Exploring the Hidden Capacity of LLMs for One-Step Text Generation
作者: Gleb Mezentsev, Ivan Oseledets
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2025-11-01)
备注: accepted to EMNLP2025 main
💡 一句话要点
揭示LLM单步文本生成潜力:仅用两个嵌入即可生成数百token
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 非自回归生成 多token生成 嵌入学习 文本生成 知识蒸馏 单步生成
📋 核心要点
- 现有方法依赖自回归解码,效率较低,限制了LLM的生成速度和应用范围。
- 论文探索了LLM在非自回归模式下的多token生成能力,仅使用两个学习到的嵌入即可实现。
- 实验证明,冻结的LLM在单次前向传递中能够生成数百个准确的token,无需大量再训练。
📝 摘要(中文)
最近的研究表明,大型语言模型(LLM)可以通过自回归生成,仅从一个训练好的输入嵌入中重建出惊人长度的文本——多达数千个token。本文探讨了自回归解码对于这种重建是否是必不可少的。研究表明,当仅提供两个学习到的嵌入时,冻结的LLM可以在一次token并行前向传递中生成数百个准确的token。这揭示了自回归LLM令人惊讶且未被充分探索的多token生成能力。我们检查了这些嵌入并描述了它们编码的信息。我们还通过实验表明,虽然这些表示对于给定的文本不是唯一的,但它们在嵌入空间中形成连接和局部区域——这表明有可能训练一个实用的编码器。这种表示的存在暗示着,可以通过学习到的输入编码器在现成的LLM中本地访问多token生成,从而消除繁重的再训练,并有助于克服自回归解码的根本瓶颈,同时重用已经训练好的模型。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)主要依赖自回归解码进行文本生成,即逐个token生成。这种方式存在固有的瓶颈,效率较低,尤其是在生成长文本时。论文旨在探索是否可以绕过自回归解码,利用LLM的潜在能力进行多token并行生成,从而提高生成效率。
核心思路:论文的核心思路是,通过学习少量的输入嵌入(例如,两个),让LLM能够一次性生成多个token,而无需进行逐步的自回归解码。这种方法假设LLM内部已经具备了理解和生成文本的能力,只需要合适的输入表示来激活这种能力。
技术框架:该方法主要包含以下几个步骤:1)选择一个预训练好的LLM,并将其参数冻结。2)学习两个输入嵌入,这两个嵌入将作为LLM的输入。3)通过优化这两个嵌入,使得LLM在单次前向传递中能够生成目标文本。4)分析学习到的嵌入,理解它们所编码的信息。整体框架简单明了,重点在于如何有效地学习这两个嵌入,使其能够代表目标文本的语义信息。
关键创新:该论文的关键创新在于,它证明了LLM在非自回归模式下具有强大的多token生成能力。与传统的自回归方法相比,该方法无需逐步解码,从而显著提高了生成效率。此外,该研究还揭示了LLM内部可能存在一种未被充分利用的文本表示空间,通过学习合适的嵌入,可以激活这种空间,实现高效的文本生成。
关键设计:论文的关键设计包括:1)使用两个学习到的嵌入作为LLM的输入,而不是传统的token embedding。2)使用损失函数来衡量生成文本与目标文本之间的差异,并优化这两个嵌入。3)对学习到的嵌入进行分析,例如,通过可视化或聚类等方法,理解它们所编码的信息。具体的损失函数和优化算法的选择可能因不同的实验设置而有所不同。
🖼️ 关键图片
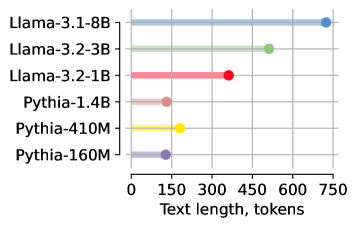
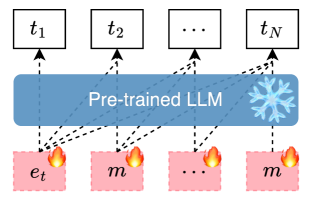

📊 实验亮点
实验结果表明,冻结的LLM仅使用两个学习到的嵌入,即可在单次前向传递中生成数百个准确的token。这表明LLM具有强大的多token生成能力,无需进行大量的再训练。此外,研究还发现,这些嵌入在嵌入空间中形成连接和局部区域,这为训练实用的编码器提供了可能性。虽然论文没有给出具体的性能数据,但是其概念验证实验充分证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于多种场景,例如:快速文本生成、机器翻译、文本摘要等。通过消除自回归解码的瓶颈,可以显著提高生成速度,降低计算成本。此外,该方法还可以用于知识蒸馏,将大型LLM的知识迁移到小型模型中,从而实现高效的文本生成。未来,该研究有望推动LLM在资源受限设备上的应用,例如移动设备和嵌入式系统。
📄 摘要(原文)
A recent study showed that large language models (LLMs) can reconstruct surprisingly long texts - up to thousands of tokens - via autoregressive generation from just one trained input embedding. In this work, we explore whether autoregressive decoding is essential for such reconstruction. We show that frozen LLMs can generate hundreds of accurate tokens in just one token-parallel forward pass, when provided with only two learned embeddings. This reveals a surprising and underexplored multi-token generation capability of autoregressive LLMs. We examine these embeddings and characterize the information they encode. We also empirically show that, although these representations are not unique for a given text, they form connected and local regions in embedding space - suggesting the potential to train a practical encoder. The existence of such representations hints that multi-token generation may be natively accessible in off-the-shelf LLMs via a learned input encoder, eliminating heavy retraining and helping to overcome the fundamental bottleneck of autoregressive decoding while reusing already-trained models.