Estimating LLM Consistency: A User Baseline vs Surrogate Metrics
作者: Xiaoyuan Wu, Weiran Lin, Omer Akgul, Lujo Bauer
分类: cs.CL, cs.AI, cs.HC, cs.LG
发布日期: 2025-05-26 (更新: 2025-11-21)
备注: Published as a main conference paper at EMNLP 2025
DOI: 10.18653/v1/2025.emnlp-main.1554
💡 一句话要点
揭示LLM一致性度量与人类感知的偏差,提出logit集成方法提升对齐度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 一致性评估 用户研究 Logits集成 幻觉缓解
📋 核心要点
- 现有LLM一致性度量方法(如基于概率、内部状态或logits)与人类感知存在偏差,无法准确反映用户对LLM响应质量的判断。
- 论文提出一种基于logit的集成方法,旨在更准确地估计LLM响应的一致性,使其与人类的感知对齐。
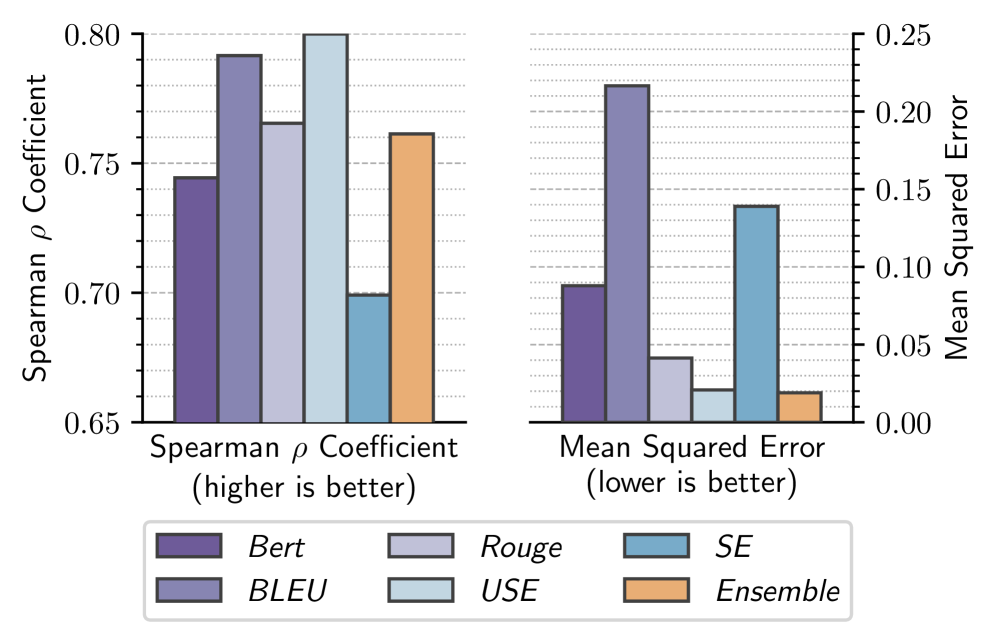
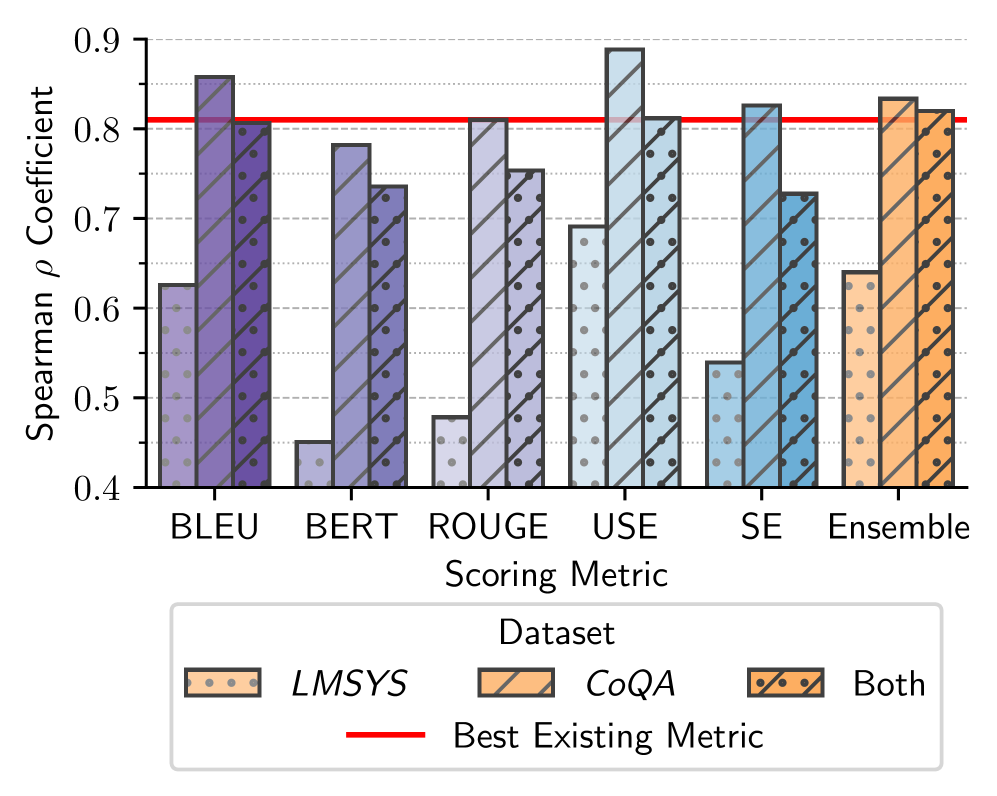
- 实验结果表明,该方法在估计人类对LLM一致性的评分方面,性能与现有最佳指标相当,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)容易产生幻觉,并且对prompt扰动敏感,导致生成文本不一致或不可靠。为了缓解这些问题,一些方法被提出,其中一种是测量LLM响应的一致性——模型对响应的置信度或重新采样时生成类似响应的可能性。以往测量LLM响应一致性的工作通常依赖于计算响应在重采样池中出现的概率、分析内部状态或评估响应的logits。然而,这些方法在多大程度上近似用户对LLM响应一致性的感知尚不清楚。为了探究这一点,我们进行了一项用户研究(n=2,976),表明当前测量LLM响应一致性的方法通常与人类对LLM一致性的感知不一致。我们提出了一种基于logit的集成方法来估计LLM一致性,并表明我们的方法在估计人类对LLM一致性的评分方面与性能最佳的现有指标相匹配。我们的结果表明,在没有人工评估的情况下估计LLM一致性的方法不够完善,因此有必要更广泛地使用人工评估;这将避免因自动化一致性指标的不完善而错误判断模型的充分性。
🔬 方法详解
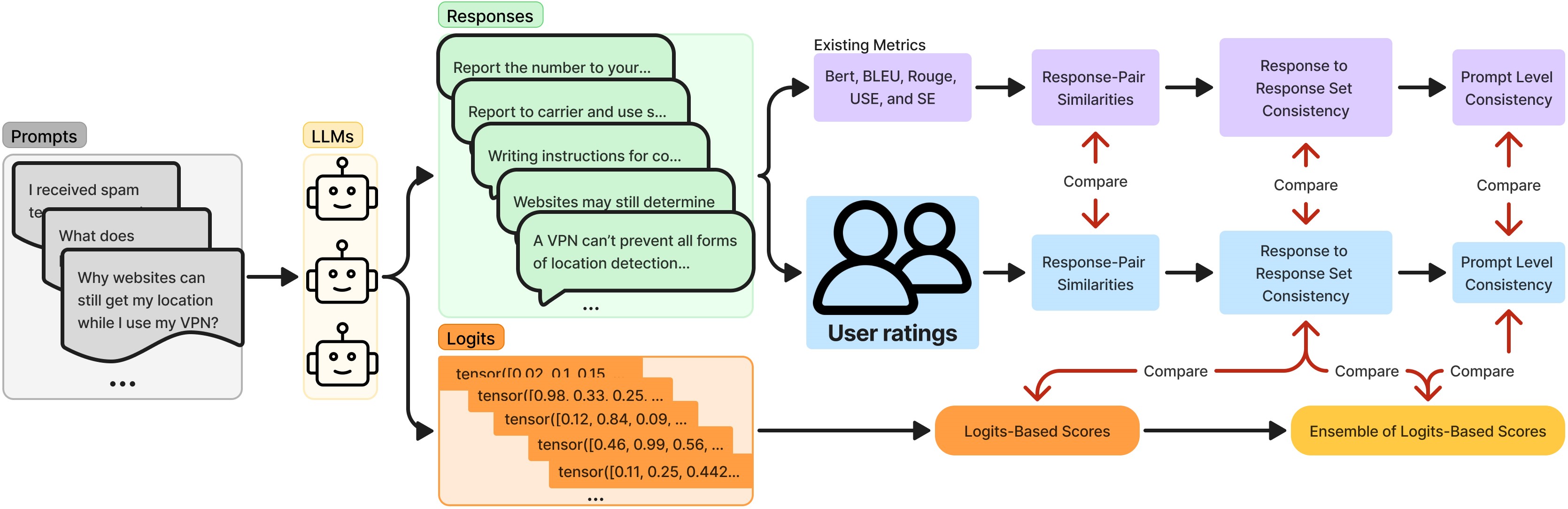
问题定义:论文旨在解决现有LLM一致性度量方法与人类感知不一致的问题。现有方法,如基于响应概率、内部状态或logits的方法,无法准确反映用户对LLM响应质量的判断,导致对LLM性能的评估产生偏差。
核心思路:论文的核心思路是利用基于logit的集成方法,综合考虑多个logits信息,从而更准确地估计LLM响应的一致性。这种方法旨在更好地捕捉人类对一致性的感知,并减少自动化评估中的偏差。
技术框架:论文提出的方法主要包括以下几个阶段:1) 对LLM进行多次采样,获得多个响应;2) 提取每个响应的logits;3) 使用集成方法(具体集成方式未知)综合多个logits信息;4) 输出一致性得分。整体框架旨在利用logits信息,通过集成学习的方式提升一致性评估的准确性。
关键创新:关键创新在于使用logit集成方法来估计LLM一致性。与以往依赖单一指标(如概率)的方法不同,该方法综合考虑了多个logits信息,从而更全面地评估LLM响应的一致性。这种集成方法能够更好地捕捉人类对一致性的感知,并减少自动化评估中的偏差。
关键设计:论文中关键的设计在于logit集成的具体方式,但摘要中并未详细说明。具体的参数设置、损失函数、网络结构等技术细节未知。未来的研究可以关注如何设计更有效的logit集成方法,以及如何优化相关参数。
🖼️ 关键图片
📊 实验亮点
用户研究表明,现有LLM一致性度量方法与人类感知存在偏差。论文提出的logit集成方法在估计人类对LLM一致性的评分方面,性能与现有最佳指标相当,表明该方法能够更准确地反映人类的感知。
🎯 应用场景
该研究成果可应用于LLM的评估和改进,帮助开发者更准确地了解LLM的性能,并针对性地进行优化。通过更准确地评估LLM的一致性,可以提高LLM在实际应用中的可靠性和用户满意度。此外,该研究也为开发更有效的人工智能评估指标提供了思路。
📄 摘要(原文)
Large language models (LLMs) are prone to hallucinations and sensitive to prompt perturbations, often resulting in inconsistent or unreliable generated text. Different methods have been proposed to mitigate such hallucinations and fragility, one of which is to measure the consistency of LLM responses -- the model's confidence in the response or likelihood of generating a similar response when resampled. In previous work, measuring LLM response consistency often relied on calculating the probability of a response appearing within a pool of resampled responses, analyzing internal states, or evaluating logits of responses. However, it was not clear how well these approaches approximated users' perceptions of consistency of LLM responses. To find out, we performed a user study ($n=2,976$) demonstrating that current methods for measuring LLM response consistency typically do not align well with humans' perceptions of LLM consistency. We propose a logit-based ensemble method for estimating LLM consistency and show that our method matches the performance of the best-performing existing metric in estimating human ratings of LLM consistency. Our results suggest that methods for estimating LLM consistency without human evaluation are sufficiently imperfect to warrant broader use of evaluation with human input; this would avoid misjudging the adequacy of models because of the imperfections of automated consistency metrics.