Calibrating LLMs for Text-to-SQL Parsing by Leveraging Sub-clause Frequencies
作者: Terrance Liu, Shuyi Wang, Daniel Preotiuc-Pietro, Yash Chandarana, Chirag Gupta
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2025-09-17)
备注: EMNLP 2025 main conference
💡 一句话要点
提出基于子句频率的LLM校准方法,提升Text-to-SQL解析的置信度评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大型语言模型 置信度校准 子句频率 多元Platt scaling
📋 核心要点
- 现有Text-to-SQL方法在置信度评估方面存在不足,LLM有时会给出自信但错误的答案,缺乏可靠的不确定性度量。
- 论文提出利用SQL查询的结构化特性,通过子句频率(SCF)分数来提供更细粒度的正确性信号,提升置信度校准的准确性。
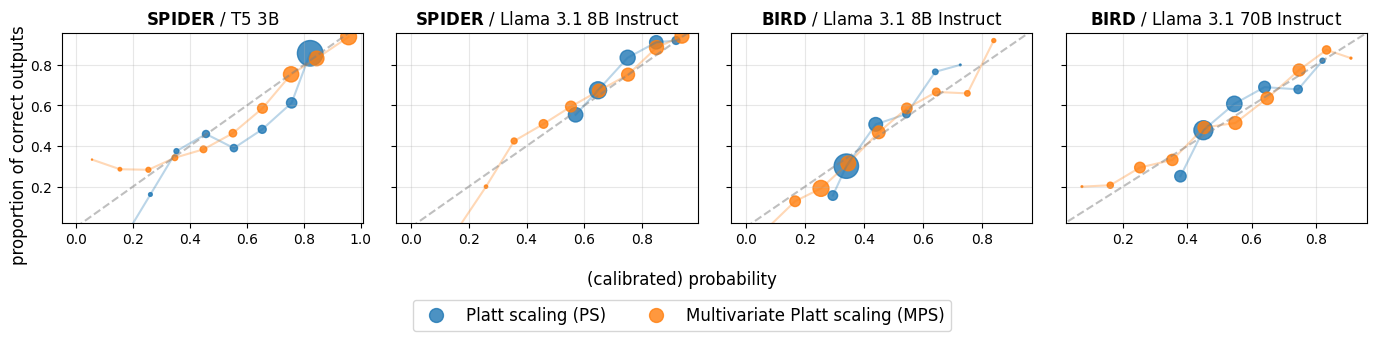
- 实验结果表明,结合多元Platt scaling(MPS)和SCF的方法,在校准和错误检测任务中,优于传统的Platt scaling方法。
📝 摘要(中文)
大型语言模型(LLMs)在Text-to-SQL解析任务中表现出色,但有时会出现自信但错误的预测。为了构建可信的Text-to-SQL系统,需要从LLM中获得可靠的不确定性度量。本文研究了如何提供一个校准后的置信度分数,以反映输出查询正确的可能性。我们的工作首次建立了基于LLM的Text-to-SQL解析后校准的基准。特别地,我们证明了Platt scaling这种经典的校准方法,相比直接使用原始模型输出概率作为置信度分数,能够显著提升性能。此外,我们提出了一种利用SQL查询的结构化特性来提供更细粒度正确性信号的Text-to-SQL校准方法,称为“子句频率”(SCF)分数。通过多元Platt scaling(MPS),我们扩展了经典的Platt scaling技术,将各个SCF分数组合成一个总体准确且校准的分数。在两个流行的Text-to-SQL数据集上的实验评估表明,我们结合MPS和SCF的方法在校准和相关的错误检测任务中,相比传统的Platt scaling,取得了进一步的改进。
🔬 方法详解
问题定义:论文旨在解决Text-to-SQL任务中,大型语言模型(LLMs)输出的置信度不可靠的问题。现有方法直接使用LLM的输出概率作为置信度,但这些概率往往没有经过校准,导致模型在错误时也可能给出高置信度,影响系统的可信度。
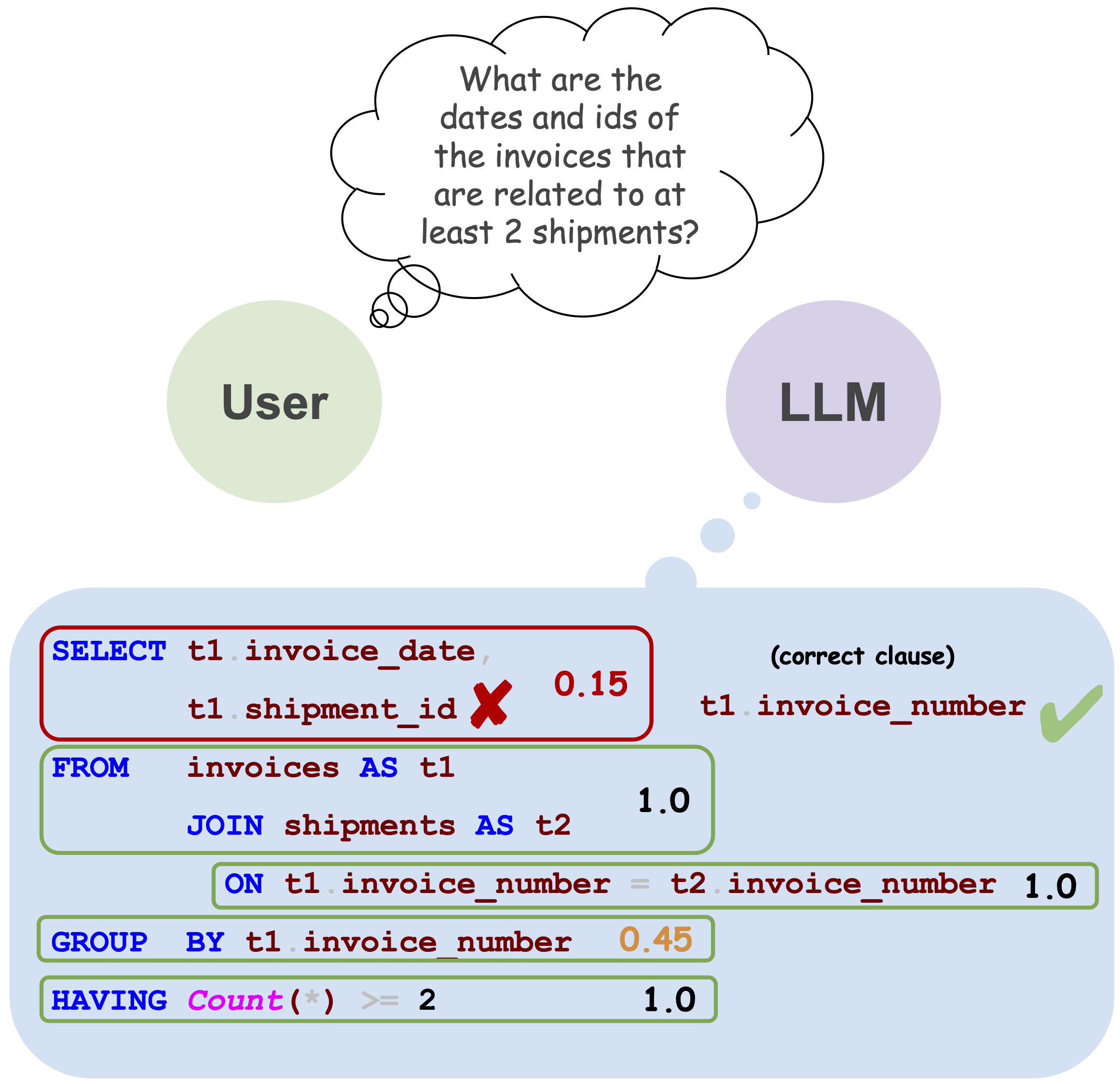
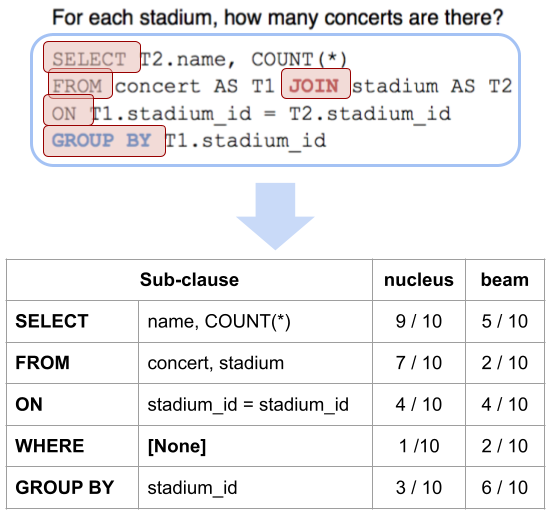
核心思路:论文的核心思路是利用SQL查询的结构化特性,将SQL语句分解为多个子句,并统计每个子句出现的频率(SCF)。这些SCF分数可以作为更细粒度的正确性信号,用于校准LLM的输出置信度。通过结合多个SCF分数,可以更准确地评估整个SQL查询的正确性。
技术框架:论文提出的方法主要包含以下几个阶段:1) 使用LLM生成SQL查询;2) 将生成的SQL查询分解为多个子句;3) 计算每个子句的频率(SCF);4) 使用多元Platt scaling(MPS)将各个SCF分数组合成一个总体置信度分数;5) 使用校准后的置信度分数进行错误检测或选择最佳查询。
关键创新:论文的关键创新在于:1) 首次提出了基于子句频率(SCF)的Text-to-SQL校准方法,利用SQL查询的结构化信息提升校准效果;2) 提出了多元Platt scaling(MPS)方法,扩展了传统的Platt scaling,使其能够处理多个SCF分数;3) 为Text-to-SQL的后校准建立了一个基准。
关键设计:论文的关键设计包括:1) 子句的定义:论文需要定义如何将SQL查询分解为有意义的子句,例如SELECT子句、FROM子句、WHERE子句等;2) SCF的计算方法:论文需要确定如何统计每个子句的频率,例如可以使用数据集中的SQL查询作为参考;3) MPS的参数设置:论文需要确定MPS模型的参数,例如学习率、迭代次数等。损失函数通常使用负对数似然损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结合MPS和SCF的方法在Spider和Bird数据集上,相比传统的Platt scaling,在校准和错误检测任务中取得了显著的改进。具体来说,该方法能够更准确地评估SQL查询的正确性,从而提高错误检测的准确率,降低误报率。
🎯 应用场景
该研究成果可应用于各种需要Text-to-SQL解析的场景,例如智能助手、数据库查询系统、数据分析平台等。通过提供更可靠的置信度评估,可以提高系统的准确性和用户信任度,减少因错误查询导致的损失。未来,该方法可以扩展到其他结构化数据查询语言或任务中。
📄 摘要(原文)
While large language models (LLMs) achieve strong performance on text-to-SQL parsing, they sometimes exhibit unexpected failures in which they are confidently incorrect. Building trustworthy text-to-SQL systems thus requires eliciting reliable uncertainty measures from the LLM. In this paper, we study the problem of providing a calibrated confidence score that conveys the likelihood of an output query being correct. Our work is the first to establish a benchmark for post-hoc calibration of LLM-based text-to-SQL parsing. In particular, we show that Platt scaling, a canonical method for calibration, provides substantial improvements over directly using raw model output probabilities as confidence scores. Furthermore, we propose a method for text-to-SQL calibration that leverages the structured nature of SQL queries to provide more granular signals of correctness, named "sub-clause frequency" (SCF) scores. Using multivariate Platt scaling (MPS), our extension of the canonical Platt scaling technique, we combine individual SCF scores into an overall accurate and calibrated score. Empirical evaluation on two popular text-to-SQL datasets shows that our approach of combining MPS and SCF yields further improvements in calibration and the related task of error detection over traditional Platt scaling.