Factual Self-Awareness in Language Models: Representation, Robustness, and Scaling
作者: Hovhannes Tamoyan, Subhabrata Dutta, Iryna Gurevych
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27
💡 一句话要点
揭示大语言模型事实性自我感知能力:内部表征、鲁棒性与规模效应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 事实性知识 自我感知 Transformer 线性探针
📋 核心要点
- 大型语言模型生成内容的事实性错误是其广泛应用的主要障碍,需要深入理解其内在机制。
- 该研究揭示了LLM内部存在事实性自我感知能力,通过分析Transformer残差流中的线性特征来预测事实回忆的正确性。
- 实验表明,这种自我感知信号具有鲁棒性,并且在模型训练过程中迅速出现,为LLM的可解释性提供了新视角。
📝 摘要(中文)
生成内容中的事实错误是大型语言模型(LLMs)广泛部署的主要问题之一。先前的研究表明,LLMs可以(有时)检测其生成内容中的事实错误(即,生成后的事实核查)。本文提供了证据,支持LLMs内部存在一种“指南针”,用于指示生成时事实回忆的正确性。我们证明,对于给定的主体实体和关系,LLMs在Transformer的残差流中内部编码线性特征,这些特征决定了它是否能够回忆起正确的属性(从而形成有效的实体-关系-属性三元组)。这种自我感知信号对于细微的格式变化具有鲁棒性。我们研究了通过不同示例选择策略进行上下文扰动的影响。跨模型大小和训练动态的缩放实验表明,自我感知在训练过程中迅速出现,并在中间层达到峰值。这些发现揭示了LLMs内部固有的自我监控能力,有助于提高它们的可解释性和可靠性。
🔬 方法详解
问题定义:大型语言模型在生成文本时,经常出现事实性错误,这限制了其在需要高度可靠信息的场景中的应用。现有的方法主要集中在生成后对事实进行核查,但缺乏对模型内部如何感知和处理事实信息的理解。因此,如何理解LLM内部的事实性知识表征,以及如何提高其生成事实正确内容的能力,是一个重要的研究问题。
核心思路:本文的核心思路是探究LLM在生成文本时,是否具备一种内在的“自我感知”能力,能够判断其生成的事实是否正确。作者假设LLM内部存在一种信号,可以指示其对事实回忆的置信度。通过分析Transformer的残差流,寻找与事实正确性相关的线性特征,从而揭示LLM的自我感知机制。
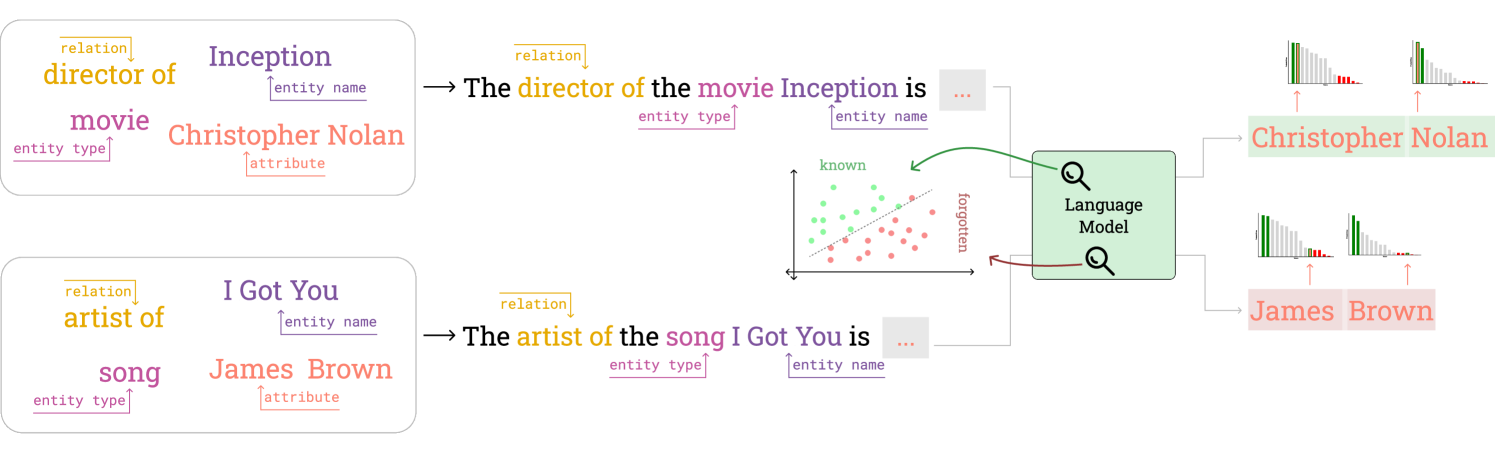
技术框架:该研究主要采用线性探针(Linear Probing)技术,分析Transformer模型的残差流。具体流程如下:1) 收集包含实体-关系-属性三元组的数据集;2) 使用LLM生成给定实体和关系下的属性;3) 提取生成过程中Transformer各层的残差流;4) 训练线性分类器,预测生成属性的正确性;5) 分析线性分类器的权重,识别与事实正确性相关的线性特征。
关键创新:该研究最重要的创新点在于发现了LLM内部存在事实性自我感知信号,并证明可以通过分析Transformer的残差流来识别这些信号。这为理解LLM的内部工作机制提供了一种新的视角,也为提高LLM的事实性知识生成能力提供了新的思路。与现有方法相比,该研究不是简单地在生成后进行事实核查,而是深入到模型内部,探究其如何感知和处理事实信息。
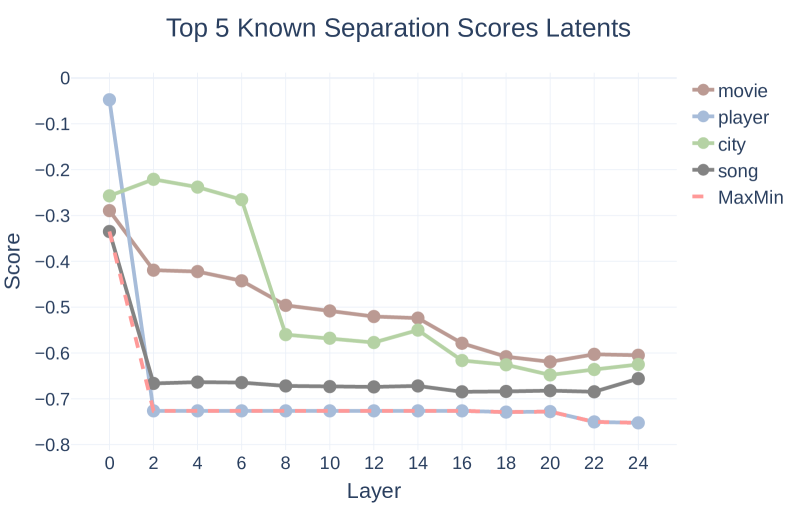
关键设计:研究中使用了多种实验设置来验证自我感知信号的鲁棒性,包括:1) 对输入文本进行细微的格式变化;2) 使用不同的示例选择策略进行上下文扰动;3) 跨不同模型大小和训练阶段进行缩放实验。此外,研究还分析了不同Transformer层中自我感知信号的强度,发现其在中间层达到峰值。这些实验设计旨在全面评估LLM的事实性自我感知能力。
🖼️ 关键图片

📊 实验亮点
研究发现,LLM在Transformer的残差流中编码了与事实正确性相关的线性特征,这些特征能够预测生成属性的正确性。实验表明,这种自我感知信号对输入格式变化具有鲁棒性,并且在模型训练过程中迅速出现。缩放实验还表明,自我感知能力在模型中间层达到峰值。
🎯 应用场景
该研究成果可应用于提升大语言模型在知识密集型任务中的可靠性,例如智能问答、知识图谱构建、自动摘要等。通过理解和利用LLM的自我感知能力,可以开发更可信赖的AI系统,减少虚假信息的传播,并提高人机交互的质量。
📄 摘要(原文)
Factual incorrectness in generated content is one of the primary concerns in ubiquitous deployment of large language models (LLMs). Prior findings suggest LLMs can (sometimes) detect factual incorrectness in their generated content (i.e., fact-checking post-generation). In this work, we provide evidence supporting the presence of LLMs' internal compass that dictate the correctness of factual recall at the time of generation. We demonstrate that for a given subject entity and a relation, LLMs internally encode linear features in the Transformer's residual stream that dictate whether it will be able to recall the correct attribute (that forms a valid entity-relation-attribute triplet). This self-awareness signal is robust to minor formatting variations. We investigate the effects of context perturbation via different example selection strategies. Scaling experiments across model sizes and training dynamics highlight that self-awareness emerges rapidly during training and peaks in intermediate layers. These findings uncover intrinsic self-monitoring capabilities within LLMs, contributing to their interpretability and reliability.