SEMMA: A Semantic Aware Knowledge Graph Foundation Model
作者: Arvindh Arun, Sumit Kumar, Mojtaba Nayyeri, Bo Xiong, Ponnurangam Kumaraguru, Antonio Vergari, Steffen Staab
分类: cs.CL, cs.AI
发布日期: 2025-05-26 (更新: 2025-09-19)
备注: EMNLP 2025
💡 一句话要点
提出SEMMA以解决知识图谱推理中的语义不足问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 语义推理 大型语言模型 双模块设计 链接预测
📋 核心要点
- 现有知识图谱基础模型主要依赖图结构,忽视了文本属性中的语义信息,导致推理能力不足。
- SEMMA通过引入大型语言模型,系统性地整合文本语义与图结构,提升了知识推理的效果。
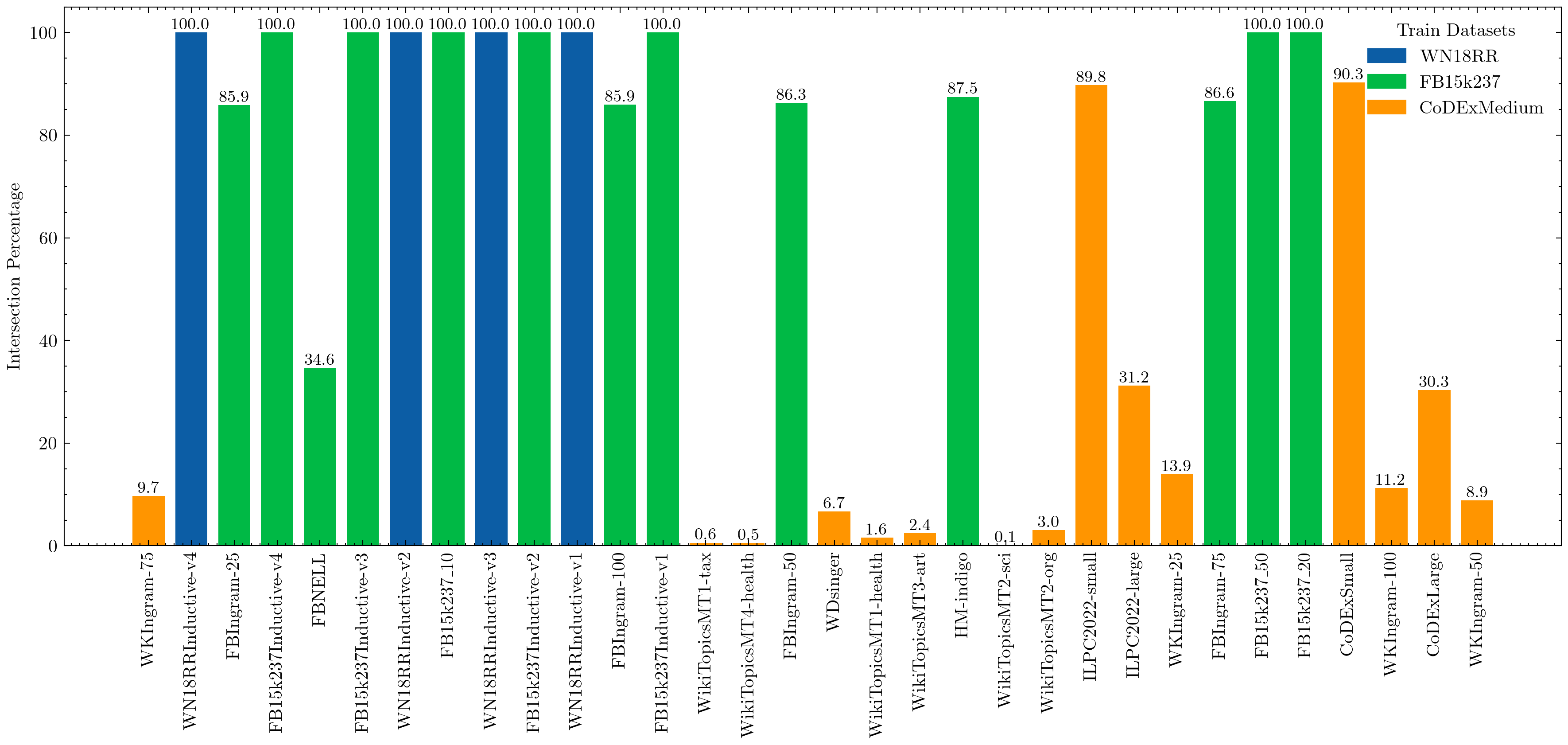
- 在54个知识图谱的实验中,SEMMA在完全归纳链接预测任务中表现优于传统结构方法,尤其在未见关系词汇的情况下效果显著提升。
📝 摘要(中文)
知识图谱基础模型(KGFMs)在实现对未见图谱的零-shot推理方面展现出潜力,但现有方法大多仅依赖图结构,忽视了文本属性中蕴含的丰富语义信号。本文提出了SEMMA,一个双模块KGFM,系统性地整合了可转移的文本语义和结构信息。SEMMA利用大型语言模型(LLMs)来丰富关系标识符,生成语义嵌入,进而形成文本关系图,并与结构组件融合。在54个不同的知识图谱上,SEMMA在完全归纳的链接预测任务中超越了纯结构基线ULTRA。尤其在测试时关系词汇完全未见的更具挑战性的泛化设置中,结构方法失效,而SEMMA的效果提升了2倍。我们的研究表明,文本语义在结构单独无法发挥作用的情况下,对于泛化能力至关重要,强调了统一结构和语言信号的基础模型在知识推理中的必要性。
🔬 方法详解
问题定义:本文旨在解决现有知识图谱基础模型在推理时对文本语义信号的忽视问题,导致在复杂场景下的泛化能力不足。
核心思路:SEMMA的核心思想是通过引入大型语言模型来丰富关系标识符,从而生成语义嵌入,并将其与图结构信息结合,以提升推理能力。
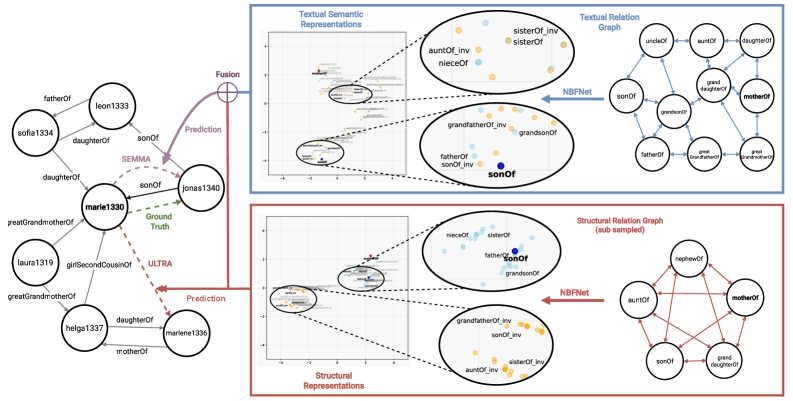
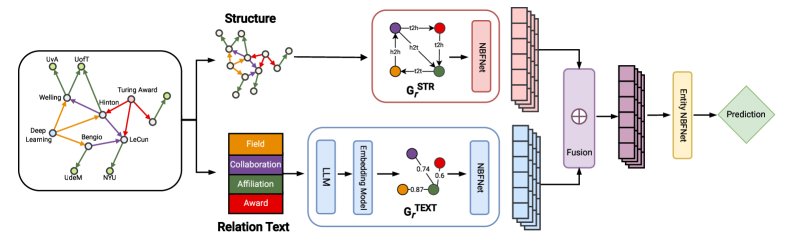
技术框架:SEMMA的整体架构包括两个主要模块:文本语义模块和结构模块。文本语义模块利用LLMs生成语义嵌入,结构模块则处理图的结构信息,最终将两者融合形成一个综合的知识图谱模型。
关键创新:SEMMA的创新在于其双模块设计,首次系统性地将文本语义与图结构结合,克服了传统方法在复杂推理任务中的局限性。
关键设计:在模型设计中,采用了特定的损失函数来优化语义嵌入与结构信息的融合效果,同时在网络结构上进行了调整,以确保模型能够有效处理多样化的知识图谱。
🖼️ 关键图片
📊 实验亮点
在实验中,SEMMA在54个知识图谱上表现出色,尤其在完全归纳的链接预测任务中,相较于传统的结构基线ULTRA,SEMMA的效果提升了2倍。这一结果表明,文本语义在复杂推理任务中的重要性,突显了SEMMA的创新价值。
🎯 应用场景
SEMMA的研究成果在多个领域具有潜在应用价值,包括智能问答系统、推荐系统和知识管理等。通过提升知识图谱的推理能力,SEMMA能够帮助系统更好地理解和处理复杂的语义关系,从而提供更准确的答案和建议。未来,随着知识图谱的不断发展,SEMMA的应用前景将更加广阔。
📄 摘要(原文)
Knowledge Graph Foundation Models (KGFMs) have shown promise in enabling zero-shot reasoning over unseen graphs by learning transferable patterns. However, most existing KGFMs rely solely on graph structure, overlooking the rich semantic signals encoded in textual attributes. We introduce SEMMA, a dual-module KGFM that systematically integrates transferable textual semantics alongside structure. SEMMA leverages Large Language Models (LLMs) to enrich relation identifiers, generating semantic embeddings that subsequently form a textual relation graph, which is fused with the structural component. Across 54 diverse KGs, SEMMA outperforms purely structural baselines like ULTRA in fully inductive link prediction. Crucially, we show that in more challenging generalization settings, where the test-time relation vocabulary is entirely unseen, structural methods collapse while SEMMA is 2x more effective. Our findings demonstrate that textual semantics are critical for generalization in settings where structure alone fails, highlighting the need for foundation models that unify structural and linguistic signals in knowledge reasoning.