SELF-PERCEPT: Introspection Improves Large Language Models' Detection of Multi-Person Mental Manipulation in Conversations
作者: Danush Khanna, Pratinav Seth, Sidhaarth Sredharan Murali, Aditya Kumar Guru, Siddharth Shukla, Tanuj Tyagi, Sandeep Chaurasia, Kripabandhu Ghosh
分类: cs.CL, cs.HC, cs.LG
发布日期: 2025-05-27
备注: Accepted to ACL 2025 (Main)
🔗 代码/项目: GITHUB
💡 一句话要点
SELF-PERCEPT:利用内省提升大语言模型在对话中对多人心理操纵的检测能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理操纵检测 大型语言模型 自我感知理论 多轮对话 多人对话 提示学习 自然语言处理
📋 核心要点
- 现有大语言模型难以有效识别复杂对话中细微的心理操纵行为,尤其是在多轮、多人的场景下。
- 论文提出SELF-PERCEPT框架,该框架基于自我感知理论,通过两阶段提示策略来提升模型对心理操纵的检测能力。
- 实验结果表明,SELF-PERCEPT框架在MultiManip数据集上表现出强大的性能,显著提升了模型对多人心理操纵的检测准确率。
📝 摘要(中文)
心理操纵是人际交流中一种微妙但普遍存在的虐待形式,检测此类行为对于保护潜在受害者至关重要。然而,由于操纵的细微性和情境依赖性,识别复杂、多轮和多人对话中的操纵性语言对于大型语言模型(LLMs)来说仍然是一个重大挑战。为了解决这个问题,我们引入了MultiManip数据集,该数据集包含220个多轮、多人对话,这些对话在操纵性和非操纵性互动之间保持平衡,所有对话都来自模仿现实场景的真人秀。对于操纵性互动,它包括11种不同的操纵方式,描绘了现实生活场景。我们对最先进的LLM(如GPT-4o和Llama-3.1-8B)进行了广泛的评估,采用了各种提示策略。尽管它们具有强大的能力,但这些模型通常难以有效地检测操纵行为。为了克服这一限制,我们提出了一种新颖的两阶段提示框架SELF-PERCEPT,该框架的灵感来自自我感知理论,在检测多人、多轮心理操纵方面表现出强大的性能。我们的代码和数据可在https://github.com/danushkhanna/self-percept公开获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂、多轮、多人对话中检测心理操纵行为的难题。现有方法难以捕捉操纵行为的细微性和情境依赖性,导致检测效果不佳。尤其是在多人对话中,理解角色之间的互动关系和潜在的操纵意图更具挑战性。
核心思路:论文的核心思路是借鉴自我感知理论,让模型通过“观察”对话参与者的行为和言语,并“推断”其潜在的心理状态和意图,从而更准确地识别操纵行为。SELF-PERCEPT框架模拟了人类理解他人行为的认知过程,提升了模型对操纵行为的敏感度。
技术框架:SELF-PERCEPT框架包含两个主要阶段:第一阶段是“行为观察”阶段,模型分析对话内容,识别参与者的行为和言语模式。第二阶段是“意图推断”阶段,模型基于观察到的行为和言语,推断参与者的潜在意图,并判断是否存在心理操纵行为。这两个阶段通过精心设计的提示策略进行引导,使模型能够逐步理解对话的复杂性。
关键创新:SELF-PERCEPT框架的关键创新在于将自我感知理论引入到心理操纵检测任务中。与传统的直接分类方法不同,SELF-PERCEPT框架通过模拟人类的认知过程,使模型能够更深入地理解对话的语义和语用信息,从而更准确地识别操纵行为。这种基于认知建模的方法为解决类似问题提供了新的思路。
关键设计:在“行为观察”阶段,论文设计了特定的提示语,引导模型关注对话中可能暗示操纵行为的关键词和短语。在“意图推断”阶段,论文利用了大型语言模型的推理能力,让模型基于观察到的行为和言语,推断参与者的潜在意图。此外,论文还探索了不同的提示策略和模型参数设置,以优化SELF-PERCEPT框架的性能。具体参数设置和损失函数细节未知。
🖼️ 关键图片

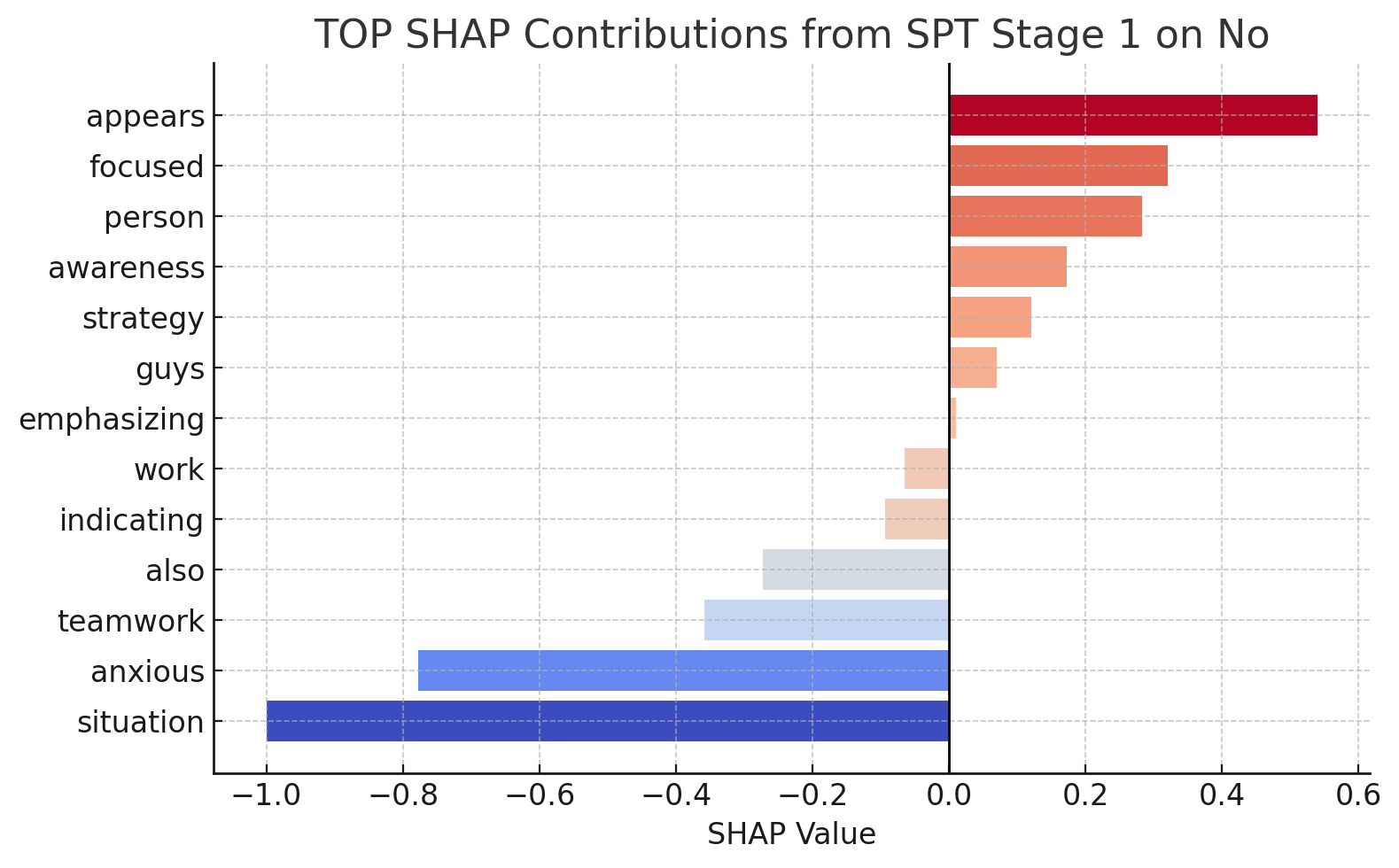
📊 实验亮点
论文提出的SELF-PERCEPT框架在MultiManip数据集上取得了显著的性能提升。实验结果表明,SELF-PERCEPT框架能够有效提高模型对多人心理操纵的检测准确率,优于直接使用大型语言模型进行分类的方法。具体的性能数据和提升幅度在论文中进行了详细的报告,但此处未提供具体数值。
🎯 应用场景
该研究成果可应用于在线社交平台、心理咨询、法律调查等领域,用于检测和预防心理操纵行为。通过自动识别对话中的操纵性语言,可以及时向潜在受害者发出警告,并为心理咨询师和执法人员提供辅助决策支持。此外,该研究还可以促进人们对心理操纵行为的认识,提高自我保护意识。
📄 摘要(原文)
Mental manipulation is a subtle yet pervasive form of abuse in interpersonal communication, making its detection critical for safeguarding potential victims. However, due to manipulation's nuanced and context-specific nature, identifying manipulative language in complex, multi-turn, and multi-person conversations remains a significant challenge for large language models (LLMs). To address this gap, we introduce the MultiManip dataset, comprising 220 multi-turn, multi-person dialogues balanced between manipulative and non-manipulative interactions, all drawn from reality shows that mimic real-world scenarios. For manipulative interactions, it includes 11 distinct manipulations depicting real-life scenarios. We conduct extensive evaluations of state-of-the-art LLMs, such as GPT-4o and Llama-3.1-8B, employing various prompting strategies. Despite their capabilities, these models often struggle to detect manipulation effectively. To overcome this limitation, we propose SELF-PERCEPT, a novel, two-stage prompting framework inspired by Self-Perception Theory, demonstrating strong performance in detecting multi-person, multi-turn mental manipulation. Our code and data are publicly available at https://github.com/danushkhanna/self-percept .