Trans-EnV: A Framework for Evaluating the Linguistic Robustness of LLMs Against English Varieties
作者: Jiyoung Lee, Seungho Kim, Jieun Han, Jun-Min Lee, Kitaek Kim, Alice Oh, Edward Choi
分类: cs.CL, cs.AI
发布日期: 2025-05-27 (更新: 2025-10-09)
备注: NeurIPS 2025 Track on Datasets and Benchmarks (27 pages, 6 figures, 16 tables)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
Trans-EnV框架评估LLM在不同英语变体下的语言鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言鲁棒性 大型语言模型 英语变体 自动转换 公平性评估
📋 核心要点
- 现有LLM评估主要集中于标准美式英语,忽略了全球英语变体的多样性,可能导致公平性问题。
- Trans-EnV框架结合语言学知识和LLM转换,自动将标准英语数据集转换为多种英语变体。
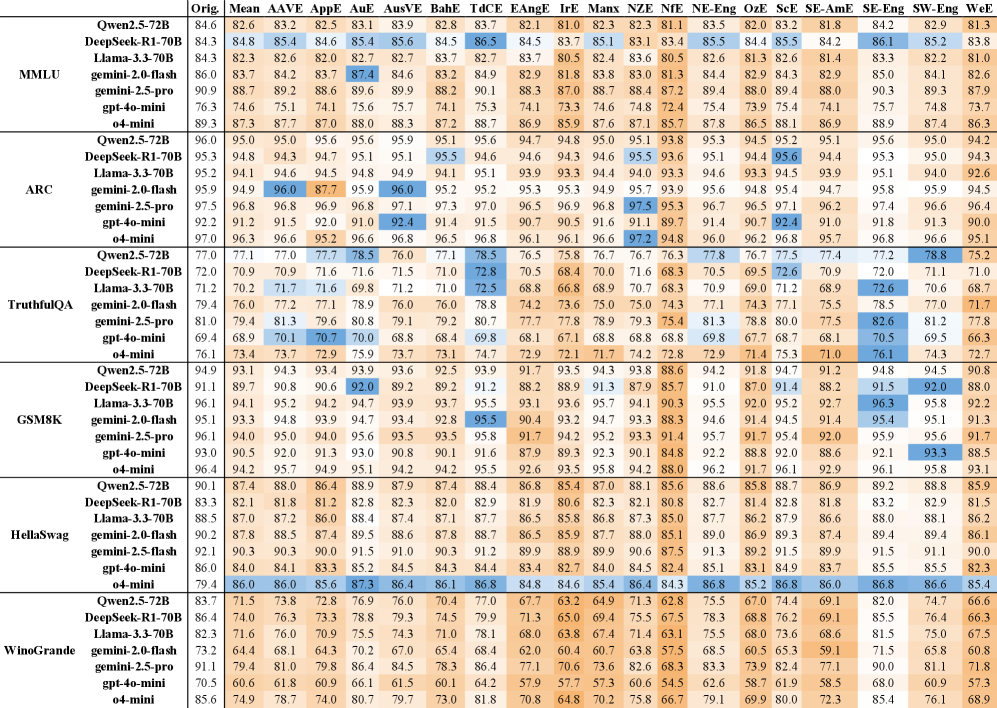
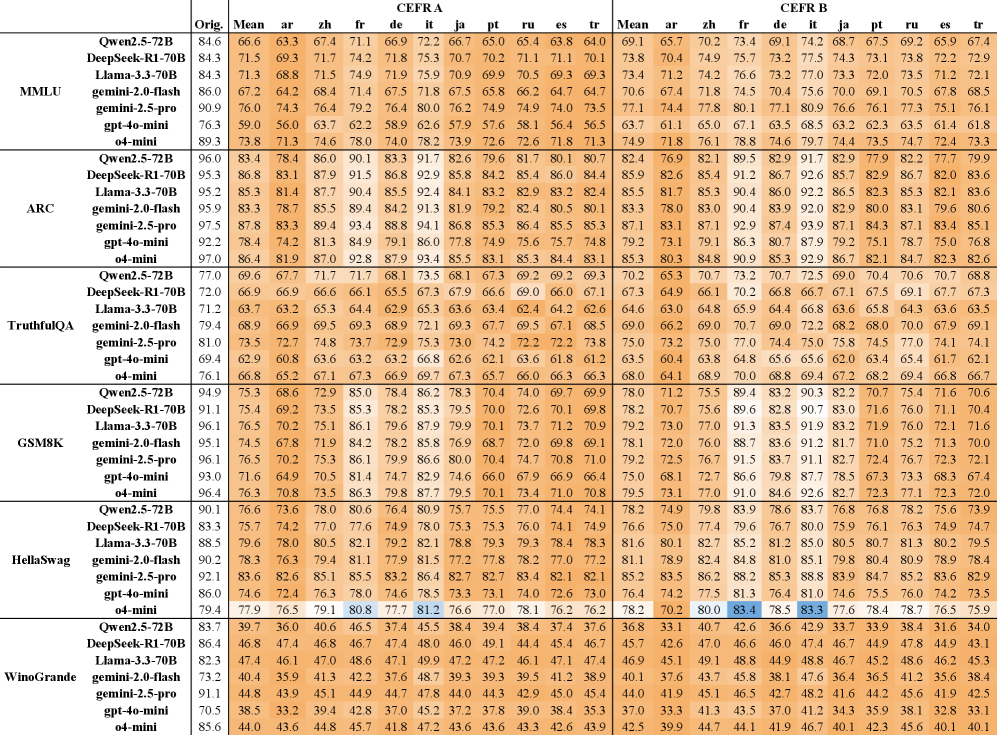
- 实验结果表明,LLM在非标准英语变体上的性能显著下降,准确率最多降低46.3%。
📝 摘要(中文)
大型语言模型(LLMs)主要在标准美式英语(SAE)上进行评估,往往忽略了全球英语变体的多样性。这种狭隘的关注可能会引发公平性问题,因为在非标准变体上的性能下降可能导致全球用户无法平等地受益。因此,至关重要的是对LLM在多种非标准英语变体上的语言鲁棒性进行广泛评估。我们引入了Trans-EnV,一个自动将SAE数据集转换为多种英语变体以评估语言鲁棒性的框架。我们的框架结合了(1)语言学专家知识,从语言学文献和语料库中整理出特定变体的特征和转换指南,以及(2)基于LLM的转换,以确保语言有效性和可扩展性。使用Trans-EnV,我们将六个基准数据集转换为38种英语变体,并评估了七个最先进的LLM。我们的结果显示出显著的性能差异,在非标准变体上的准确率下降高达46.3%。这些发现强调了在不同英语变体中进行全面语言鲁棒性评估的重要性。Trans-EnV的每次构建都通过严格的统计测试和与第二语言习得领域研究人员的咨询进行了验证,确保了其语言有效性。我们的代码和数据集可在https://github.com/jiyounglee-0523/TransEnV 和 https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1 公开获取。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)的评估主要集中在标准美式英语(SAE)上,忽略了全球范围内存在的各种非标准英语变体。这种评估方式的局限性在于,它无法保证LLMs在处理不同英语变体时的性能一致性,从而可能导致对使用非标准英语人群的不公平待遇。现有方法缺乏对LLM在不同英语变体下的鲁棒性的系统性评估。
核心思路:Trans-EnV的核心思路是构建一个自动化的框架,能够将现有的标准美式英语数据集转换为多种非标准英语变体,从而为评估LLMs的语言鲁棒性提供数据基础。该框架结合了语言学专家的知识和LLM的生成能力,以确保转换后的数据的语言有效性和可扩展性。通过在这些转换后的数据集上评估LLMs,可以更全面地了解它们在处理不同英语变体时的性能表现。
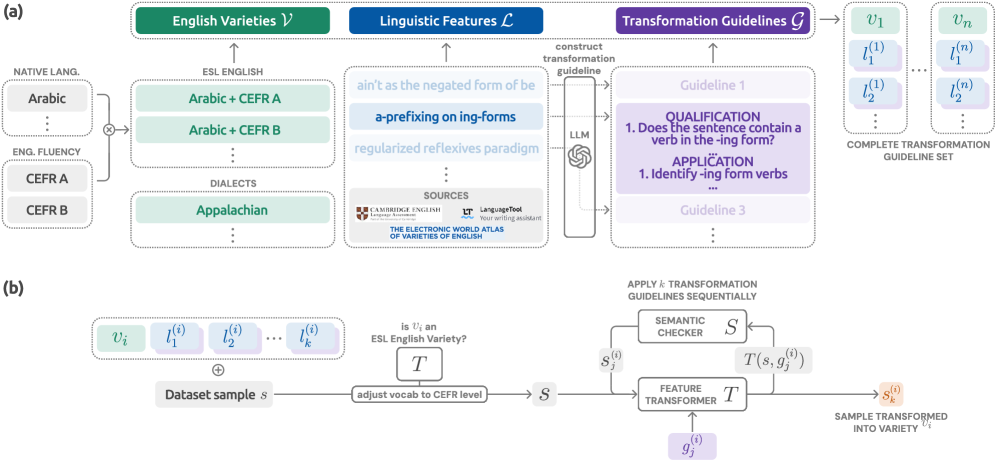
技术框架:Trans-EnV框架包含两个主要组成部分:(1) 基于语言学专家知识的变体特征和转换指南的整理;(2) 基于LLM的转换过程。首先,从语言学文献和语料库中提取特定英语变体的语言特征,并制定相应的转换规则。然后,利用LLM根据这些规则将标准美式英语数据集转换为目标英语变体。整个流程经过严格的统计测试和专家验证,以确保转换后的数据的语言有效性。
关键创新:Trans-EnV的关键创新在于其结合了语言学知识和LLM的生成能力,实现了一种可扩展且语言有效的非标准英语变体数据生成方法。与传统的手动数据增强方法相比,Trans-EnV能够自动生成大量不同变体的数据,从而大大提高了评估LLMs语言鲁棒性的效率。此外,通过语言学专家的参与,保证了生成数据的语言质量。
关键设计:Trans-EnV的关键设计包括:(1) 变体特征的选取,需要仔细研究不同英语变体的语法、词汇和发音等方面的差异;(2) LLM转换规则的设计,需要确保转换后的数据既符合目标变体的语言习惯,又保持原始数据的语义信息;(3) 验证机制,包括统计测试和专家评审,用于评估转换后的数据的语言有效性。具体的参数设置和网络结构取决于所使用的LLM模型,但核心目标是尽可能准确地模拟目标英语变体的语言特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Trans-EnV框架将六个基准数据集转换为38种英语变体后,七个最先进的LLM在非标准变体上的准确率显著下降,最高降幅达46.3%。这表明LLM在处理非标准英语变体时存在明显的性能差距,突出了Trans-EnV框架在评估LLM语言鲁棒性方面的重要性。
🎯 应用场景
Trans-EnV框架可用于评估和提升LLM在各种英语变体下的性能,从而提高LLM的公平性和可用性。该框架可应用于机器翻译、文本摘要、问答系统等多种自然语言处理任务,尤其是在全球化应用场景下,确保不同英语背景的用户都能获得良好的体验。未来,该框架可以扩展到其他语言,以评估和提升LLM的多语言鲁棒性。
📄 摘要(原文)
Large Language Models (LLMs) are predominantly evaluated on Standard American English (SAE), often overlooking the diversity of global English varieties. This narrow focus may raise fairness concerns as degraded performance on non-standard varieties can lead to unequal benefits for users worldwide. Therefore, it is critical to extensively evaluate the linguistic robustness of LLMs on multiple non-standard English varieties. We introduce Trans-EnV, a framework that automatically transforms SAE datasets into multiple English varieties to evaluate the linguistic robustness. Our framework combines (1) linguistics expert knowledge to curate variety-specific features and transformation guidelines from linguistic literature and corpora, and (2) LLM-based transformations to ensure both linguistic validity and scalability. Using Trans-EnV, we transform six benchmark datasets into 38 English varieties and evaluate seven state-of-the-art LLMs. Our results reveal significant performance disparities, with accuracy decreasing by up to 46.3% on non-standard varieties. These findings highlight the importance of comprehensive linguistic robustness evaluation across diverse English varieties. Each construction of Trans-EnV was validated through rigorous statistical testing and consultation with a researcher in the field of second language acquisition, ensuring its linguistic validity. Our code and datasets are publicly available at https://github.com/jiyounglee-0523/TransEnV and https://huggingface.co/collections/jiyounglee0523/transenv-681eadb3c0c8cf363b363fb1.