Leveraging Large Language Models for Bengali Math Word Problem Solving with Chain of Thought Reasoning
作者: Bidyarthi Paul, Jalisha Jashim Era, Mirazur Rahman Zim, Tahmid Sattar Aothoi, Faisal Muhammad Shah
分类: cs.CL, cs.LG
发布日期: 2025-05-27 (更新: 2025-07-30)
💡 一句话要点
提出SOMADHAN数据集以解决孟加拉数学文字问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 孟加拉语处理 数学文字问题 链式思维 低资源语言 大型语言模型 数据集构建 推理能力
📋 核心要点
- 孟加拉数学文字问题的解决在NLP中面临挑战,现有模型难以处理复杂的多步骤推理任务。
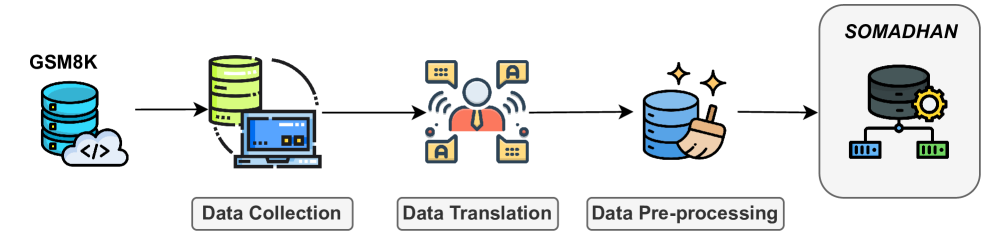
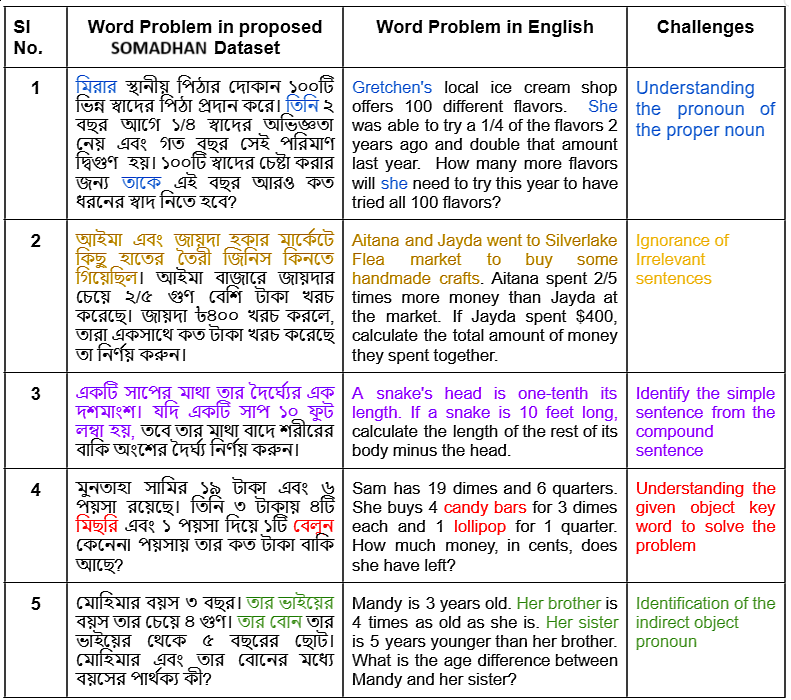
- 研究团队创建了SOMADHAN数据集,包含8792个复杂的孟加拉MWPs及其逐步解决方案,以支持推理评估和模型开发。
- 实验结果显示,使用链式思维提示的模型在多步骤逻辑任务中表现优异,LLaMA-3.3 70B模型达到了88%的准确率。
📝 摘要(中文)
解决孟加拉数学文字问题(MWPs)在自然语言处理(NLP)领域仍然是一个重大挑战,主要由于该语言资源匮乏和多步骤推理的需求。现有模型在复杂的孟加拉MWPs上表现不佳,原因在于缺乏人类标注的数据集。为此,研究团队创建了SOMADHAN,一个包含8792个复杂孟加拉MWPs及其手动逐步解决方案的数据集。通过使用SOMADHAN,评估了多种大型语言模型(LLMs),结果表明链式思维(CoT)提示显著提高了模型性能,尤其是在需要多步骤逻辑的任务中。LLaMA-3.3 70B模型在少量示例的CoT提示下达到了88%的最高准确率。该研究为孟加拉NLP领域填补了关键空白,提供了高质量的推理数据集和可扩展的解决框架。
🔬 方法详解
问题定义:本研究旨在解决孟加拉数学文字问题(MWPs)的推理挑战,现有方法因缺乏标注数据集而难以有效处理复杂问题。
核心思路:通过构建SOMADHAN数据集,提供高质量的手动标注的复杂MWPs,支持多步骤推理的模型训练和评估。使用链式思维(CoT)提示来增强模型的推理能力。
技术框架:整体架构包括数据集构建、模型选择与评估,采用多种大型语言模型(如GPT-4o、LLaMA系列等),并通过零-shot和few-shot提示进行测试。
关键创新:SOMADHAN数据集的创建是本研究的核心创新,填补了孟加拉NLP领域的空白,并通过链式思维提示显著提升了模型在复杂推理任务中的表现。
关键设计:在模型训练中,采用低秩适应(LoRA)技术进行高效微调,确保模型能够以较低的计算成本适应孟加拉MWPs。
🖼️ 关键图片

📊 实验亮点
实验结果显示,使用链式思维提示的模型在多步骤逻辑任务中表现优异,LLaMA-3.3 70B模型在few-shot CoT提示下达到了88%的准确率,显著高于标准提示的表现,展示了该方法的有效性。
🎯 应用场景
该研究的潜在应用领域包括教育技术、语言学习工具和智能辅导系统。通过提升孟加拉语的数学推理能力,可以为教育公平做出贡献,帮助更多学生掌握数学知识,尤其是在资源匮乏的环境中。
📄 摘要(原文)
Solving Bengali Math Word Problems (MWPs) remains a major challenge in natural language processing (NLP) due to the language's low-resource status and the multi-step reasoning required. Existing models struggle with complex Bengali MWPs, largely because no human-annotated Bengali dataset has previously addressed this task. This gap has limited progress in Bengali mathematical reasoning. To address this, we created SOMADHAN, a dataset of 8792 complex Bengali MWPs with manually written, step-by-step solutions. We designed this dataset to support reasoning-focused evaluation and model development in a linguistically underrepresented context. Using SOMADHAN, we evaluated a range of large language models (LLMs) - including GPT-4o, GPT-3.5 Turbo, LLaMA series models, Deepseek, and Qwen - through both zero-shot and few-shot prompting with and without Chain of Thought (CoT) reasoning. CoT prompting consistently improved performance over standard prompting, especially in tasks requiring multi-step logic. LLaMA-3.3 70B achieved the highest accuracy of 88% with few-shot CoT prompting. We also applied Low-Rank Adaptation (LoRA) to fine-tune models efficiently, enabling them to adapt to Bengali MWPs with minimal computational cost. Our work fills a critical gap in Bengali NLP by providing a high-quality reasoning dataset and a scalable framework for solving complex MWPs. We aim to advance equitable research in low-resource languages and enhance reasoning capabilities in educational and language technologies.