LayerIF: Estimating Layer Quality for Large Language Models using Influence Functions
作者: Hadi Askari, Shivanshu Gupta, Fei Wang, Anshuman Chhabra, Muhao Chen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2025-10-24)
备注: Neurips 2025
💡 一句话要点
LayerIF:利用影响函数估计大语言模型各层训练质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 影响函数 层级重要性 模型剪枝 LoRA-MoE 任务特定 数据驱动
📋 核心要点
- 现有方法在评估LLM层级质量时,过度依赖模型本身的信息,忽略了训练数据对各层影响的差异。
- LayerIF利用影响函数,通过计算各层梯度对训练样本的敏感度,实现数据驱动的层级重要性评估。
- 实验表明,LayerIF指导的层级分配策略,在LoRA-MoE和LLM剪枝等下游任务中,能稳定提升模型性能。
📝 摘要(中文)
预训练大语言模型(LLMs)在各种任务中表现出色,但各层在特定下游应用上的训练质量存在显著差异,限制了其下游性能。因此,以一种既考虑模型架构又考虑训练数据的方式来估计层级的训练质量至关重要。现有的方法主要依赖于以模型为中心的启发式方法(如谱统计、异常值检测或均匀分配),而忽略了数据的影响。为了解决这些局限性,我们提出了LayerIF,一个数据驱动的框架,它利用影响函数来量化LLM中各个层的训练质量,并以任务敏感的方式进行。通过隔离每一层的梯度,并通过计算层级影响来测量验证损失对训练样本的敏感性,我们推导出数据驱动的层重要性估计。值得注意的是,我们的方法为同一个LLM生成特定于任务的层重要性估计,揭示了各层如何专门用于不同的测试时评估任务。我们通过将我们的分数用于两个下游应用来证明其效用:(a) LoRA-MoE架构中的专家分配和(b) LLM剪枝的层级稀疏性分布。跨多个LLM架构的实验表明,我们的模型无关的、影响引导的分配导致了任务性能的持续提升。
🔬 方法详解
问题定义:现有的大语言模型虽然强大,但其不同层在训练过程中对不同任务的贡献程度不同。简单地将所有层都用于特定任务,或者采用模型无关的启发式方法来选择层,无法充分利用模型的潜力。现有方法忽略了训练数据对各层影响的差异,导致层级重要性评估不准确。
核心思路:LayerIF的核心思想是利用影响函数来量化每个训练样本对模型各层的影响。通过计算验证损失对训练样本的敏感度,可以估计每个层对特定任务的训练质量。这种方法是数据驱动的,能够捕捉到不同层对不同任务的专业化程度。
技术框架:LayerIF框架主要包含以下几个步骤:1) 针对特定任务,计算LLM各层的梯度。2) 使用影响函数,计算每个训练样本对各层验证损失的影响。3) 基于计算出的影响值,估计各层的重要性。4) 将层重要性信息用于下游任务,例如LoRA-MoE架构中的专家分配或LLM剪枝中的层级稀疏性分布。
关键创新:LayerIF的关键创新在于其数据驱动的层级重要性评估方法。与传统的模型驱动方法不同,LayerIF利用影响函数,直接从训练数据中学习各层的重要性。这种方法能够捕捉到不同层对不同任务的专业化程度,从而实现更有效的模型优化。
关键设计:LayerIF的关键设计包括:1) 使用二阶导数近似计算影响函数,以提高计算效率。2) 针对不同的下游任务,设计不同的层重要性分配策略。例如,在LoRA-MoE中,将更重要的层分配给更专业的专家;在LLM剪枝中,对不重要的层进行更激进的剪枝。
🖼️ 关键图片


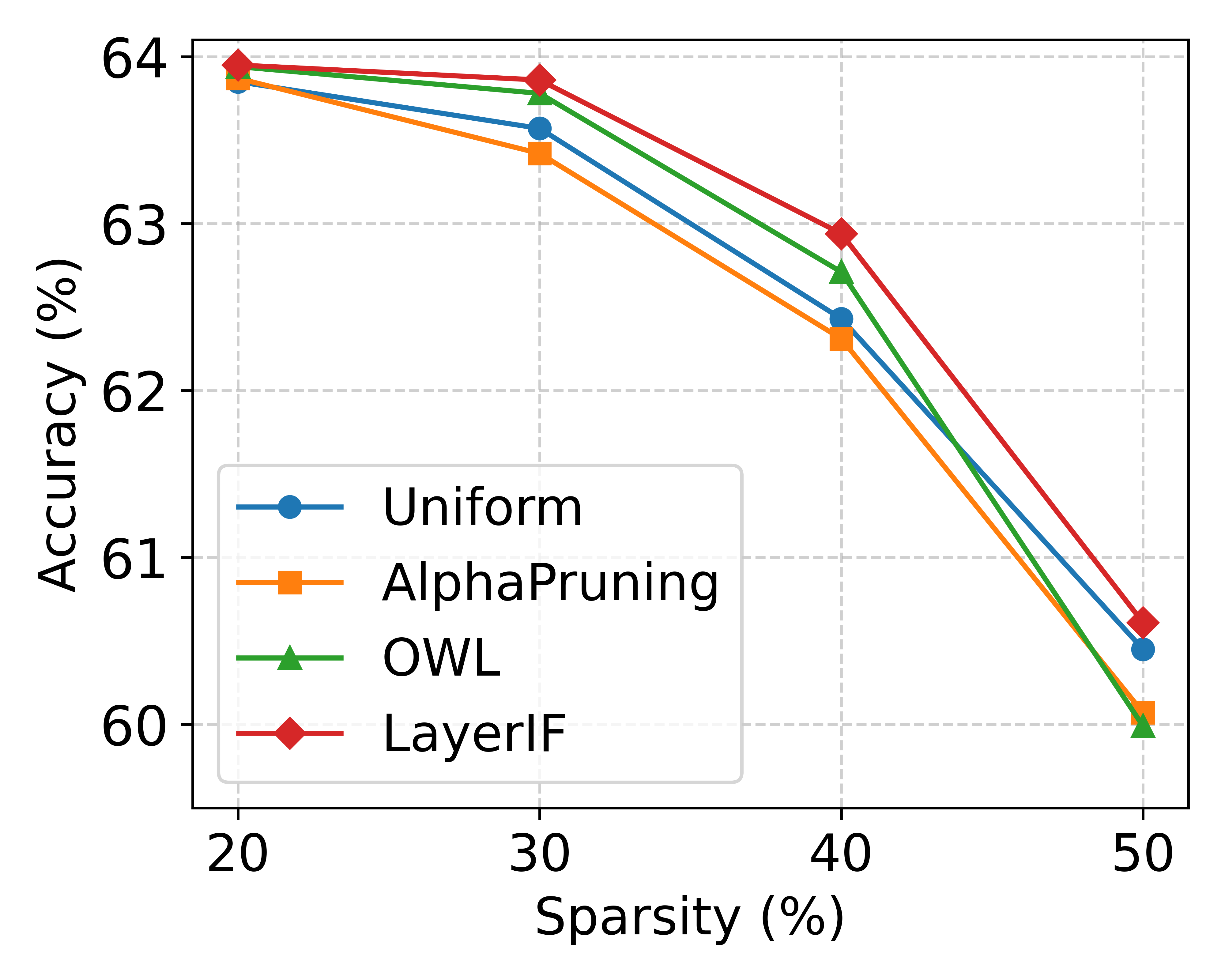
📊 实验亮点
实验结果表明,LayerIF在LoRA-MoE架构中,能够显著提升模型在多个任务上的性能。例如,在某些任务上,LayerIF指导的专家分配策略相比基线方法,性能提升超过2%。此外,LayerIF在LLM剪枝中也表现出色,能够在保证模型性能的同时,大幅减小模型的大小。
🎯 应用场景
LayerIF具有广泛的应用前景,可用于优化大语言模型的部署和微调。例如,可以利用LayerIF指导LoRA-MoE架构中的专家分配,提高模型的效率和性能。此外,LayerIF还可以用于LLM剪枝,在保证模型性能的同时,减小模型的大小,降低部署成本。该研究有助于推动大语言模型在资源受限环境下的应用。
📄 摘要(原文)
Pretrained Large Language Models (LLMs) achieve strong performance across a wide range of tasks, yet exhibit substantial variability in the various layers' training quality with respect to specific downstream applications, limiting their downstream performance. It is therefore critical to estimate layer-wise training quality in a manner that accounts for both model architecture and training data. However, existing approaches predominantly rely on model-centric heuristics (such as spectral statistics, outlier detection, or uniform allocation) while overlooking the influence of data. To address these limitations, we propose LayerIF, a data-driven framework that leverages Influence Functions to quantify the training quality of individual layers in a principled and task-sensitive manner. By isolating each layer's gradients and measuring the sensitivity of the validation loss to training examples by computing layer-wise influences, we derive data-driven estimates of layer importance. Notably, our method produces task-specific layer importance estimates for the same LLM, revealing how layers specialize for different test-time evaluation tasks. We demonstrate the utility of our scores by leveraging them for two downstream applications: (a) expert allocation in LoRA-MoE architectures and (b) layer-wise sparsity distribution for LLM pruning. Experiments across multiple LLM architectures demonstrate that our model-agnostic, influence-guided allocation leads to consistent gains in task performance.