HAMburger: Accelerating LLM Inference via Token Smashing
作者: Jingyu Liu, Ce Zhang
分类: cs.CL
发布日期: 2025-05-26
💡 一句话要点
HAMburger:通过Token压缩加速LLM推理,实现KV缓存和计算的亚线性增长。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM推理加速 Token压缩 KV缓存优化 推测解码 分层自回归模型
📋 核心要点
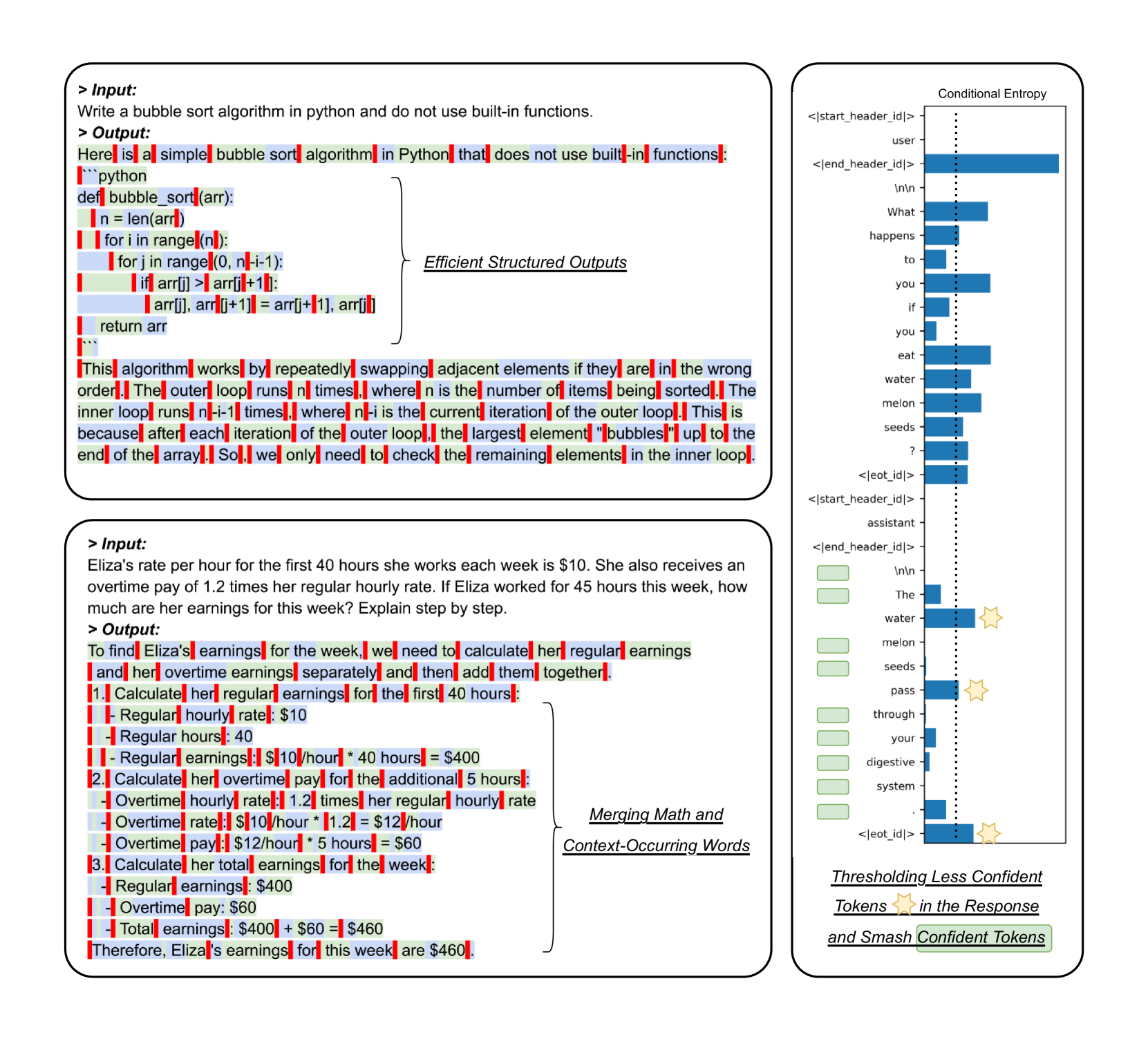
- 现有LLM推理中,每个token都需要一次前向传播和KV缓存,效率较低,未能充分利用LLM的上下文理解能力。
- HAMburger通过组合嵌入器和微步解码器,将多个token压缩成一个KV缓存,实现每个步骤生成多个token,从而减少计算和存储需求。
- 实验结果表明,HAMburger在保持质量的同时,显著降低了KV缓存计算量,并提高了推理速度,尤其是在长文本任务中。
📝 摘要(中文)
为了满足日益增长的高效大型语言模型(LLM)推理需求,需要在算法、系统和硬件层面进行整体优化。然而,很少有工作从根本上改变生成模式:每个token都需要一次前向传播和一个KV缓存。这可能不是最优的,因为我们发现LLM非常擅长自我识别单个KV缓存可以存储的精确信息量,并且许多token可以在没有全局上下文的情况下自信地生成。基于此,我们提出了HAMburger,一种分层自回归模型,它通过在推理期间超越每个token的统一计算和存储来重新定义LLM中的资源分配。HAMburger在基础LLM之间堆叠了一个组合嵌入器和一个微步解码器,将多个token压缩成一个KV,并在每个步骤生成多个token。此外,HAMburger作为一个推测解码框架,可以盲目信任自我生成的token。因此,HAMburger将KV缓存和前向FLOP的增长从相对于输出长度的线性增长转变为亚线性增长,并根据查询困惑度和输出结构调整其推理速度。广泛的评估表明,HAMburger将KV缓存计算减少高达2倍,并实现高达2倍的TPS,同时保持短上下文和长上下文任务的质量。我们的方法探索了一种极具挑战性的推理机制,该机制需要计算和内存效率,并采用与硬件无关的设计。
🔬 方法详解
问题定义:现有大型语言模型(LLM)推理过程中,每个token都需要独立进行前向传播和维护KV缓存,导致计算和存储开销随输出长度线性增长。尤其是在长文本生成场景下,这种线性增长成为性能瓶颈,限制了LLM的应用。
核心思路:HAMburger的核心思路是打破传统LLM推理中token与计算资源的1:1对应关系。它利用LLM自身对上下文信息的理解能力,将多个token压缩成一个KV缓存,从而减少KV缓存的数量和计算量。同时,HAMburger还引入了推测解码机制,允许模型盲目信任自身生成的token,进一步加速推理过程。
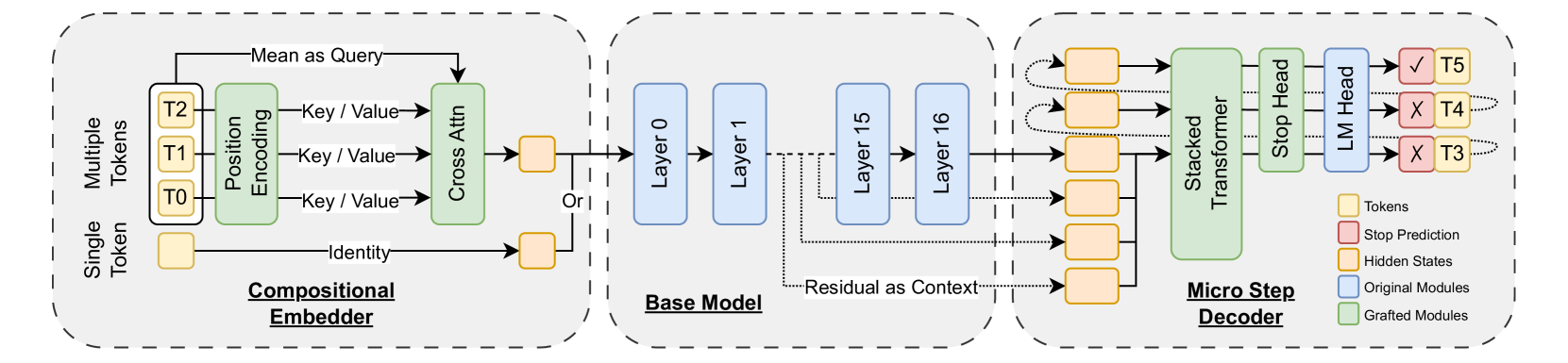
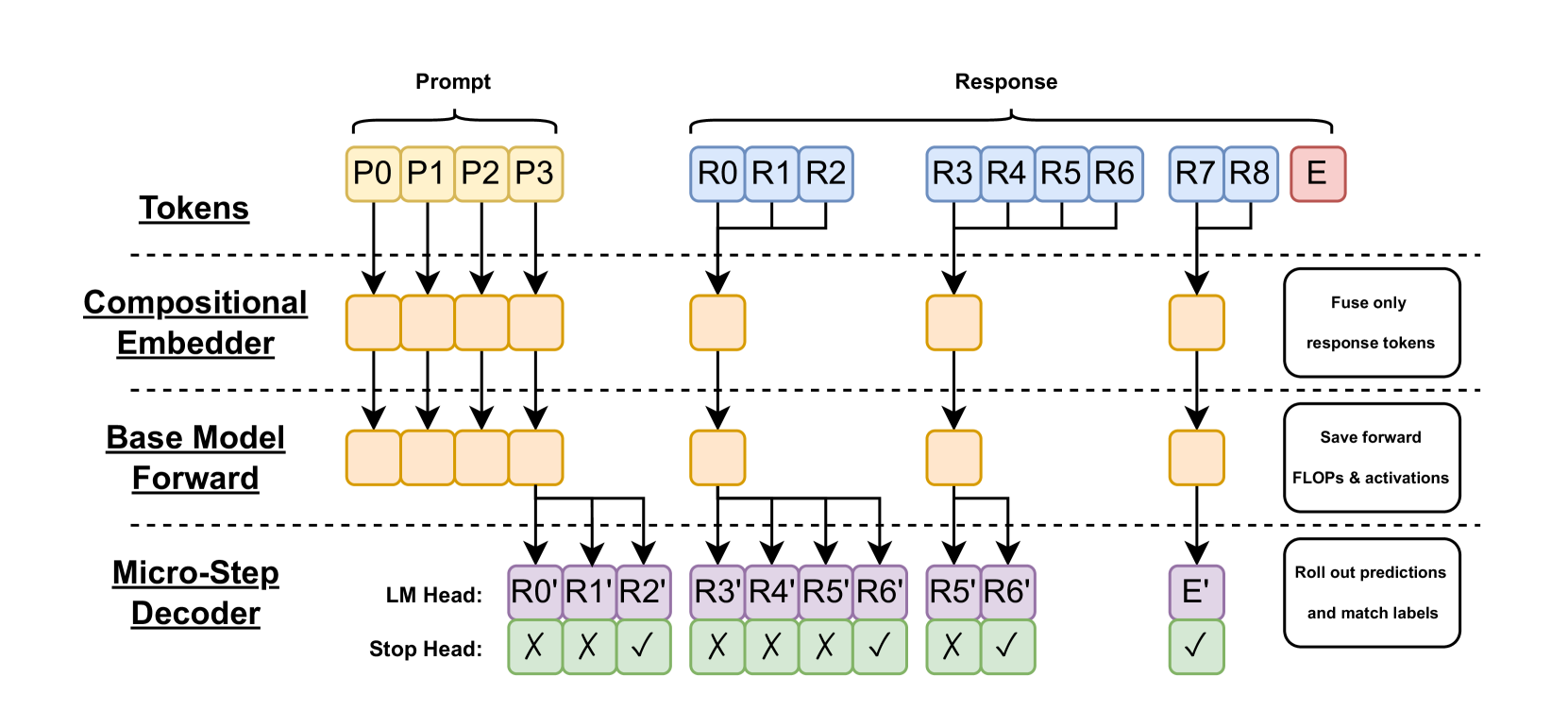
技术框架:HAMburger的整体架构包括以下几个主要模块:1) 基础LLM:作为HAMburger的基础模型,负责生成token表示。2) 组合嵌入器:将多个token压缩成一个单一的嵌入表示,用于生成KV缓存。3) 微步解码器:基于压缩后的嵌入表示,生成多个token。4) 推测解码器:验证并接受或拒绝微步解码器生成的token。
关键创新:HAMburger的关键创新在于其分层自回归模型的设计,以及token压缩和推测解码机制的引入。通过将多个token压缩成一个KV缓存,HAMburger实现了KV缓存和计算的亚线性增长,显著提高了推理效率。推测解码机制进一步加速了推理过程,允许模型在一定程度上盲目信任自身生成的token。
关键设计:HAMburger的关键设计包括:1) 组合嵌入器的结构和训练方法,用于有效地压缩多个token的信息。2) 微步解码器的设计,用于基于压缩后的嵌入表示生成多个token。3) 推测解码器的验证策略,用于平衡推理速度和生成质量。4) 损失函数的设计,用于优化HAMburger的整体性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HAMburger在KV缓存计算方面实现了高达2倍的减少,同时实现了高达2倍的TPS(每秒处理token数)提升。在短上下文和长上下文任务中,HAMburger均保持了良好的生成质量。这些结果验证了HAMburger在加速LLM推理方面的有效性。
🎯 应用场景
HAMburger具有广泛的应用前景,尤其适用于对推理速度和资源消耗有较高要求的场景,如在线对话系统、长文本生成、机器翻译等。该方法可以显著降低LLM的部署成本,并提高用户体验。未来,HAMburger有望成为加速LLM推理的重要技术手段。
📄 摘要(原文)
The growing demand for efficient Large Language Model (LLM) inference requires a holistic optimization on algorithms, systems, and hardware. However, very few works have fundamentally changed the generation pattern: each token needs one forward pass and one KV cache. This can be sub-optimal because we found that LLMs are extremely capable of self-identifying the exact dose of information that a single KV cache can store, and many tokens can be generated confidently without global context. Based on this insight, we introduce HAMburger, a Hierarchically Auto-regressive Model that redefines resource allocation in LLMs by moving beyond uniform computation and storage per token during inference. Stacking a compositional embedder and a micro-step decoder in between a base LLM, HAMburger smashes multiple tokens into a single KV and generates several tokens per step. Additionally, HAMburger functions as a speculative decoding framework where it can blindly trust self-drafted tokens. As a result, HAMburger shifts the growth of KV cache and forward FLOPs from linear to sub-linear with respect to output length, and adjusts its inference speed based on query perplexity and output structure. Extensive evaluations show that HAMburger reduces the KV cache computation by up to 2$\times$ and achieves up to 2$\times$ TPS, while maintaining quality in both short- and long-context tasks. Our method explores an extremely challenging inference regime that requires both computation- and memory-efficiency with a hardware-agnostic design.