Explaining Large Language Models with gSMILE
作者: Zeinab Dehghani, Mohammed Naveed Akram, Koorosh Aslansefat, Adil Khan, Yiannis Papadopoulos
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2025-10-21)
💡 一句话要点
提出gSMILE框架,用于提升大型语言模型token级别可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 token级别归因 模型无关 prompt扰动 Wasserstein距离 线性代理模型
📋 核心要点
- 大型语言模型决策过程不透明,限制了其在高风险场景中的应用,需要提升模型的可解释性。
- gSMILE通过prompt扰动、Wasserstein距离和线性代理模型,识别对输出影响最大的token,生成可解释的热图。
- 实验表明,gSMILE在多个LLM上实现了可靠的token级别归因,平衡了模型性能和可解释性。
📝 摘要(中文)
大型语言模型(LLMs),如GPT、LLaMA和Claude,在文本生成方面表现出色,但其决策过程仍然不透明,限制了在高风险应用中的信任和责任。我们提出了gSMILE(generative SMILE),一个模型无关的、基于扰动的框架,用于LLM中token级别的可解释性。gSMILE扩展了SMILE方法,使用受控的prompt扰动、Wasserstein距离度量和加权线性代理模型来识别对输出影响最大的输入token。这个过程能够生成直观的热图,以可视化地突出显示有影响力的token和推理路径。我们使用归因保真度、归因一致性、归因稳定性和归因准确性作为指标,在领先的LLM(OpenAI的gpt-3.5-turbo-instruct、Meta的LLaMA 3.1 Instruct Turbo和Anthropic的Claude 2.1)上评估了gSMILE。结果表明,gSMILE提供了可靠的、与人类对齐的归因,其中Claude 2.1在注意力保真度方面表现出色,而GPT-3.5实现了最高的输出一致性。这些发现证明了gSMILE在平衡模型性能和可解释性方面的能力,从而实现了更透明和值得信赖的AI系统。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)决策过程不透明的问题。现有方法难以准确识别输入token对输出的影响,导致在高风险应用中缺乏信任和责任。因此,需要一种模型无关且能提供token级别可解释性的方法。
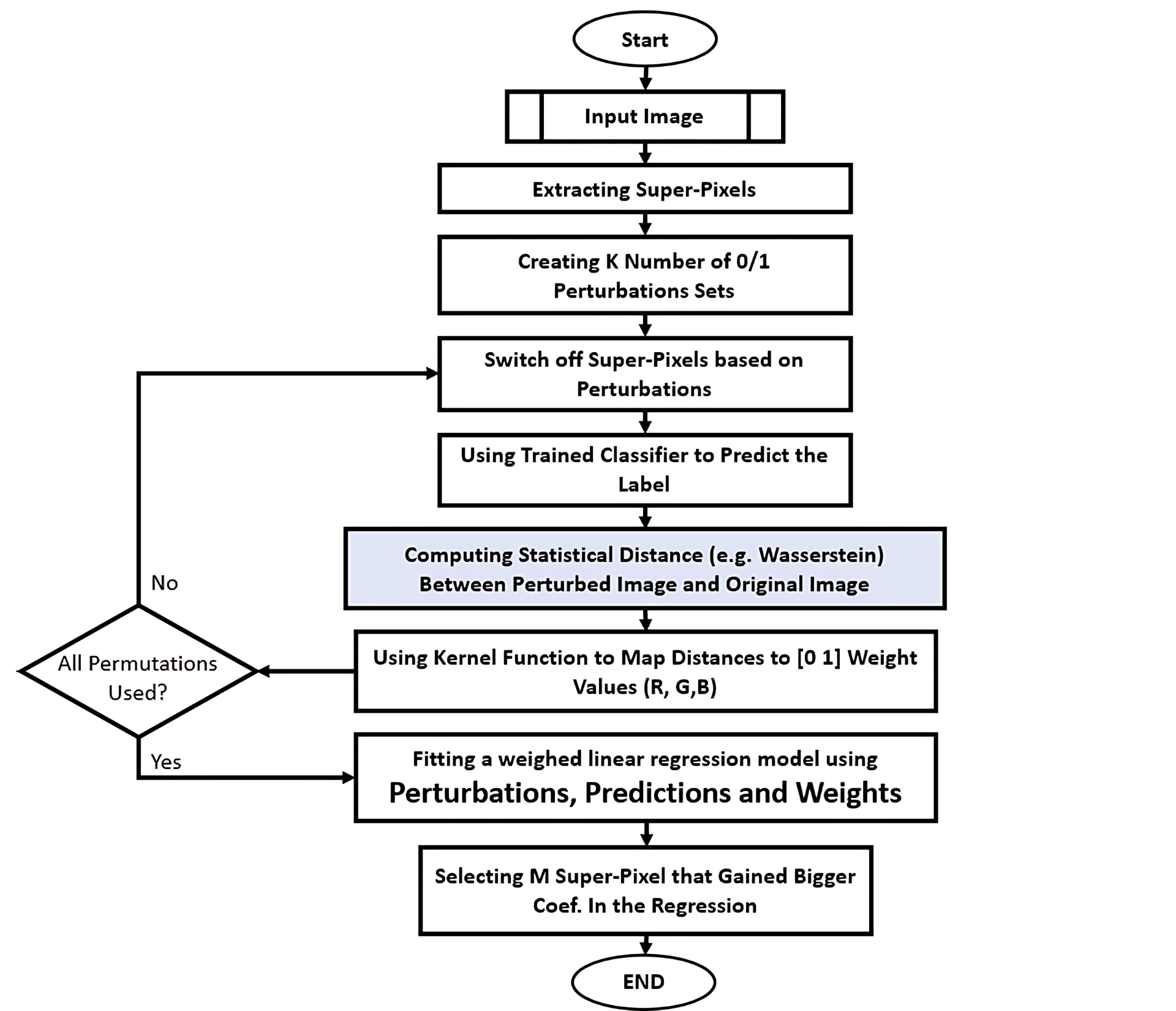
核心思路:gSMILE的核心思路是通过对输入prompt进行受控扰动,观察输出的变化,从而推断每个token对最终输出的影响程度。利用Wasserstein距离度量扰动前后输出分布的差异,并使用加权线性代理模型来近似LLM的复杂行为,从而实现高效的归因分析。
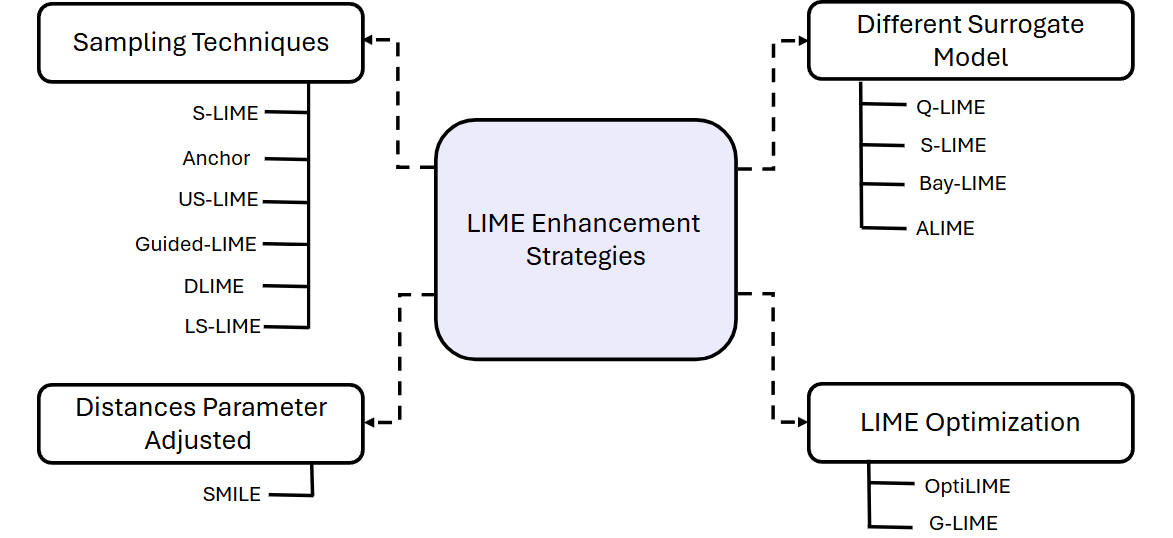
技术框架:gSMILE框架主要包含以下几个阶段:1) Prompt扰动:对输入prompt进行多种方式的扰动,例如删除、替换或修改token。2) 输出生成:使用LLM生成扰动前后prompt的输出。3) 距离度量:使用Wasserstein距离计算扰动前后输出分布的差异,量化每个token的影响。4) 线性代理模型:训练一个加权线性模型,将输入token与输出变化关联起来。5) 热图生成:根据token的影响程度生成热图,可视化地展示重要token和推理路径。
关键创新:gSMILE的关键创新在于其模型无关性和token级别的精确归因。与依赖模型内部信息的归因方法不同,gSMILE仅依赖于输入输出,因此可以应用于各种LLM。此外,通过Wasserstein距离和线性代理模型,gSMILE能够更准确地量化每个token对输出的影响,提供更细粒度的可解释性。
关键设计:gSMILE的关键设计包括:1) 扰动策略:选择合适的扰动方式,例如token删除、替换或修改,以确保扰动不会过度影响LLM的性能。2) Wasserstein距离:使用Wasserstein距离作为输出分布差异的度量,因为它对分布的微小变化更敏感。3) 线性代理模型:选择合适的线性模型,例如线性回归或逻辑回归,并使用正则化技术防止过拟合。4) 加权策略:根据token的类型和位置,对线性模型的权重进行调整,以提高归因的准确性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,gSMILE在多个LLM上实现了可靠的token级别归因。Claude 2.1在注意力保真度方面表现出色,GPT-3.5实现了最高的输出一致性。这些结果验证了gSMILE在平衡模型性能和可解释性方面的有效性,为开发更透明和值得信赖的AI系统提供了新的思路。
🎯 应用场景
gSMILE可应用于金融、医疗、法律等高风险领域,提升LLM决策的透明度和可信度。例如,在金融风控中,可以解释LLM为何拒绝某项贷款申请;在医疗诊断中,可以解释LLM为何给出某种诊断结果。此外,gSMILE还可以用于改进LLM的训练数据和模型结构,提升模型的鲁棒性和泛化能力。
📄 摘要(原文)
Large Language Models (LLMs) such as GPT, LLaMA, and Claude achieve remarkable performance in text generation but remain opaque in their decision-making processes, limiting trust and accountability in high-stakes applications. We present gSMILE (generative SMILE), a model-agnostic, perturbation-based framework for token-level interpretability in LLMs. Extending the SMILE methodology, gSMILE uses controlled prompt perturbations, Wasserstein distance metrics, and weighted linear surrogates to identify input tokens with the most significant impact on the output. This process enables the generation of intuitive heatmaps that visually highlight influential tokens and reasoning paths. We evaluate gSMILE across leading LLMs (OpenAI's gpt-3.5-turbo-instruct, Meta's LLaMA 3.1 Instruct Turbo, and Anthropic's Claude 2.1) using attribution fidelity, attribution consistency, attribution stability, attribution faithfulness, and attribution accuracy as metrics. Results show that gSMILE delivers reliable human-aligned attributions, with Claude 2.1 excelling in attention fidelity and GPT-3.5 achieving the highest output consistency. These findings demonstrate gSMILE's ability to balance model performance and interpretability, enabling more transparent and trustworthy AI systems.