SpecExtend: A Drop-in Enhancement for Speculative Decoding of Long Sequences
作者: Jungyoub Cha, Hyunjong Kim, Sungzoon Cho
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-05-27 (更新: 2026-01-19)
🔗 代码/项目: GITHUB
💡 一句话要点
SpecExtend:一种用于长序列推测解码的即插即用增强方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 长序列建模 注意力机制 KV缓存 语言模型加速
📋 核心要点
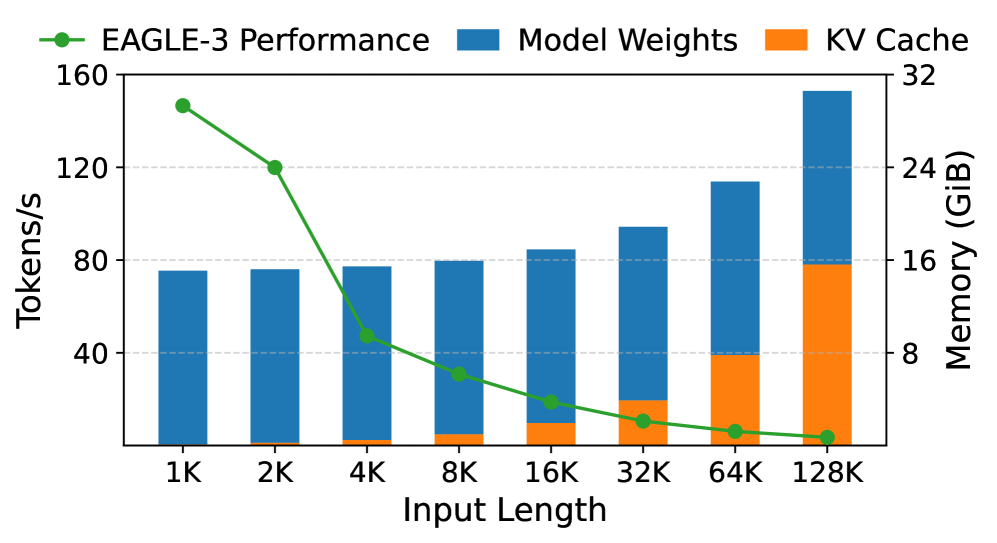
- 推测解码在长序列上的性能显著下降,但其早期退化问题未被充分研究。
- SpecExtend通过高效注意力机制和跨模型检索策略,在不重新训练的情况下提升长序列推测解码的准确性和速度。
- 实验表明,SpecExtend在长文档摘要和长篇推理任务上显著加速推测解码,同时保持短序列性能。
📝 摘要(中文)
推测解码是一种广泛应用于加速大型语言模型(LLM)推理的技术,但其性能会随着输入长度的增加而下降,即使在中等长度下也会出现显著下降。然而,这种早期退化在很大程度上仍未被探索。我们引入了SpecExtend,这是一种即插即用的增强方法,可以在不进行额外训练的情况下改进长序列的推测解码。SpecExtend集成了高效的注意力机制,如FlashAttention和混合树注意力,以加速预填充和验证步骤。为了在不重新训练的情况下提高长输入的草稿准确性和速度,我们提出了一种新颖的KV缓存淘汰策略——跨模型检索,该策略利用目标模型的注意力分数来动态选择较小草稿模型的相关上下文。广泛的评估表明,SpecExtend在16K token的长文档摘要上加速推测解码高达2.84倍,在长篇推理上加速高达3.86倍,同时保留了最先进框架的短输入性能。我们的代码可在https://github.com/jycha98/SpecExtend 获取。
🔬 方法详解
问题定义:推测解码在处理长序列时,性能会显著下降,尤其是在输入长度适中时。现有的推测解码方法在长序列上的草稿准确率较低,导致需要更多的验证步骤,从而降低了整体的推理速度。因此,如何提高长序列推测解码的效率和准确性是一个关键问题。
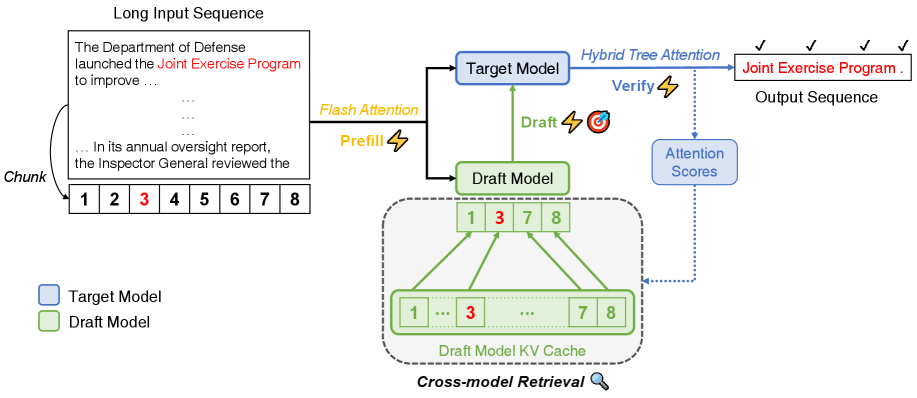
核心思路:SpecExtend的核心思路是在不重新训练模型的前提下,通过优化注意力机制和KV缓存管理来提升长序列推测解码的性能。具体来说,它利用高效的注意力机制加速预填充和验证过程,并采用跨模型检索策略动态选择草稿模型的相关上下文,从而提高草稿的准确性。
技术框架:SpecExtend主要包含两个关键组件:高效注意力机制和跨模型检索策略。高效注意力机制(如FlashAttention和混合树注意力)用于加速预填充和验证步骤,减少计算开销。跨模型检索策略则利用目标模型的注意力分数来动态选择草稿模型的相关上下文,从而提高草稿的准确性。整体流程是:首先使用高效注意力机制进行预填充,然后使用草稿模型生成草稿,接着使用目标模型验证草稿,最后使用跨模型检索策略更新草稿模型的KV缓存。
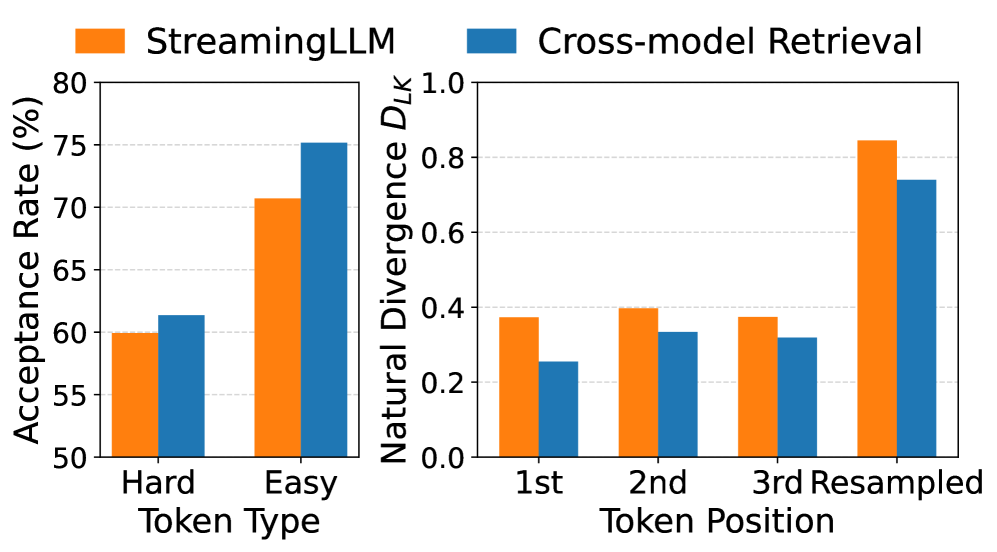
关键创新:SpecExtend的关键创新在于提出了跨模型检索策略,这是一种新颖的KV缓存淘汰策略,它利用目标模型的注意力分数来动态选择草稿模型的相关上下文。与传统的KV缓存管理方法不同,跨模型检索策略能够更准确地识别和保留对草稿生成有用的上下文信息,从而提高草稿的准确性。
关键设计:跨模型检索策略的关键设计在于如何利用目标模型的注意力分数来选择草稿模型的相关上下文。具体来说,该策略首先计算目标模型在验证阶段对每个token的注意力分数,然后根据这些分数选择与草稿模型最相关的token,并将这些token的KV缓存保留在草稿模型中。这种动态选择策略能够有效地减少草稿模型的计算负担,并提高草稿的准确性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SpecExtend在16K token的长文档摘要任务上加速推测解码高达2.84倍,在长篇推理任务上加速高达3.86倍,同时保持了与最先进框架相当的短序列性能。这些结果表明,SpecExtend是一种有效的长序列推测解码增强方法。
🎯 应用场景
SpecExtend可应用于各种需要处理长序列的自然语言处理任务,如长文档摘要、长篇问答、代码生成等。通过加速大型语言模型的推理速度,SpecExtend可以降低计算成本,提高用户体验,并促进大型语言模型在实际应用中的部署。
📄 摘要(原文)
Speculative decoding is a widely used technique for accelerating inference in large language models (LLMs), but its performance degrades as input length grows, with significant drops even at moderate lengths. Yet, this early degradation has remained largely underexplored. We introduce SpecExtend, a drop-in enhancement that improves speculative decoding on long sequences without additional training. SpecExtend integrates efficient attention mechanisms such as FlashAttention and Hybrid Tree Attention to accelerate prefill and verification steps. To improve both draft accuracy and speed on long inputs without retraining, we propose Cross-model Retrieval, a novel KV cache eviction strategy that leverages the target model's attention scores to dynamically select relevant context for the smaller draft model. Extensive evaluations show that SpecExtend accelerates speculative decoding by up to 2.84x on 16K-token long document summarization and up to 3.86x on long-form reasoning, while preserving the short-input performance of state-of-the-art frameworks. Our code is available at https://github.com/jycha98/SpecExtend .