One-shot Entropy Minimization
作者: Zitian Gao, Lynx Chen, Haoming Luo, Joey Zhou, Bryan Dai
分类: cs.CL
发布日期: 2025-05-26 (更新: 2025-08-21)
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出单样本熵最小化方法,仅需少量数据即可显著提升大语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练 熵最小化 单样本学习 无监督学习
📋 核心要点
- 现有基于规则的强化学习方法在后训练大语言模型时,需要大量数据和精细设计的奖励函数,成本高昂。
- 论文提出单样本熵最小化方法,通过最小化模型在单个未标记数据上的熵,引导模型生成更一致和可预测的输出。
- 实验表明,该方法仅需少量数据和优化步骤,即可达到甚至超过传统强化学习方法的性能提升。
📝 摘要(中文)
我们训练了13440个大型语言模型,发现熵最小化只需要一个未标记数据和10步优化,就能实现与使用数千个数据和精心设计的基于规则的强化学习奖励相当甚至更好的性能提升。这一惊人的结果可能会促使人们重新思考大型语言模型的后训练范式。我们的代码可在https://github.com/zitian-gao/one-shot-em 获取。
🔬 方法详解
问题定义:现有的大语言模型后训练方法,特别是基于强化学习的方法,通常需要大量标注或未标注数据,以及复杂的奖励函数设计,计算成本高昂且难以优化。论文旨在解决如何以更高效的方式,利用极少量数据提升大语言模型的性能,降低后训练的成本和复杂度。
核心思路:论文的核心思路是利用熵最小化原理。熵是衡量模型输出不确定性的指标,熵越小,模型输出越确定。通过最小化模型在少量未标记数据上的熵,可以引导模型生成更一致、更可预测的输出,从而提升模型的性能。这种方法避免了对大量数据的依赖和复杂奖励函数的设计。
技术框架:该方法的核心流程是:1)选择一个未标记的数据样本;2)使用大语言模型生成该样本的输出;3)计算输出的熵;4)使用梯度下降等优化算法,调整模型参数,以最小化输出的熵;5)重复步骤2-4,进行少量迭代。整个过程只需要一个未标记数据样本和少量优化步骤。
关键创新:该方法最重要的创新点在于,它颠覆了传统后训练范式对大量数据的依赖,证明了仅使用单个未标记数据和少量优化步骤,即可通过熵最小化实现显著的性能提升。这为大语言模型的后训练提供了一种全新的、高效的思路。
关键设计:关键设计包括:1)选择合适的熵度量方式,例如交叉熵;2)选择合适的优化算法,例如Adam;3)设置合适的学习率和迭代次数。论文中具体使用的参数设置未知,但强调了少量迭代(10步)即可取得良好效果。
🖼️ 关键图片
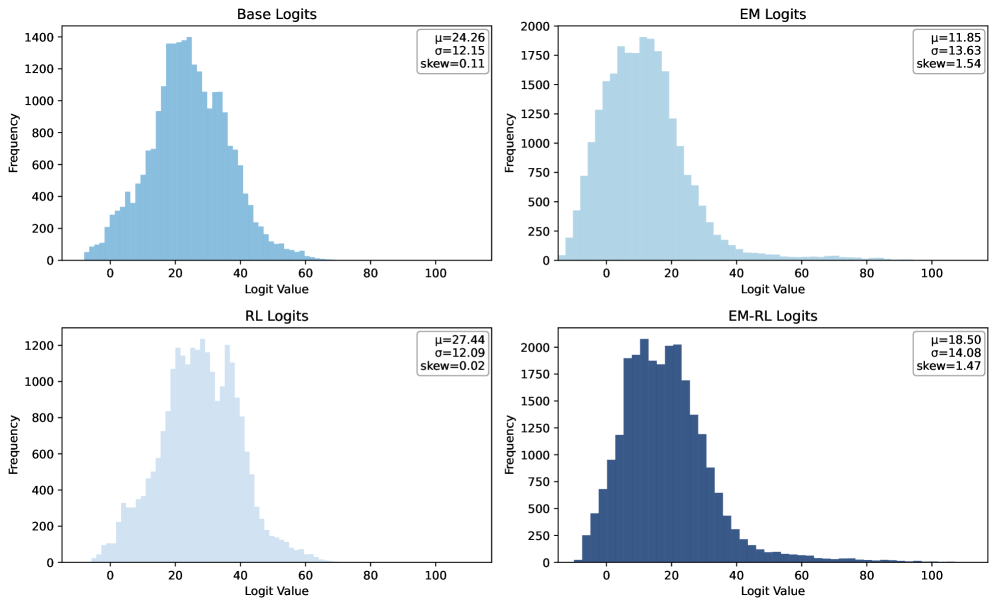

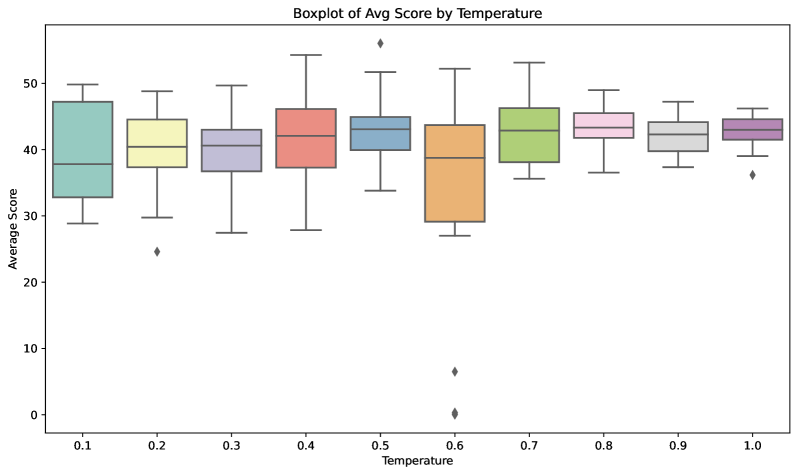
📊 实验亮点
实验结果表明,仅使用一个未标记数据和10步优化,单样本熵最小化方法即可实现与使用数千个数据和精心设计的基于规则的强化学习奖励相当甚至更好的性能提升。这一结果突显了该方法的高效性和潜力,为大语言模型的后训练提供了一种极具吸引力的替代方案。
🎯 应用场景
该研究成果可广泛应用于大语言模型的后训练和微调,尤其是在数据资源有限或计算资源受限的场景下。例如,可以用于快速提升特定领域模型的性能,或在边缘设备上部署更高效的模型。该方法也有助于降低大语言模型的训练成本,加速其在各行业的应用。
📄 摘要(原文)
We trained 13,440 large language models and found that entropy minimization requires only a single unlabeled data and 10 steps optimization to achieve performance improvements comparable to or even greater than those obtained using thousands of data and carefully designed rewards in rule-based reinforcement learning. This striking result may prompt a rethinking of post-training paradigms for large language models. Our code is avaliable at https://github.com/zitian-gao/one-shot-em.