Visual Cues Enhance Predictive Turn-Taking for Two-Party Human Interaction
作者: Sam O'Connor Russell, Naomi Harte
分类: cs.CL, cs.RO
发布日期: 2025-05-27 (更新: 2025-10-24)
备注: Accepted to ACL 2025, Findings of the Association for Computational Linguistics
期刊: In Findings of the Association for Computational Linguistics: ACL 2025, pages 209--221, Vienna, Austria. Association for Computational Linguistics, 10.18653/v1/2025.findings-acl.12
DOI: 10.18653/v1/2025.findings-acl.12
💡 一句话要点
提出MM-VAP以增强人机交互中的预测轮流发言能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 预测轮流发言 人机交互 视觉线索 语音处理 深度学习 视频会议
📋 核心要点
- 现有的预测轮流发言模型大多依赖于语音信息,忽视了视觉线索的作用,导致交互自然性不足。
- 论文提出的MM-VAP模型结合了语音和视觉信息,通过面部表情、头部姿态和视线等多模态特征来提高预测准确性。
- 实验结果显示,MM-VAP在视频会议中的预测准确率达到84%,显著高于音频模型的79%,尤其在不同发言时长的情况下均表现优越。
📝 摘要(中文)
轮流发言是一个丰富的多模态过程。预测轮流发言模型(PTTMs)促进了自然的人机交互,但大多数仅依赖于语音。我们提出了MM-VAP,这是一种多模态PTTM,结合了语音和视觉线索,包括面部表情、头部姿态和视线。研究发现,在视频会议交互中,MM-VAP的表现优于最先进的仅音频模型(84%对79%的预测准确率)。与之前的研究不同,我们根据发言间的沉默时长进行分组,结果显示视觉特征的加入使得MM-VAP在所有发言过渡时长上均优于音频模型。详细的消融研究表明,面部表情特征对模型性能贡献最大。因此,我们的假设是,当对话者能够相互看到时,视觉线索对轮流发言至关重要,必须纳入以实现准确的预测。此外,我们验证了自动语音对齐在PTTM训练中的适用性。此研究代表了对多模态PTTMs的首次全面分析,并公开了所有代码。
🔬 方法详解
问题定义:本论文旨在解决现有预测轮流发言模型在多模态人机交互中的不足,尤其是仅依赖音频信息的问题,导致预测准确性不高。
核心思路:论文的核心思路是引入视觉线索(如面部表情、头部姿态和视线)与语音信息结合,形成多模态的预测轮流发言模型MM-VAP,以提高交互的自然性和准确性。
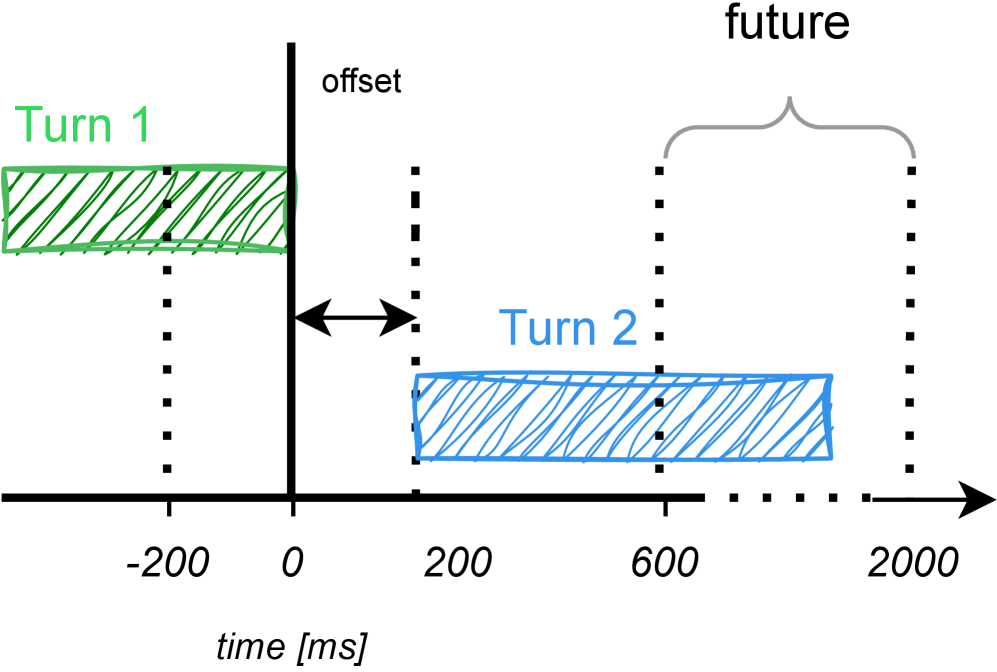
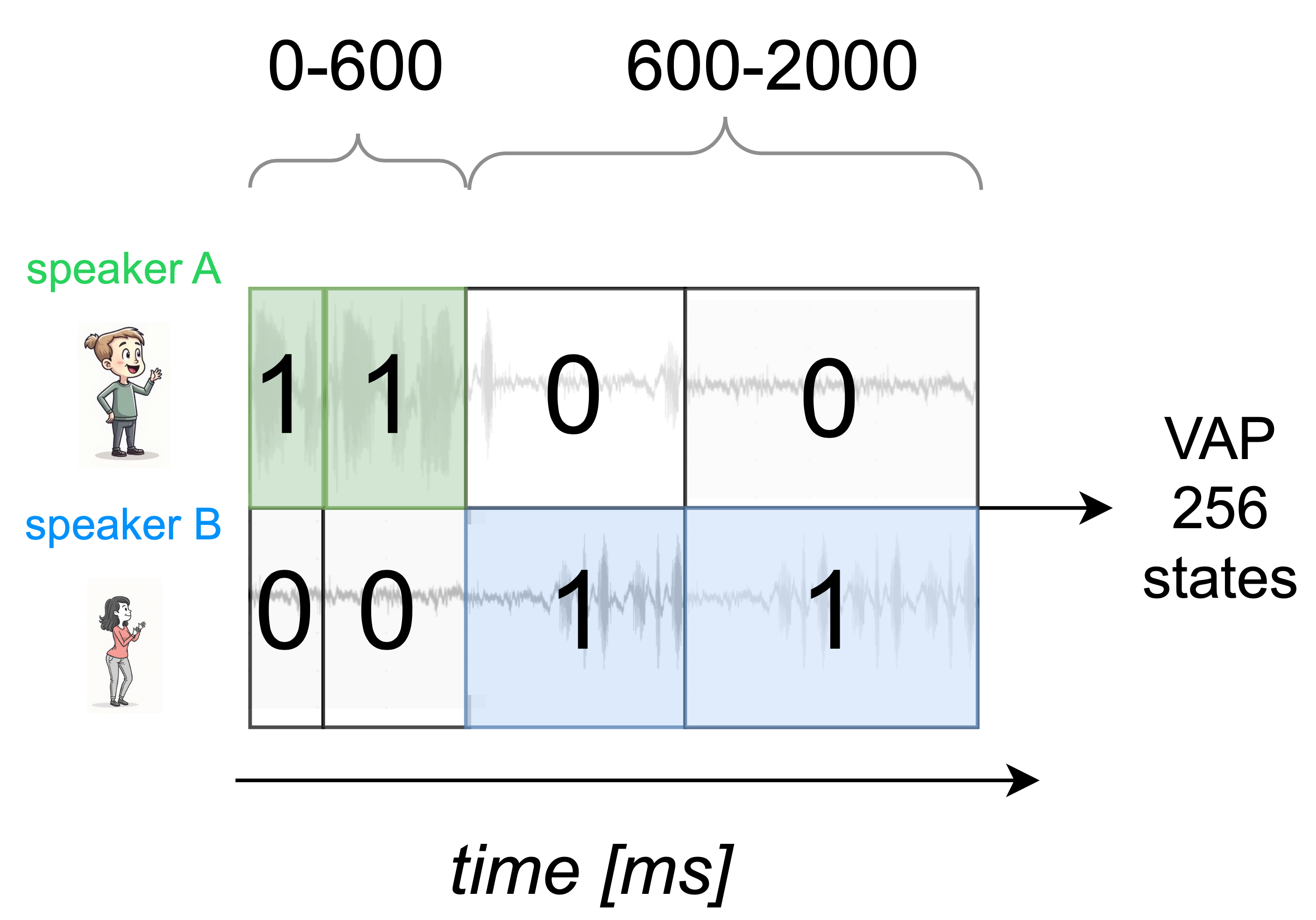
技术框架:MM-VAP模型的整体架构包括语音特征提取模块、视觉特征提取模块和融合模块,最后通过预测模块输出发言的预测结果。各模块之间通过特征融合技术进行连接,以实现信息的有效整合。
关键创新:最重要的技术创新点在于通过将视觉特征与音频特征结合,MM-VAP在所有发言过渡时长上均优于现有的音频模型,尤其是在短暂沉默的情况下表现突出。
关键设计:在模型设计中,采用了特定的损失函数来优化多模态特征的融合效果,并通过消融实验验证了面部表情特征对模型性能的显著贡献。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MM-VAP模型在视频会议中的轮流发言预测准确率达到84%,相比于传统的音频模型提升了5个百分点,尤其在不同的发言时长下均表现优越,证明了视觉线索的重要性。
🎯 应用场景
该研究的潜在应用领域包括人机交互、虚拟助手、远程会议系统等,能够显著提升机器在社交场合中的表现和用户体验。未来,随着技术的进步,MM-VAP模型可能在更广泛的领域中得到应用,如教育、医疗和娱乐等。
📄 摘要(原文)
Turn-taking is richly multimodal. Predictive turn-taking models (PTTMs) facilitate naturalistic human-robot interaction, yet most rely solely on speech. We introduce MM-VAP, a multimodal PTTM which combines speech with visual cues including facial expression, head pose and gaze. We find that it outperforms the state-of-the-art audio-only in videoconferencing interactions (84% vs. 79% hold/shift prediction accuracy). Unlike prior work which aggregates all holds and shifts, we group by duration of silence between turns. This reveals that through the inclusion of visual features, MM-VAP outperforms a state-of-the-art audio-only turn-taking model across all durations of speaker transitions. We conduct a detailed ablation study, which reveals that facial expression features contribute the most to model performance. Thus, our working hypothesis is that when interlocutors can see one another, visual cues are vital for turn-taking and must therefore be included for accurate turn-taking prediction. We additionally validate the suitability of automatic speech alignment for PTTM training using telephone speech. This work represents the first comprehensive analysis of multimodal PTTMs. We discuss implications for future work and make all code publicly available.