、代码生成、知识问答等。通过提高推理效率,可以降低计算成本,使得大语言模型能够更广泛地部署在资源受限的环境中。此外,该研究也有助于更好地理解大语言模型的推理过程,为未来的模型设计提供指导。
📄 摘要(原文)
Recent thinking models trained with reinforcement learning and backward-checking CoT often suffer from overthinking: they produce excessively long outputs even on simple problems, wasting computation. Existing evaluations, based on token efficiency, give an incomplete view as they neglect problem difficulty and intermediate computation costs. We formalize reasoning efficiency as a relative measure between thinking and instruct models, treating instruct models as the minimal-effort baseline. A systematic study across four thinking models and multiple benchmarks reveals two consistent patterns: (i) instruct models achieve higher efficiency overall, and (ii) problem difficulty affects efficiency, with thinking models wasting computation on easy problems but providing value on harder ones. Building on this insight, we propose COTHINK, a simple two-stage pipeline: an instruct model drafts a brief outline, and a thinking model expands it. On GSM8K, MATH500, and AIME24, COTHINK cuts token usage by 21.1% while keeping accuracy on four thinking models, and remains competitive with strong efficiency baselines.