MangaVQA and MangaLMM: A Benchmark and Specialized Model for Multimodal Manga Understanding
作者: Jeonghun Baek, Kazuki Egashira, Shota Onohara, Atsuyuki Miyai, Yuki Imajuku, Hikaru Ikuta, Kiyoharu Aizawa
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-05-26 (更新: 2026-01-26)
备注: EACL 2026 Findings. Project page: https://manga109.github.io/MangaVQA_LMM/
💡 一句话要点
提出MangaVQA基准和MangaLMM模型,用于提升多模态漫画理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉问答 漫画理解 基准数据集 模型微调
📋 核心要点
- 现有LMM在理解漫画这种复杂多模态叙事形式时存在不足,缺乏专门的评估基准。
- 提出MangaVQA基准和MangaLMM模型,专注于视觉问答和文本识别,提升漫画理解能力。
- 实验表明,MangaLMM在漫画理解任务上表现出色,为该领域的研究提供了新的起点。
📝 摘要(中文)
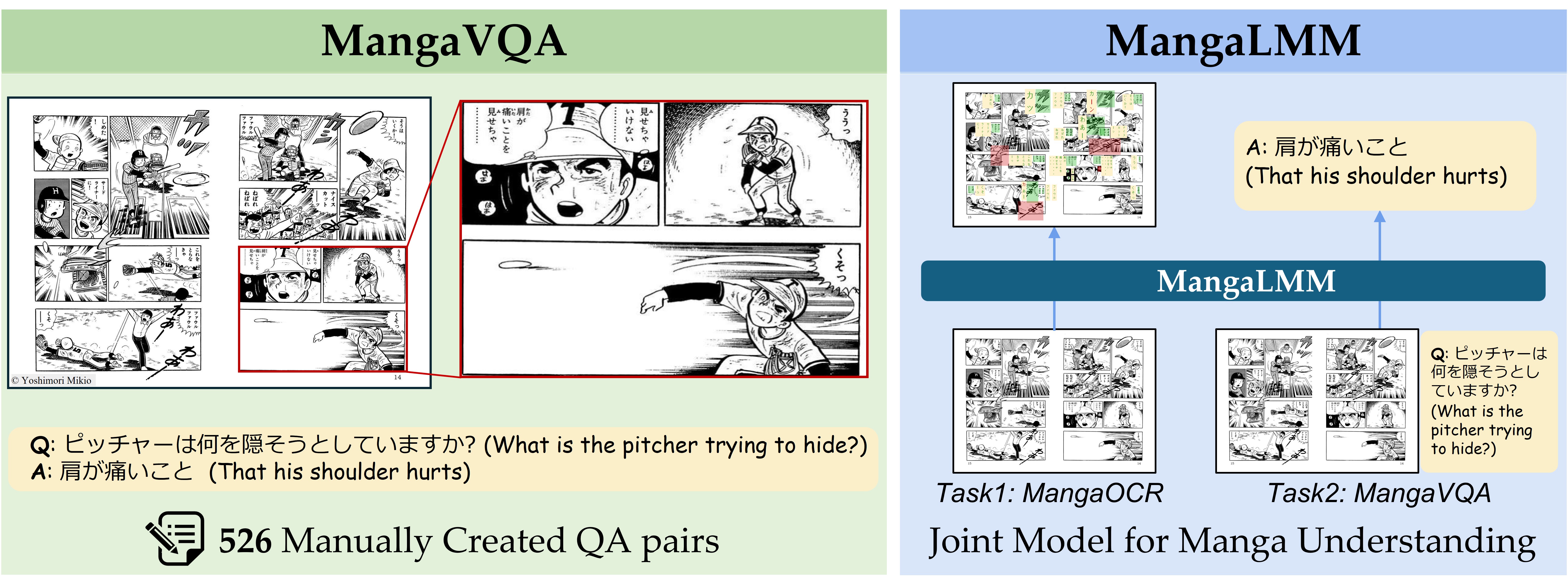
本文针对漫画这种富含多模态信息的叙事形式,提出了两个基准数据集用于提升大型多模态模型(LMMs)的理解能力。MangaOCR专注于漫画内文本识别,而MangaVQA是一个新颖的基准,旨在通过视觉问答评估上下文理解。MangaVQA包含526个高质量、人工构建的问答对,能够可靠地评估各种叙事和视觉场景。基于这些基准,本文开发了MangaLMM,这是一个基于开源LMM Qwen2.5-VL微调的漫画专用模型,可以同时处理这两项任务。通过包括与GPT-4o和Gemini 2.5等专有模型的比较在内的大量实验,评估了LMM对漫画的理解程度。本文的基准和模型为评估和推进LMM在漫画这一富含叙事性的领域中的应用奠定了全面的基础。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型(LMMs)在理解漫画这种富含图像和文本信息的复杂叙事形式时存在的不足。现有的LMM缺乏针对漫画领域的专门训练和评估,难以准确理解漫画中的上下文信息和视觉元素。因此,需要构建专门的基准数据集和模型,以提升LMM在漫画理解方面的能力。
核心思路:论文的核心思路是构建一个高质量的漫画视觉问答(VQA)基准数据集MangaVQA,并在此基础上微调一个开源LMM,使其成为漫画领域的专用模型MangaLMM。通过MangaVQA的评估,可以更准确地了解LMM在漫画理解方面的能力。通过MangaLMM的训练,可以提升LMM对漫画的理解和推理能力。
技术框架:整体框架包含两个主要部分:基准数据集构建和模型微调。首先,人工构建MangaVQA数据集,包含高质量的漫画图像和对应的问答对。然后,选择开源LMM Qwen2.5-VL作为基础模型,使用MangaVQA数据集对其进行微调,得到MangaLMM模型。MangaLMM模型可以同时处理MangaOCR(文本识别)和MangaVQA任务。
关键创新:论文的关键创新在于提出了MangaVQA基准数据集,这是一个专门针对漫画领域的视觉问答数据集,能够更准确地评估LMM在漫画理解方面的能力。此外,通过在开源LMM上进行微调,得到了漫画专用模型MangaLMM,该模型在漫画理解任务上表现出色。与现有方法相比,MangaVQA和MangaLMM更专注于漫画领域,能够更好地捕捉漫画的特点和规律。
关键设计:MangaVQA数据集包含526个高质量、人工构建的问答对,涵盖各种叙事和视觉场景。问题设计注重上下文理解和推理能力。MangaLMM模型基于Qwen2.5-VL进行微调,使用了标准的微调策略。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了MangaLMM在漫画理解任务上的有效性。虽然具体性能数据和提升幅度未在摘要中明确给出,但与GPT-4o和Gemini 2.5等专有模型的比较表明,MangaLMM在漫画理解方面具有竞争力,为后续研究奠定了基础。
🎯 应用场景
该研究成果可应用于漫画创作辅助、漫画内容推荐、漫画自动翻译等领域。通过提升LMM对漫画的理解能力,可以帮助漫画创作者更好地反思和完善他们的故事,为读者提供更优质的漫画内容,并促进漫画文化的传播。
📄 摘要(原文)
Manga, or Japanese comics, is a richly multimodal narrative form that blends images and text in complex ways. Teaching large multimodal models (LMMs) to understand such narratives at a human-like level could help manga creators reflect on and refine their stories. To this end, we introduce two benchmarks for multimodal manga understanding: MangaOCR, which targets in-page text recognition, and MangaVQA, a novel benchmark designed to evaluate contextual understanding through visual question answering. MangaVQA consists of 526 high-quality, manually constructed question-answer pairs, enabling reliable evaluation across diverse narrative and visual scenarios. Building on these benchmarks, we develop MangaLMM, a manga-specialized model finetuned from the open-source LMM Qwen2.5-VL to jointly handle both tasks. Through extensive experiments, including comparisons with proprietary models such as GPT-4o and Gemini 2.5, we assess how well LMMs understand manga. Our benchmark and model provide a comprehensive foundation for evaluating and advancing LMMs in the richly narrative domain of manga.