A Course Correction in Steerability Evaluation: Revealing Miscalibration and Side Effects in LLMs
作者: Trenton Chang, Tobias Schnabel, Adith Swaminathan, Jenna Wiens
分类: cs.CL, cs.LG
发布日期: 2025-05-27 (更新: 2026-01-17)
备注: 8 pages, 6 figures. 26 pages of references and supplementary material, 22 additional figures. Association for the Advancement of Artificial Intelligence Conference (AAAI 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
提出多维目标空间框架,揭示LLM可控性评估中的校准误差和副作用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可控性评估 多维目标空间 文本属性 副作用 提示工程 强化学习微调
📋 核心要点
- 现有LLM评估基准偏向常见请求,且标量指标难以揭示开放式生成中的行为变化,导致可控性评估不足。
- 论文提出多维目标空间框架,将用户目标和LLM输出建模为带文本属性维度的向量,从而更全面地评估可控性。
- 实验表明,现有LLM在文本重写任务中存在副作用,即使采用提示工程等干预措施也难以完全消除。
📝 摘要(中文)
尽管大型语言模型(LLM)在推理和指令遵循任务上取得了进展,但它们是否能可靠地产生与各种用户目标对齐的输出尚不清楚,这被称为可控性。当前LLM评估存在两个差距阻碍了可控性评估:(1)许多基准建立在过去的LLM聊天和互联网抓取的文本上,这可能偏向于常见请求;(2)先前工作中常见的标量性能指标可能会掩盖开放式生成中LLM输出的行为变化。因此,我们引入了一个基于多维目标空间的框架,该框架将用户目标和LLM输出建模为向量,其维度对应于文本属性(例如,阅读难度)。应用于文本重写任务,我们发现当前的LLM会引起对文本属性的意外更改或副作用,从而阻碍了可控性。诸如提示工程、best-of-N采样和强化学习微调等改善可控性的干预措施具有不同的有效性,但副作用仍然存在问题。我们的发现表明,即使是强大的LLM也在可控性方面存在困难,并且现有的对齐策略可能不足。我们在https://github.com/MLD3/steerability 上开源了我们的可控性评估框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的可控性评估问题。现有评估方法主要存在两个痛点:一是评估数据集存在偏差,倾向于常见请求;二是评估指标过于简单,无法捕捉LLM输出的细微变化和副作用。因此,需要一种更全面、更细致的评估框架来衡量LLM是否能够按照用户意图进行输出控制。
核心思路:论文的核心思路是将用户目标和LLM的输出都表示为多维向量,向量的每个维度对应于文本的特定属性(例如,阅读难度、情感倾向等)。通过比较目标向量和输出向量之间的差异,可以更准确地评估LLM的可控性,并发现潜在的副作用。这种方法避免了使用单一标量指标可能造成的信息损失。
技术框架:该框架主要包含以下几个步骤:1)定义多维目标空间,确定需要评估的文本属性;2)将用户目标表示为目标向量,指定每个属性的期望值;3)使用LLM生成文本,并将LLM的输出表示为输出向量;4)计算目标向量和输出向量之间的距离,以及其他相关指标,评估LLM的可控性和副作用。该框架提供了一个开源的可控性评估工具。
关键创新:论文最重要的创新在于提出了多维目标空间的概念,并将其应用于LLM的可控性评估。与传统的标量指标相比,多维目标空间能够更全面地捕捉LLM输出的细微变化和副作用,从而更准确地评估LLM的可控性。这种方法为LLM的对齐和控制提供了新的思路。
关键设计:在实验中,论文选择了文本重写任务作为评估场景,并使用了阅读难度、情感倾向等文本属性作为目标空间的维度。论文还尝试了不同的干预措施,如提示工程、best-of-N采样和强化学习微调,以提高LLM的可控性。具体参数设置和损失函数等细节在论文中有详细描述,但此处不一一赘述。
🖼️ 关键图片
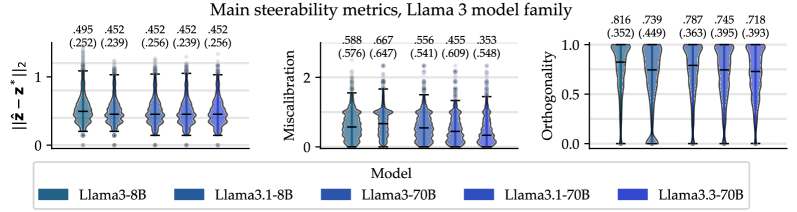
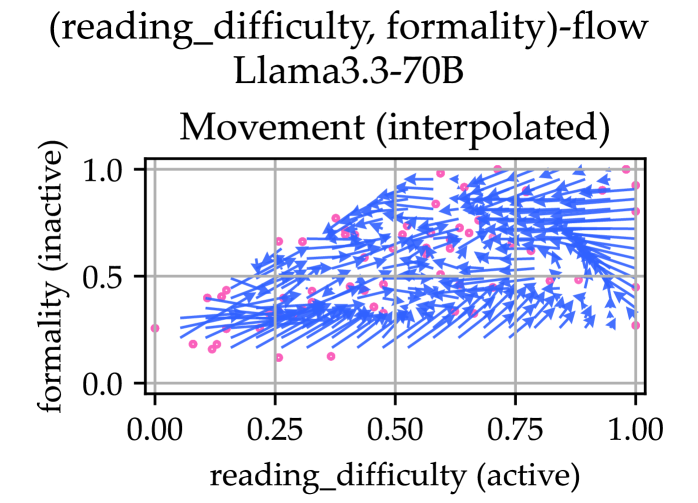
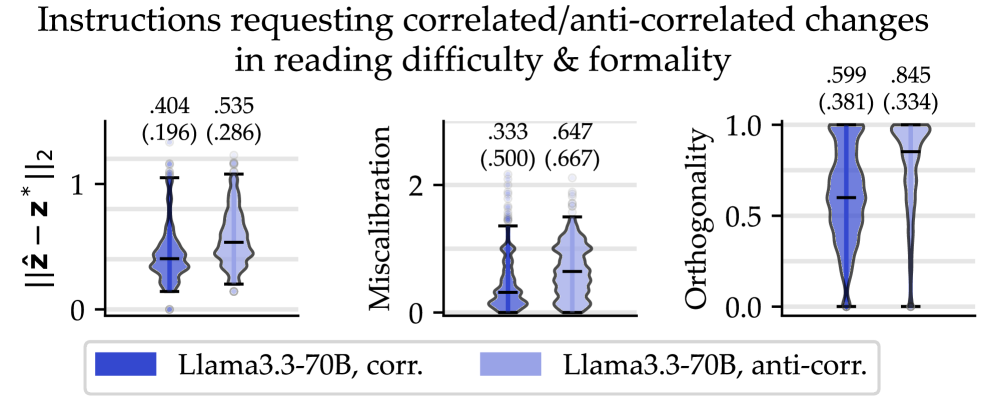
📊 实验亮点
实验结果表明,即使是强大的LLM在文本重写任务中也难以完全避免副作用,例如在调整文本情感倾向时,可能会意外改变其阅读难度。此外,不同的干预措施(如提示工程、best-of-N采样和强化学习微调)在提高可控性方面的效果各不相同,但都无法完全消除副作用。这些发现表明,现有的对齐策略可能不足以解决LLM的可控性问题。
🎯 应用场景
该研究成果可应用于各种需要精确控制LLM输出的场景,例如内容生成、文本摘要、机器翻译等。通过使用该框架,开发者可以更好地评估和改进LLM的可控性,从而使其能够更好地满足用户需求,并避免产生不必要的副作用。该研究还有助于推动LLM对齐和安全性的研究。
📄 摘要(原文)
Despite advances in large language models (LLMs) on reasoning and instruction-following tasks, it is unclear whether they can reliably produce outputs aligned with a variety of user goals, a concept called steerability. Two gaps in current LLM evaluation impede steerability evaluation: (1) many benchmarks are built with past LLM chats and Internet-scraped text, which may skew towards common requests, and (2) scalar measures of performance common in prior work could conceal behavioral shifts in LLM outputs in open-ended generation. Thus, we introduce a framework based on a multi-dimensional goal-space that models user goals and LLM outputs as vectors with dimensions corresponding to text attributes (e.g., reading difficulty). Applied to a text-rewriting task, we find that current LLMs induce unintended changes or side effects to text attributes, impeding steerability. Interventions to improve steerability, such as prompt engineering, best-of-N sampling, and reinforcement learning fine-tuning, have varying effectiveness but side effects remain problematic. Our findings suggest that even strong LLMs struggle with steerability, and existing alignment strategies may be insufficient. We open-source our steerability evaluation framework at https://github.com/MLD3/steerability.