WXImpactBench: A Disruptive Weather Impact Understanding Benchmark for Evaluating Large Language Models
作者: Yongan Yu, Qingchen Hu, Xianda Du, Jiayin Wang, Fengran Mo, Renee Sieber
分类: cs.CL, cs.AI
发布日期: 2025-05-26 (更新: 2025-10-28)
备注: Accepted by ACL 2025
💡 一句话要点
WXImpactBench:构建天气灾害影响理解基准,评估大语言模型在气候适应中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 气候变化适应 灾害性天气影响 基准测试 多标签分类
📋 核心要点
- 现有方法缺乏高质量的灾害性天气影响数据集和评估基准,难以有效评估大语言模型在此领域的应用潜力。
- 论文提出WXImpactBench基准,通过四阶段流程构建数据集,并设计多标签分类和排序问答任务评估LLMs。
- 实验评估了一系列LLMs,揭示了在开发灾害性天气影响理解和气候变化适应系统方面存在的挑战。
📝 摘要(中文)
气候变化适应需要理解极端天气对社会的影响,大语言模型(LLMs)可能在此领域发挥作用。然而,由于高质量语料库收集困难和缺乏可用基准,LLMs的有效性尚未得到充分探索。区域报纸中记录的气候相关事件反映了社区如何适应和从灾害中恢复。但是,原始语料库的处理并非易事。本研究首先开发了一个具有四阶段精心构建流程的灾害性天气影响数据集。然后,我们提出了WXImpactBench,这是第一个用于评估LLMs在灾害性天气影响方面能力的基准。该基准涉及两个评估任务:多标签分类和基于排序的问答。对一系列LLMs进行评估的广泛实验,为开发灾害性天气影响理解和气候变化适应系统提供了第一手分析。构建的数据集和评估框架的代码可用于帮助社会防范灾害带来的脆弱性。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在理解和应对灾害性天气影响方面的能力评估问题。现有方法缺乏高质量的、专门针对该领域的数据集和基准,导致无法有效评估LLMs在气候变化适应方面的潜力。原始的报纸语料库虽然包含相关信息,但处理起来非常复杂,需要进行清洗、标注和组织。
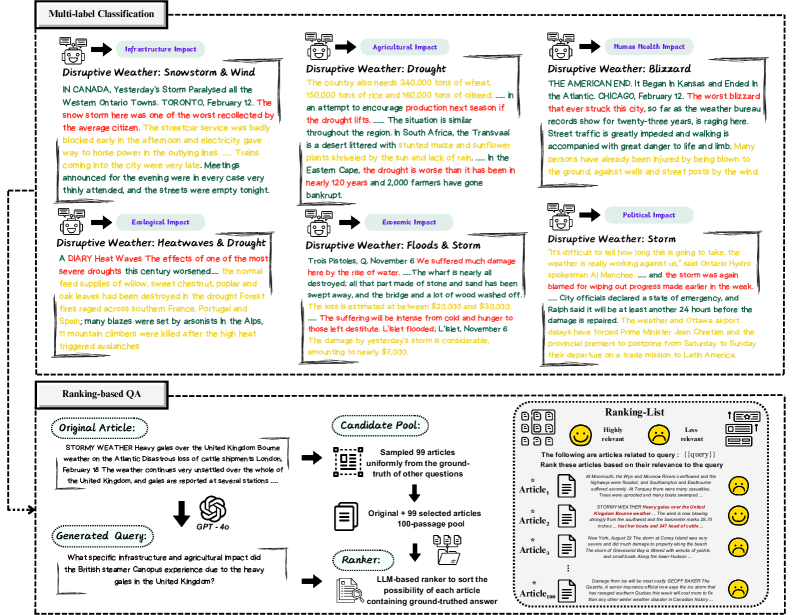
核心思路:论文的核心思路是构建一个专门用于评估LLMs在灾害性天气影响理解能力的基准,即WXImpactBench。该基准包含一个精心构建的数据集和两个评估任务:多标签分类和基于排序的问答。通过这两个任务,可以全面评估LLMs对灾害性天气事件的理解、分类和推理能力。
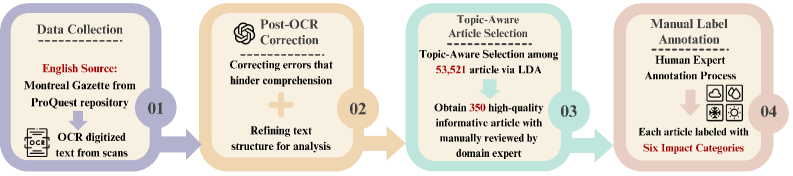
技术框架:WXImpactBench的构建包含以下几个主要阶段: 1. 数据收集:从区域报纸中收集与气候相关的事件记录。 2. 数据清洗和预处理:对收集到的数据进行清洗、去重和格式化。 3. 数据标注:使用专家知识对数据进行标注,包括事件类型、影响范围等。 4. 基准构建:基于标注后的数据,构建多标签分类和排序问答任务。
关键创新:论文的关键创新在于构建了首个专门用于评估LLMs在灾害性天气影响理解能力的基准WXImpactBench。该基准的数据集经过精心构建,包含丰富的信息,可以有效评估LLMs在该领域的性能。此外,基准设计的两个评估任务,多标签分类和排序问答,可以从不同角度评估LLMs的能力。
关键设计:数据集构建的四阶段流程是关键设计之一,确保了数据的质量和可用性。多标签分类任务旨在评估LLMs对灾害性天气事件类型的识别能力,排序问答任务则旨在评估LLMs对事件影响和应对措施的理解能力。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于LLM模型本身的设计范畴,而非WXImpactBench基准的核心创新。
🖼️ 关键图片

📊 实验亮点
论文构建了首个灾害性天气影响理解基准WXImpactBench,并对一系列LLMs进行了评估。实验结果表明,现有LLMs在理解和应对灾害性天气影响方面仍存在挑战,例如在多标签分类和排序问答任务中表现不佳。这些结果为未来研究提供了重要的参考,指明了LLMs在气候变化适应领域的发展方向。
🎯 应用场景
该研究成果可应用于气候变化适应、灾害风险管理和应急响应等领域。通过评估和提升LLMs对灾害性天气影响的理解能力,可以帮助政府、企业和社区更好地预测、应对和减轻灾害带来的损失。未来,该基准可以促进开发更智能、更有效的气候变化适应系统,提高社会应对极端天气事件的能力。
📄 摘要(原文)
Climate change adaptation requires the understanding of disruptive weather impacts on society, where large language models (LLMs) might be applicable. However, their effectiveness is under-explored due to the difficulty of high-quality corpus collection and the lack of available benchmarks. The climate-related events stored in regional newspapers record how communities adapted and recovered from disasters. However, the processing of the original corpus is non-trivial. In this study, we first develop a disruptive weather impact dataset with a four-stage well-crafted construction pipeline. Then, we propose WXImpactBench, the first benchmark for evaluating the capacity of LLMs on disruptive weather impacts. The benchmark involves two evaluation tasks, multi-label classification and ranking-based question answering. Extensive experiments on evaluating a set of LLMs provide first-hand analysis of the challenges in developing disruptive weather impact understanding and climate change adaptation systems. The constructed dataset and the code for the evaluation framework are available to help society protect against vulnerabilities from disasters.