Does quantization affect models' performance on long-context tasks?
作者: Anmol Mekala, Anirudh Atmakuru, Yixiao Song, Marzena Karpinska, Mohit Iyyer
分类: cs.CL, cs.AI
发布日期: 2025-05-26 (更新: 2025-09-20)
备注: to appear in EMNLP 2025
💡 一句话要点
系统评估量化对长文本LLM性能的影响,揭示任务、模型和量化方法的依赖性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 长文本 大语言模型 性能评估 低比特量化
📋 核心要点
- 现有大语言模型长文本处理面临高内存和高延迟挑战,量化虽可缓解,但性能影响未知。
- 论文系统评估了不同量化方法对长文本LLM性能的影响,着重分析任务、模型和语言的依赖性。
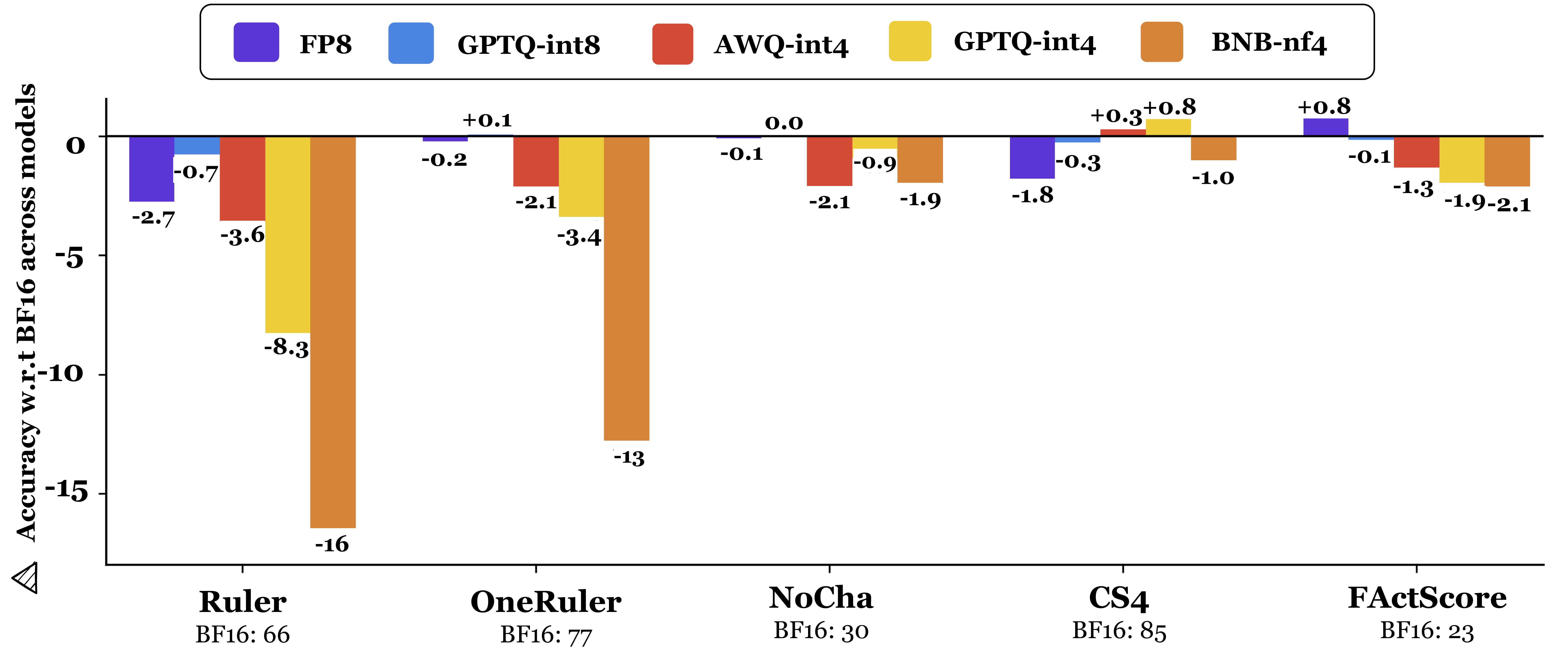
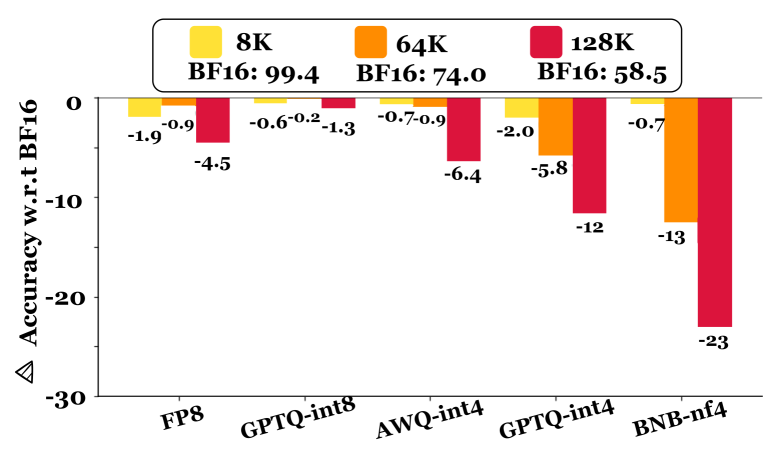
- 实验表明,8位量化损失较小,4位量化损失显著,且非英语语境下性能下降更为严重。
📝 摘要(中文)
大型语言模型(LLM)现在支持超过128K tokens的上下文窗口,但这也带来了显著的内存需求和高推理延迟。量化可以缓解这些成本,但也可能降低性能。本文首次系统地评估了量化LLM在具有长输入(>64K tokens)和长输出的任务上的表现。评估涵盖了9.7K个测试样本、五种量化方法(FP8、GPTQ-int8、AWQ-int4、GPTQ-int4、BNB-nf4)和五个模型(Llama-3.1 8B和70B;Qwen-2.5 7B、32B和72B)。研究发现,平均而言,8位量化保持了准确性(约0.8%的下降),而4位方法导致了显著的损失,特别是对于涉及长上下文输入的任务(高达59%的下降)。当输入语言不是英语时,这种性能下降的趋势会加剧。至关重要的是,量化的影响很大程度上取决于量化方法、模型和任务。例如,虽然Qwen-2.5 72B在BNB-nf4下仍然表现稳健,但Llama-3.1 70B在同一任务上的性能下降了32%。这些发现强调了在部署量化LLM之前进行仔细的、特定于任务的评估的重要性,尤其是在长上下文场景和非英语语言中。
🔬 方法详解
问题定义:论文旨在解决量化技术对长文本大语言模型性能影响评估的问题。现有方法缺乏对长文本任务下量化模型性能的系统性分析,尤其是在不同模型、量化方法和语言环境下的影响差异。现有研究无法指导用户在长文本场景下选择合适的量化策略,以平衡性能和效率。
核心思路:论文的核心思路是通过大规模实验,系统性地评估不同量化方法(FP8、GPTQ-int8、AWQ-int4、GPTQ-int4、BNB-nf4)在不同大语言模型(Llama-3.1和Qwen-2.5)处理长文本任务时的性能表现。通过对比不同量化方法、模型和任务的性能差异,揭示量化对长文本LLM性能的影响规律,并分析其内在原因。
技术框架:论文的评估框架主要包含以下几个阶段:1)选择具有代表性的长文本任务;2)选择不同的大语言模型和量化方法;3)构建包含大量测试样本的评估数据集;4)使用不同的量化模型在评估数据集上进行推理;5)分析和比较不同量化模型在不同任务上的性能表现。
关键创新:论文最重要的技术创新点在于首次对量化LLM在长文本任务上的性能进行了系统性的评估。以往的研究主要关注量化对短文本任务的影响,而忽略了长文本任务的特殊性。此外,论文还深入分析了量化方法、模型和任务之间的相互作用,揭示了量化对长文本LLM性能影响的复杂性。
关键设计:论文的关键设计包括:1)选择了多种具有代表性的长文本任务,例如文档摘要、问答等;2)选择了不同规模和架构的大语言模型,以评估量化对不同模型的影响;3)选择了多种主流的量化方法,包括8位和4位量化,以及不同的量化策略;4)构建了包含大量测试样本的评估数据集,以保证评估结果的可靠性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,8位量化对长文本LLM的性能影响较小(约0.8%的下降),而4位量化会导致显著的性能下降(高达59%)。量化的影响高度依赖于量化方法、模型和任务。例如,Qwen-2.5 72B在BNB-nf4下表现稳健,而Llama-3.1 70B在同一任务上的性能下降了32%。非英语语境下,量化带来的性能下降更为严重。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的场景,如法律文档分析、金融报告解读、科研论文理解等。通过选择合适的量化方法,可以在保证性能的前提下,显著降低模型的内存占用和推理延迟,从而实现更高效的长文本处理。该研究也为未来长文本LLM的量化技术发展提供了指导。
📄 摘要(原文)
Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long-context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and for languages other than English.