Evaluating and Steering Modality Preferences in Multimodal Large Language Model
作者: Yu Zhang, Jinlong Ma, Yongshuai Hou, Xuefeng Bai, Kehai Chen, Yang Xiang, Jun Yu, Min Zhang
分类: cs.CL
发布日期: 2025-05-27 (更新: 2025-09-29)
备注: Modality Preference
💡 一句话要点
提出MC²基准评估多模态大语言模型中的模态偏好,并通过表征工程实现偏好操控。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 模态偏好 表征工程 幻觉缓解 多模态机器翻译
📋 核心要点
- 现有MLLM在处理多模态冲突信息时存在模态偏好,但缺乏系统性的评估和控制方法。
- 论文提出MC²基准来评估模态偏好,并利用表征工程在不微调的情况下操控模态偏好。
- 实验表明,MLLM存在模态偏好,且提出的方法能有效引导偏好,并在下游任务中取得提升。
📝 摘要(中文)
多模态大语言模型(MLLMs)在多模态上下文的复杂任务上取得了显著的性能。然而,当处理多模态上下文时,它们是否表现出模态偏好仍然缺乏研究。为了研究这个问题,我们首先构建了一个MC²基准,该基准在受控的证据冲突场景下,系统地评估模态偏好,即在基于多模态冲突证据进行决策时,倾向于偏爱一种模态而非另一种模态的趋势。我们广泛的评估表明,所有18个经过测试的MLLM通常表现出明显的模态偏差,并且模态偏好可以受到外部干预的影响。深入分析表明,偏好方向可以在MLLM的潜在表征中捕获。在此基础上,我们提出了一种基于表征工程的探测和引导方法,以显式地控制模态偏好,而无需额外的微调或精心设计的提示。我们的方法有效地放大了朝向期望方向的模态偏好,并应用于下游任务,如幻觉缓解和多模态机器翻译,产生了有希望的改进。
🔬 方法详解
问题定义:多模态大语言模型在处理包含冲突信息的多模态输入时,往往会表现出对特定模态的偏好,即模态偏好。现有方法缺乏对这种偏好的系统性评估和有效控制,导致模型在一些需要平衡多模态信息的任务中表现不佳。
核心思路:论文的核心思路是首先通过构建一个受控的证据冲突场景基准(MC²)来量化MLLM的模态偏好。然后,通过分析模型内部表征,找到与模态偏好相关的潜在空间方向。最后,通过在潜在空间中对表征进行引导,从而显式地控制模型的模态偏好,而无需进行额外的微调。
技术框架:整体框架包含三个主要阶段:1) MC²基准构建和评估:设计包含冲突信息的图像和文本对,评估MLLM对不同模态信息的偏好程度。2) 表征分析:提取MLLM在处理多模态输入时的中间层表征,分析表征与模态偏好之间的关系,找到能够区分不同模态偏好的表征方向。3) 表征引导:通过在潜在空间中对表征进行线性变换,增强或减弱模型对特定模态的偏好。
关键创新:最重要的创新点在于提出了一种基于表征工程的模态偏好控制方法。与传统的微调或提示工程方法不同,该方法直接在模型的潜在空间中进行操作,无需额外的训练数据或复杂的提示设计,从而实现了更高效和灵活的模态偏好控制。
关键设计:关键设计包括:1) MC²基准的设计,确保能够有效区分不同模态的偏好。2) 表征分析方法,例如使用线性探针来识别与模态偏好相关的表征方向。3) 表征引导策略,例如通过在表征空间中添加或减去一个偏好向量来调整模型的模态偏好。
🖼️ 关键图片

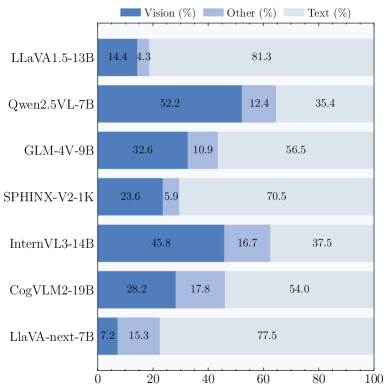
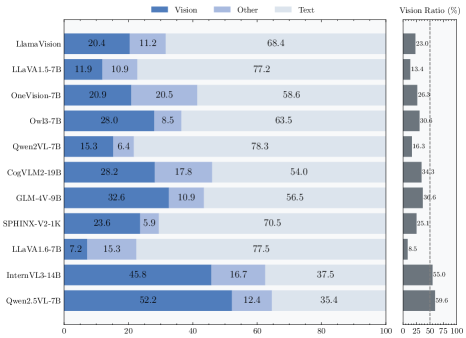
📊 实验亮点
实验结果表明,所有测试的18个MLLM都表现出明显的模态偏好。通过提出的表征引导方法,可以有效地放大模型对期望模态的偏好,并在幻觉缓解和多模态机器翻译等下游任务中取得显著提升。例如,在幻觉缓解任务中,该方法能够有效降低模型生成错误信息的概率。
🎯 应用场景
该研究成果可应用于多种需要平衡多模态信息的场景,例如:幻觉缓解(通过增强对可靠模态的偏好来减少模型生成不真实信息的可能性)、多模态机器翻译(通过平衡源语言和目标语言的模态信息来提高翻译质量)、以及视觉问答等。该方法能够提升模型在复杂多模态任务中的可靠性和准确性,具有重要的实际应用价值。
📄 摘要(原文)
Multimodal large language models (MLLMs) have achieved remarkable performance on complex tasks with multimodal context. However, it is still understudied whether they exhibit modality preference when processing multimodal contexts. To study this question, we first build a \textbf{MC\textsuperscript{2}} benchmark under controlled evidence conflict scenarios to systematically evaluate modality preference, which is the tendency to favor one modality over another when making decisions based on multimodal conflicting evidence. Our extensive evaluation reveals that all 18 tested MLLMs generally demonstrate clear modality bias, and modality preference can be influenced by external interventions. An in-depth analysis reveals that the preference direction can be captured within the latent representations of MLLMs. Built on this, we propose a probing and steering method based on representation engineering to explicitly control modality preference without additional fine-tuning or carefully crafted prompts. Our method effectively amplifies modality preference toward a desired direction and applies to downstream tasks such as hallucination mitigation and multimodal machine translation, yielding promising improvements.