Long Context Scaling: Divide and Conquer via Multi-Agent Question-driven Collaboration
作者: Sibo Xiao, Zixin Lin, Wenyang Gao, Hui Chen, Yue Zhang
分类: cs.CL
发布日期: 2025-05-27 (更新: 2025-09-28)
💡 一句话要点
提出XpandA框架,通过多Agent协作和问题驱动,提升LLM长文本处理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 多Agent系统 问题驱动 动态分割 大型语言模型 上下文学习 知识表示
📋 核心要点
- 现有Agent分治方法处理长文本存在延迟高、信息损失大和破坏文本依赖等问题。
- XpandA框架通过动态分割、问题引导和选择性重放,实现鲁棒的长文本处理。
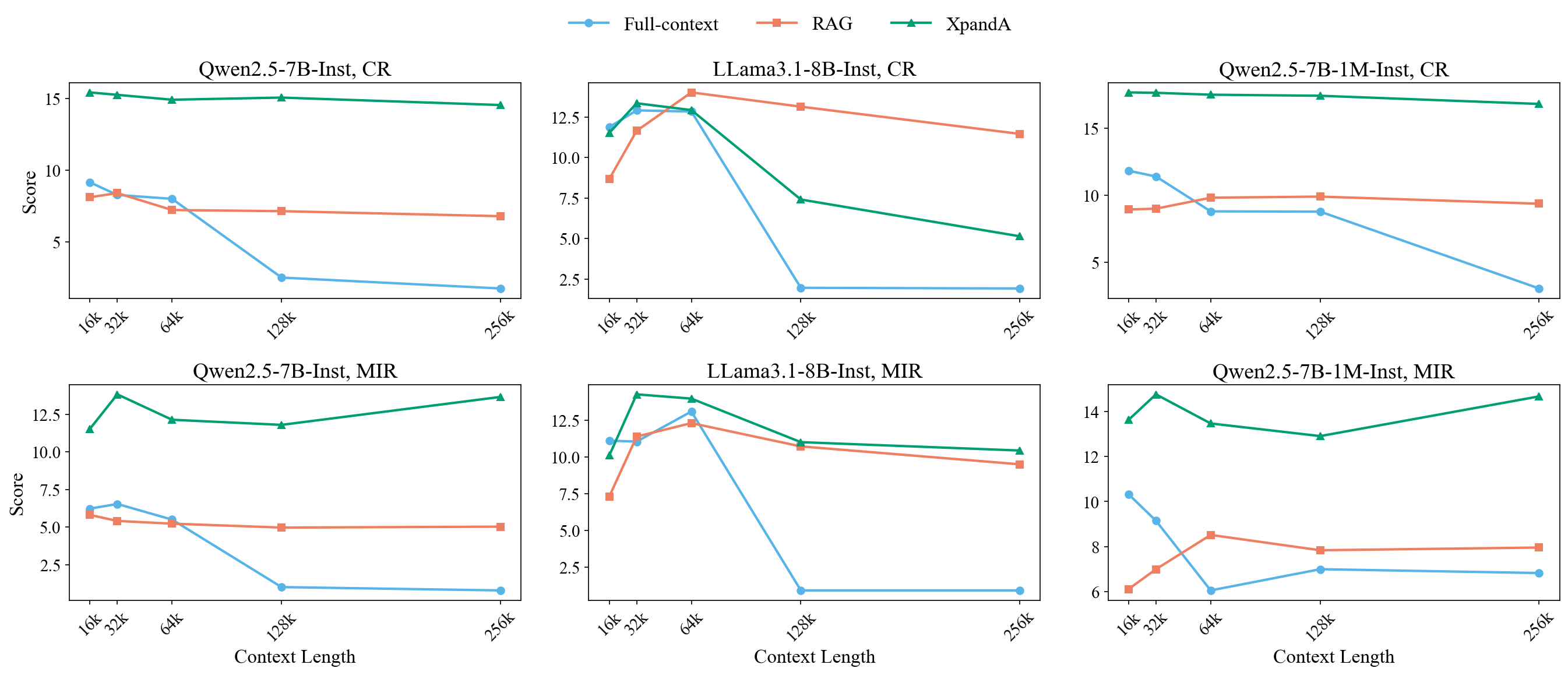
- 实验表明,XpandA在长文本基准上提升了20%的性能,并加速了1.5倍的推理速度。
📝 摘要(中文)
处理长文本上下文已成为现代大型语言模型(LLMs)的关键能力。现有工作利用基于Agent的分治方法处理长文本,但面临累积延迟过高、Agent过度调用导致信息损失放大、以及不合理的分割破坏文本固有依赖关系等关键限制。本文提出了一种新颖的多Agent框架XpandA(Expand-Agent),结合问题驱动的工作流程和动态分割,以实现鲁棒的长文本处理。XpandA通过以下方式克服这些限制:1)长文本的动态分割,自适应地调节上下文窗口的填充率,以适应长度差异巨大的输入序列;2)问题引导的协议,更新集中式共享内存中的扁平信息集合,构建跨分割的一致Agent间知识;3)基于问题-信息对的状态跟踪,选择性地重放特定分割,以促进跨分割的倒序结构(例如,闪回)的解决。我们在多个长度从1k到1M的长文本基准上对XpandA进行了全面评估,证明了XpandA处理超长序列的可行性,并通过在完整上下文、RAG和先前的基于Agent的方法的基线上实现20%的改进和1.5倍的推理加速,显著提高了各种LLM的长文本能力。
🔬 方法详解
问题定义:现有基于Agent的分治方法在处理长文本时,存在三个主要痛点:一是Agent的多次调用导致累积延迟过高;二是过度分割导致信息损失放大;三是不合理的分割破坏了文本固有的依赖关系,例如时间顺序、因果关系等。这些问题限制了LLM在需要理解和推理长文本场景下的应用。
核心思路:XpandA的核心思路是结合动态分割、问题引导和选择性重放,构建一个高效且鲁棒的多Agent协作框架。通过动态分割自适应地处理不同长度的文本,问题引导确保Agent间知识的一致性,选择性重放解决倒序结构带来的理解困难。这种设计旨在减少信息损失,降低延迟,并保持文本的内在逻辑。
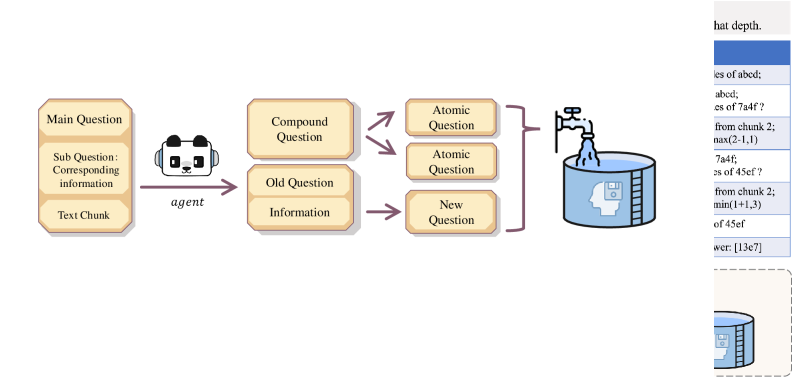
技术框架:XpandA框架包含以下几个主要模块:1)动态分割模块:根据文本长度动态调整分割策略,避免过度分割或分割不足。2)问题生成模块:根据当前文本片段生成关键问题,引导后续Agent关注重要信息。3)共享记忆模块:集中存储所有Agent提取的信息,并维护Agent间的知识一致性。4)Agent协作模块:多个Agent并行工作,根据问题和共享记忆进行信息提取和推理。5)选择性重放模块:根据问题-信息对的状态,选择性地重放特定分割,解决倒序结构带来的理解困难。
关键创新:XpandA的关键创新在于其动态分割策略和问题引导的Agent协作机制。动态分割能够自适应地处理不同长度的文本,避免了传统固定分割策略的局限性。问题引导的Agent协作机制能够确保Agent关注重要信息,并维护Agent间的知识一致性,从而减少信息损失。
关键设计:动态分割模块采用了一种自适应的填充率调整策略,根据输入序列的长度动态调整上下文窗口的大小。问题生成模块使用LLM生成与当前文本片段相关的关键问题。共享记忆模块采用扁平化的信息存储结构,方便Agent快速访问和更新信息。选择性重放模块维护了一个问题-信息对的状态跟踪表,根据该表选择性地重放特定分割。
🖼️ 关键图片

📊 实验亮点
XpandA在多个长文本基准测试中取得了显著的性能提升。与完整上下文方法相比,XpandA在性能上提升了20%,同时推理速度提升了1.5倍。此外,XpandA还优于RAG和先前的基于Agent的方法,证明了其在长文本处理方面的优越性。实验结果表明,XpandA能够有效地处理超长序列,并显著提高LLM的长文本理解能力。
🎯 应用场景
XpandA框架可应用于需要处理超长文本的各种场景,例如长篇小说理解、法律文档分析、金融报告解读、科学论文摘要等。该研究成果有助于提升LLM在这些领域的应用效果,并为开发更强大的长文本处理模型提供新的思路。
📄 摘要(原文)
Processing long contexts has become a critical capability for modern large language models (LLMs). Existing works leverage agent-based divide-and-conquer methods for processing long contexts. But these methods face crucial limitations, including prohibitive accumulated latency and amplified information loss from excessive agent invocations, and the disruption of inherent textual dependencies by immoderate partitioning. In this paper, we propose a novel multi-agent framework XpandA (Expand-Agent) coupled with question-driven workflow and dynamic partitioning for robust long-context processing. XpandA overcomes these limitations through: 1) dynamic partitioning of long texts, which adaptively modulates the filling rate of context windows for input sequences of vastly varying lengths; 2) question-guided protocol to update flat information ensembles within centralized shared memory, constructing consistent inter-agent knowledge across partitions; and 3) selectively replaying specific partitions based on the state-tracking of question-information couples to promote the resolution of inverted-order structures across partitions (e.g., flashbacks). We perform a comprehensive evaluation of XpandA on multiple long-context benchmarks with length varying from 1k to 1M, demonstrating XpandA's feasibility for processing ultra-long sequences and its significant effectiveness in enhancing the long-context capabilities of various LLMs by achieving 20\% improvements and 1.5x inference speedup over baselines of full-context, RAG and previous agent-based methods.