Who Reasons in the Large Language Models?
作者: Jie Shao, Jianxin Wu
分类: cs.CL, cs.AI
发布日期: 2025-05-27
💡 一句话要点
研究表明LLM的推理能力主要源于Transformer中的输出投影模块
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 可解释性 输出投影模块 多头自注意力
📋 核心要点
- 现有LLM推理能力提升方法缺乏理论指导,依赖经验和试错,过程不透明。
- 论文提出推理能力主要来源于Transformer的输出投影模块(oproj)的假设。
- 论文设计了SfN工具来分析LLM内部行为,验证了oproj在推理中的核心作用。
📝 摘要(中文)
尽管大型语言模型(LLM)表现出令人印象深刻的性能,但赋予它们新能力(如数学推理)的过程在很大程度上仍然是经验性的和不透明的。一个关键的开放性问题是,推理能力是源于整个模型、特定模块,还是仅仅是过拟合的产物。在这项工作中,我们假设训练良好的LLM中的推理能力主要归因于Transformer多头自注意力(MHSA)机制中的输出投影模块(oproj)。为了支持这一假设,我们引入了用于网络诊断的听诊器(SfN),这是一套旨在探测和分析LLM内部行为的诊断工具。使用SfN,我们提供了环境和经验证据,表明oproj在实现推理方面起着核心作用,而其他模块更多地贡献于流畅的对话。这些发现为LLM的可解释性提供了新的视角,并为更有针对性的训练策略开辟了道路,从而可能实现更高效和专业的LLM。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中推理能力来源不明确的问题。现有方法主要通过经验性的训练和调整来提升LLM的推理能力,缺乏对模型内部机制的深入理解,导致训练过程效率低下且难以解释。因此,理解LLM中哪些模块负责推理,以及如何更有效地训练这些模块,是当前研究面临的重要挑战。
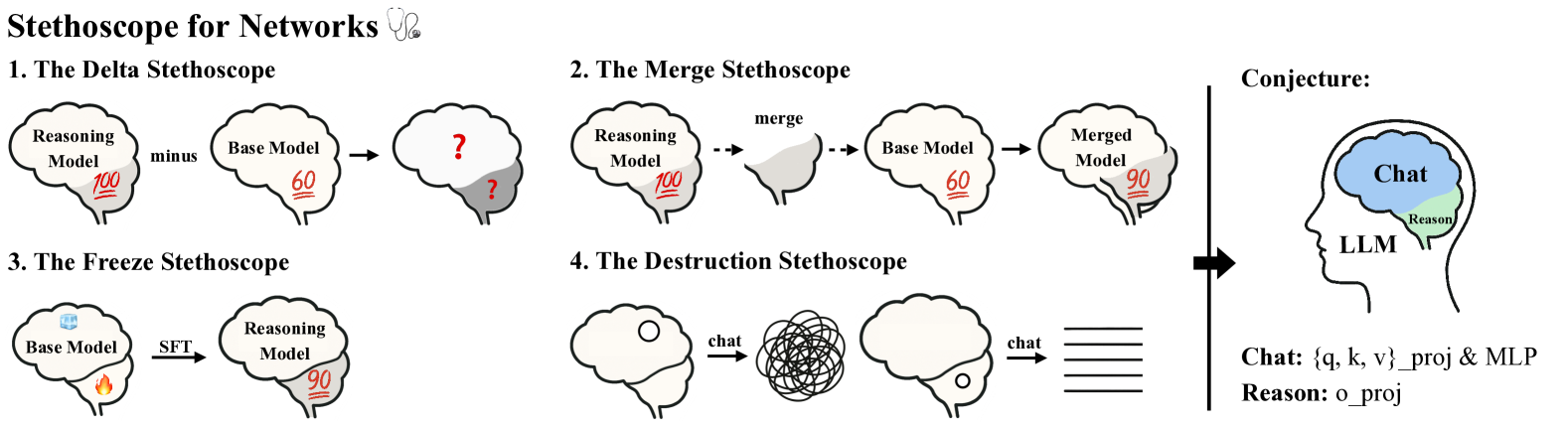
核心思路:论文的核心思路是假设LLM的推理能力主要集中在Transformer架构中的输出投影模块(oproj)。作者认为,oproj负责将自注意力机制提取的信息进行整合和输出,因此在推理过程中起着关键作用。通过分析oproj的行为,可以更好地理解LLM的推理机制,并为更有针对性的训练策略提供指导。
技术框架:论文提出了一个名为SfN(Stethoscope for Networks)的诊断工具,用于探测和分析LLM的内部行为。SfN主要包含以下几个模块:1) 激活分析:用于分析不同模块的激活值,以确定哪些模块在推理过程中更加活跃;2) 梯度分析:用于分析不同模块的梯度,以确定哪些模块对推理性能的影响更大;3) 消融实验:通过移除或修改特定模块,来评估其对推理性能的影响。通过这些模块的综合分析,可以深入了解LLM的内部机制。
关键创新:论文最重要的技术创新点在于提出了oproj在LLM推理中起核心作用的假设,并设计了SfN工具来验证该假设。与以往主要关注整个模型或特定注意力头的方法不同,论文将注意力集中在oproj这一特定模块上,从而更精确地定位了推理能力的关键来源。此外,SfN工具提供了一种系统化的方法来分析LLM的内部行为,为LLM的可解释性研究提供了新的思路。
关键设计:SfN工具的关键设计在于其模块化的结构和灵活的配置。用户可以根据需要选择不同的分析模块,并调整其参数。例如,在激活分析中,用户可以选择不同的激活函数和统计指标;在梯度分析中,用户可以选择不同的优化算法和损失函数。此外,SfN还支持对不同类型的LLM进行分析,并提供了可视化界面,方便用户理解和解释分析结果。
🖼️ 关键图片
📊 实验亮点
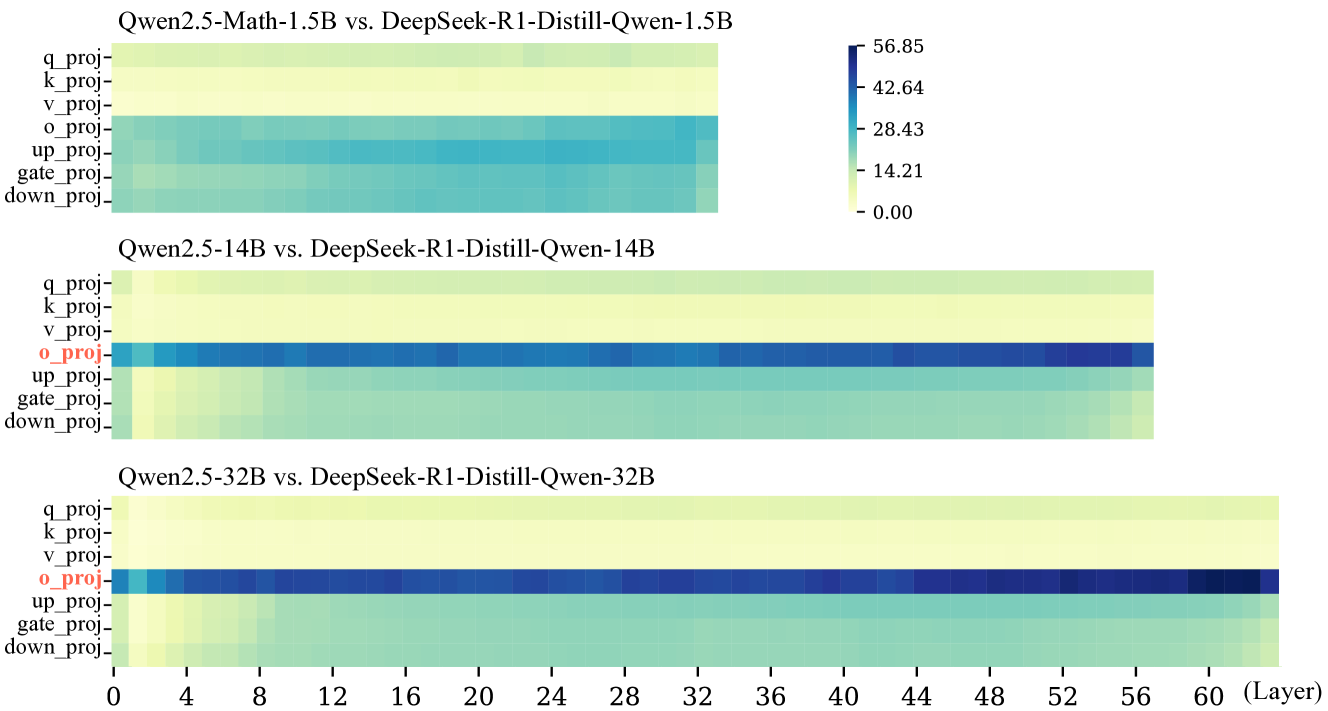
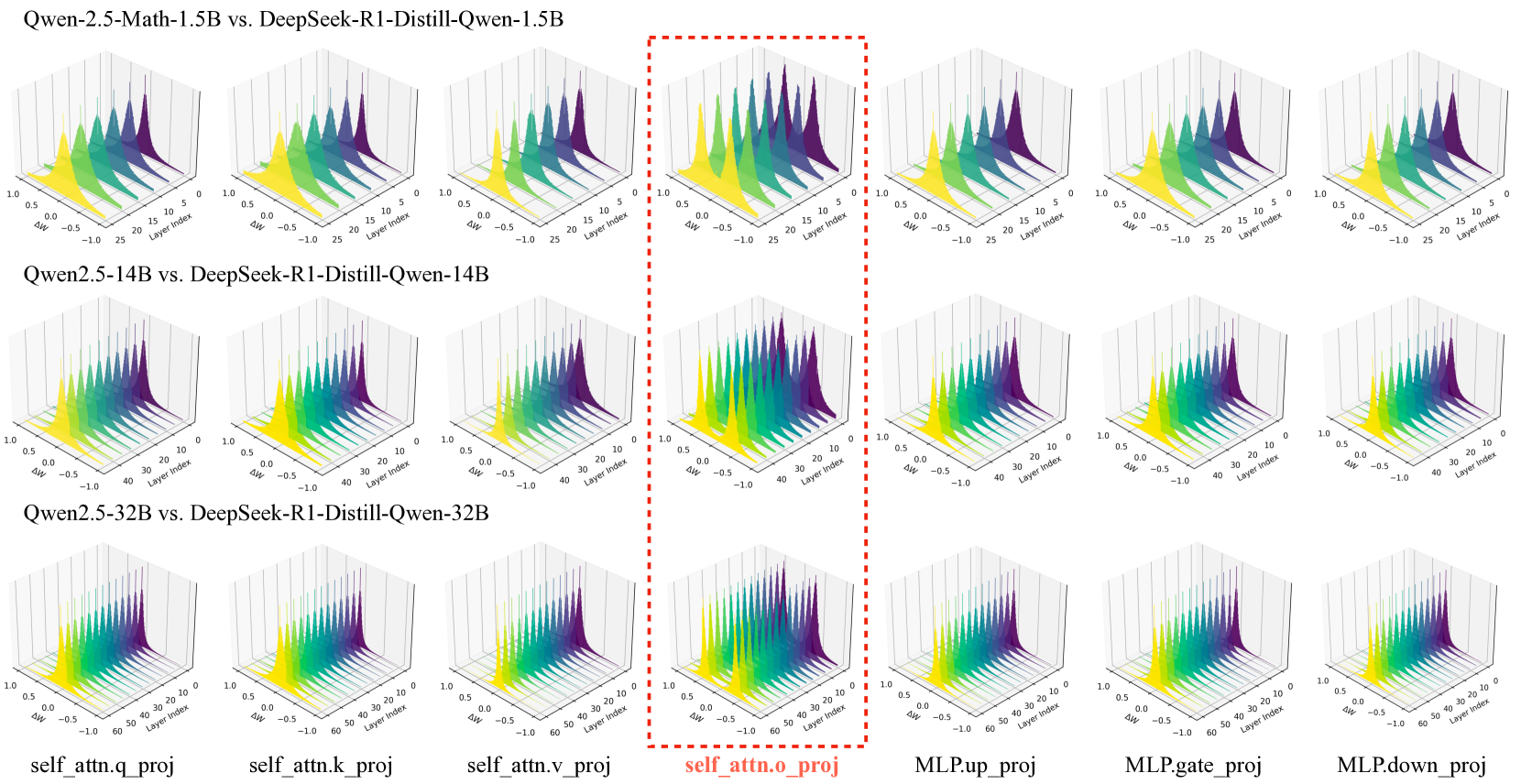
实验结果表明,oproj模块在LLM的推理过程中起着核心作用,而其他模块更多地贡献于流畅的对话。通过消融实验,发现移除oproj模块会导致推理性能显著下降,而移除其他模块的影响相对较小。此外,通过分析oproj模块的激活值和梯度,发现其在推理过程中更加活跃,并且对推理性能的影响更大。
🎯 应用场景
该研究成果可应用于LLM的优化和改进,例如,可以更有针对性地训练oproj模块,从而提高LLM的推理能力。此外,该研究还有助于开发更高效和专业的LLM,例如,可以针对特定任务设计专门的oproj模块。该研究对于LLM的可解释性研究也具有重要意义,有助于我们更好地理解LLM的内部机制。
📄 摘要(原文)
Despite the impressive performance of large language models (LLMs), the process of endowing them with new capabilities--such as mathematical reasoning--remains largely empirical and opaque. A critical open question is whether reasoning abilities stem from the entire model, specific modules, or are merely artifacts of overfitting. In this work, we hypothesize that the reasoning capabilities in well-trained LLMs are primarily attributed to the output projection module (oproj) in the Transformer's multi-head self-attention (MHSA) mechanism. To support this hypothesis, we introduce Stethoscope for Networks (SfN), a suite of diagnostic tools designed to probe and analyze the internal behaviors of LLMs. Using SfN, we provide both circumstantial and empirical evidence suggesting that oproj plays a central role in enabling reasoning, whereas other modules contribute more to fluent dialogue. These findings offer a new perspective on LLM interpretability and open avenues for more targeted training strategies, potentially enabling more efficient and specialized LLMs.