Rethinking Information Synthesis in Multimodal Question Answering A Multi-Agent Perspective
作者: Krishna Singh Rajput, Tejas Anvekar, Chitta Baral, Vivek Gupta
分类: cs.CL
发布日期: 2025-05-27
💡 一句话要点
提出MAMMQA多智能体框架,提升多模态问答的准确性和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态问答 多智能体系统 视觉语言模型 大型语言模型 跨模态推理 信息融合 问题分解
📋 核心要点
- 现有方法在多模态问答中依赖单一的通用推理策略,忽略了各模态的独特性,限制了准确性和可解释性。
- MAMMQA采用多智能体架构,利用多个VLM和LLM,分别负责子问题分解、跨模态信息融合和答案生成。
- 实验表明,MAMMQA在多个多模态问答基准测试中,显著优于现有基线方法,提升了准确性和鲁棒性。
📝 摘要(中文)
本文提出了一种名为MAMMQA的多智能体问答框架,用于处理包含文本、表格和图像的多模态输入。该系统包含两个视觉语言模型(VLM)智能体和一个基于文本的大型语言模型(LLM)智能体。第一个VLM将用户查询分解为子问题,并从每个模态中顺序检索部分答案。第二个VLM通过跨模态推理综合和细化这些结果。最后,LLM将这些见解整合为连贯的答案。这种模块化设计通过使推理过程透明化来增强可解释性,并允许每个智能体在其专业领域内运行。在各种多模态问答基准上的实验表明,我们的协作多智能体框架在准确性和鲁棒性方面始终优于现有的基线。
🔬 方法详解
问题定义:论文旨在解决多模态问答(Multimodal Question Answering, MQA)中信息融合的难题。现有方法通常采用单一的、泛化的推理策略,无法充分利用不同模态(如文本、图像、表格)的特性,导致准确率和可解释性受限。这些方法难以针对不同模态的信息进行针对性处理和有效整合。
核心思路:论文的核心思路是将MQA任务分解为多个子任务,并分配给不同的智能体(Agent)处理。每个智能体专注于特定模态或特定类型的推理,从而实现更精细化和高效的信息处理。通过智能体之间的协作,最终完成整个MQA任务。这种“分而治之”的策略能够更好地利用各模态的优势,提升整体性能。
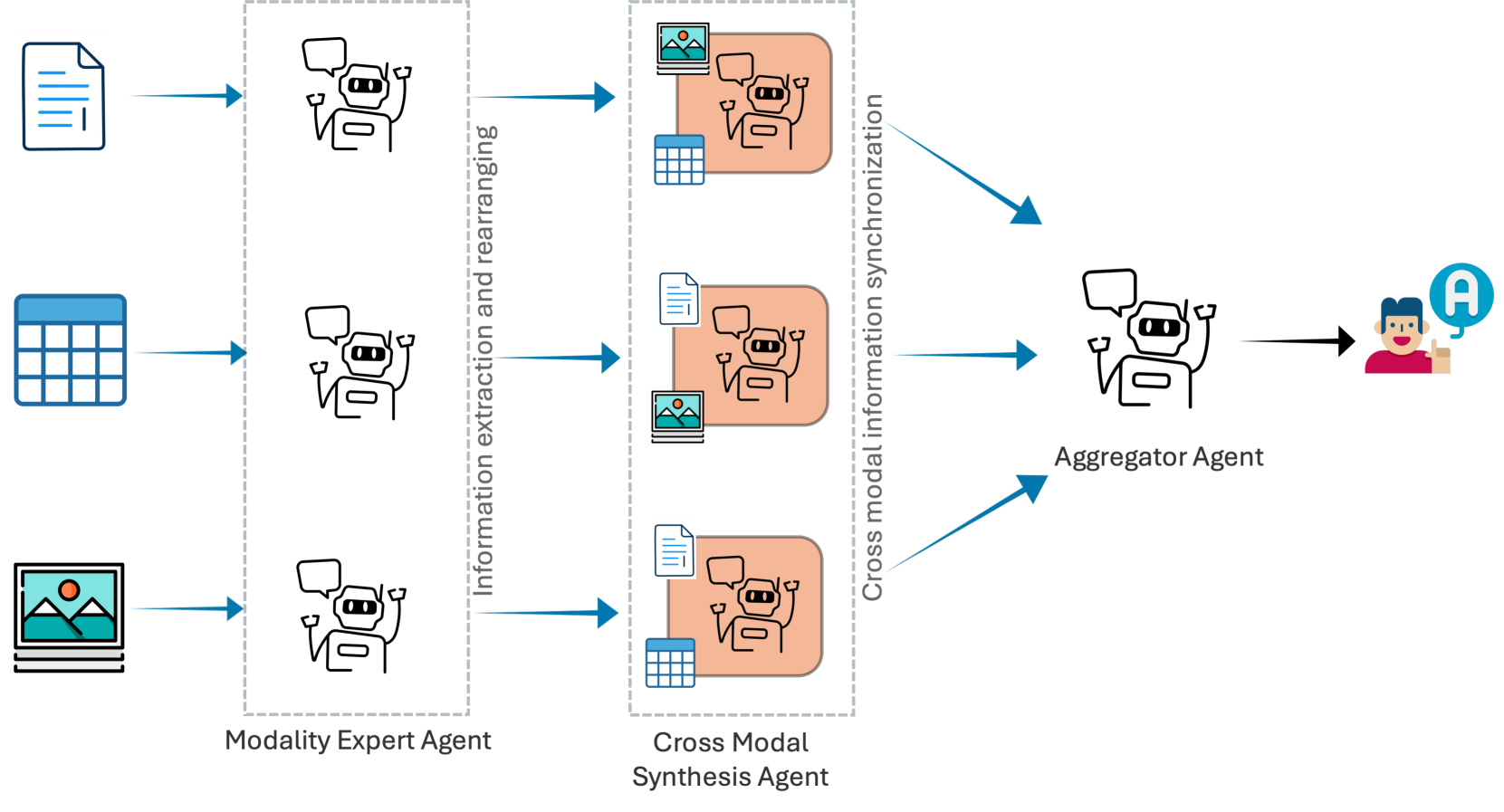
技术框架:MAMMQA框架包含三个主要智能体:两个视觉语言模型(VLM)智能体和一个文本大型语言模型(LLM)智能体。第一个VLM智能体负责将用户查询分解为多个子问题,并从不同的模态(文本、图像、表格)中检索相关的部分答案。第二个VLM智能体负责对这些部分答案进行跨模态推理,综合不同模态的信息,并进行细化。最后,LLM智能体将这些综合后的信息整合为连贯的最终答案。
关键创新:MAMMQA的关键创新在于其多智能体架构,它将MQA任务分解为多个子任务,并分配给不同的智能体处理。这种架构允许每个智能体专注于特定模态或特定类型的推理,从而实现更精细化和高效的信息处理。与现有方法相比,MAMMQA能够更好地利用各模态的优势,提升整体性能和可解释性。此外,智能体之间的协作机制也是一个重要的创新点。
关键设计:MAMMQA框架中,VLM智能体和LLM智能体的选择是关键设计之一。论文中具体使用的VLM和LLM模型未知,但选择合适的预训练模型对于智能体的性能至关重要。此外,智能体之间的通信机制,即如何传递和整合信息,也是一个重要的设计细节。论文中可能使用了某种形式的注意力机制或知识图谱来辅助跨模态推理。损失函数的设计也未知,但可能包括了问答准确率、推理路径的合理性等方面的考虑。
🖼️ 关键图片

📊 实验亮点
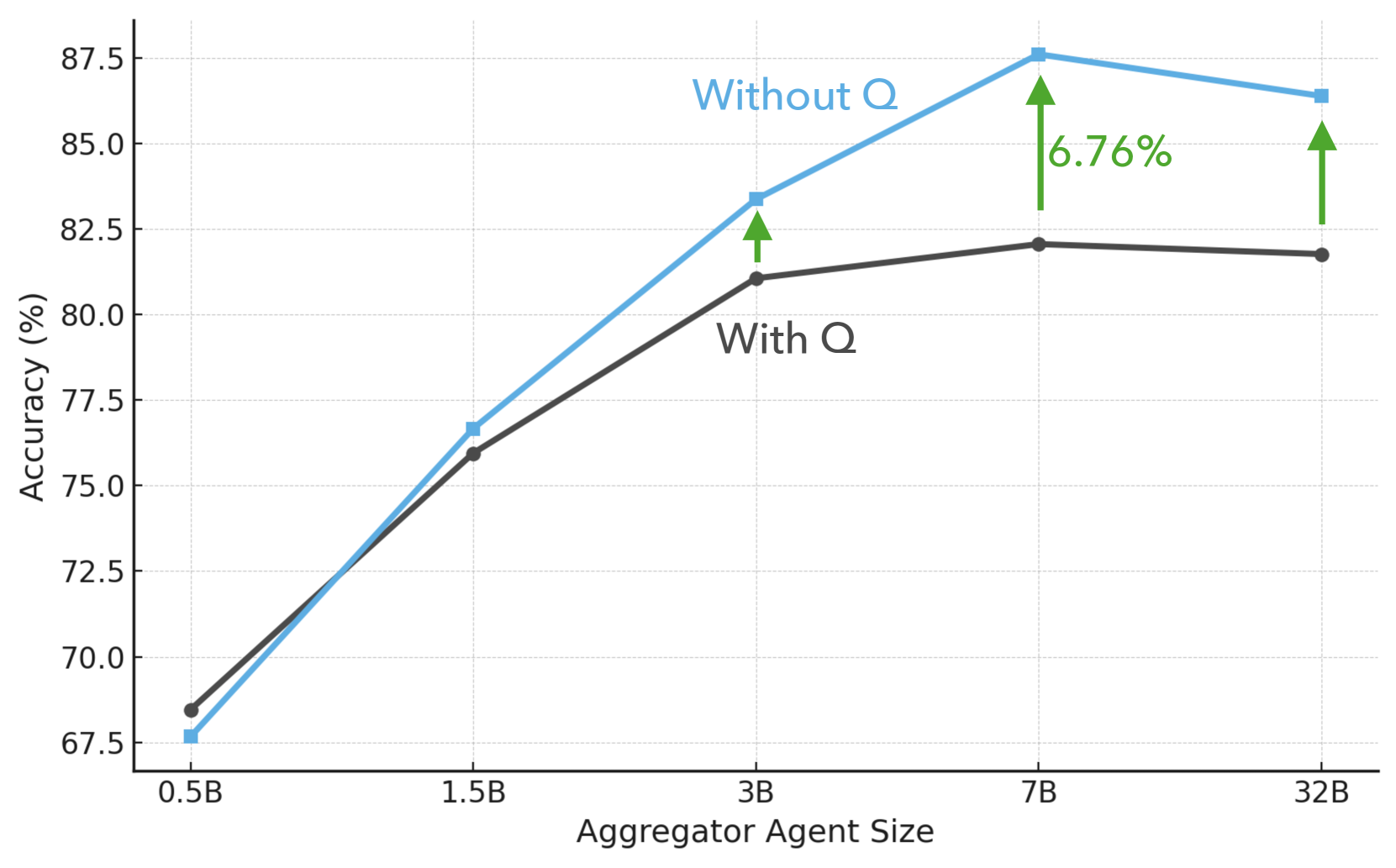
实验结果表明,MAMMQA在多个多模态问答基准测试中取得了显著的性能提升。具体的数据和对比基线在摘要中未提及,但强调了MAMMQA在准确性和鲁棒性方面均优于现有方法。这意味着MAMMQA能够更准确地理解多模态信息,并能够更好地应对噪声和干扰。
🎯 应用场景
MAMMQA框架可应用于智能客服、教育辅助、医疗诊断等领域。例如,在智能客服中,可以处理包含图片、表格等信息的复杂问题;在教育辅助中,可以帮助学生理解多模态教材;在医疗诊断中,可以辅助医生分析病人的影像资料和病历信息。该研究有助于提升人机交互的智能化水平,并为各行业提供更高效、更准确的信息服务。
📄 摘要(原文)
Recent advances in multimodal question answering have primarily focused on combining heterogeneous modalities or fine-tuning multimodal large language models. While these approaches have shown strong performance, they often rely on a single, generalized reasoning strategy, overlooking the unique characteristics of each modality ultimately limiting both accuracy and interpretability. To address these limitations, we propose MAMMQA, a multi-agent QA framework for multimodal inputs spanning text, tables, and images. Our system includes two Visual Language Model (VLM) agents and one text-based Large Language Model (LLM) agent. The first VLM decomposes the user query into sub-questions and sequentially retrieves partial answers from each modality. The second VLM synthesizes and refines these results through cross-modal reasoning. Finally, the LLM integrates the insights into a cohesive answer. This modular design enhances interpretability by making the reasoning process transparent and allows each agent to operate within its domain of expertise. Experiments on diverse multimodal QA benchmarks demonstrate that our cooperative, multi-agent framework consistently outperforms existing baselines in both accuracy and robustness.