Improving the OOD Performance of Closed-Source LLMs on NLI Through Strategic Data Selection
作者: Joe Stacey, Lisa Alazraki, Aran Ubhi, Beyza Ermis, Aaron Mueller, Marek Rei
分类: cs.CL
发布日期: 2025-05-26 (更新: 2026-01-19)
备注: Accepted at EACL Findings 2026
💡 一句话要点
通过策略性数据选择提升闭源LLM在NLI任务上的OOD泛化性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言推理 大型语言模型 异分布泛化 数据选择 闭源模型 鲁棒性 合成数据
📋 核心要点
- 现有方法难以提升闭源LLM在NLI任务上的OOD泛化性,因为它们通常需要修改微调过程或进行大规模数据增强,这对于闭源模型不适用。
- 论文提出策略性数据选择方法,包括优先选择复杂样本和使用LLM生成更复杂的合成数据,以提升OOD性能。
- 实验表明,该方法在具有挑战性的OOD数据集和简单的OOD数据集上均有提升,并且自回归LLM比编码器模型更具鲁棒性。
📝 摘要(中文)
本文研究了微调后的大型语言模型(LLM)在自然语言推理(NLI)任务上的鲁棒性,发现微调带来的同分布(in-distribution)性能提升会导致异分布(out-of-distribution,OOD)性能的大幅下降。尽管闭源LLM被广泛使用,但目前还没有针对其API微调约束下的鲁棒性缓解方法。现有的提升鲁棒性的方法通常需要改变微调过程或进行大规模数据增强,这对于闭源模型来说是不可行或成本过高的。为了解决这个问题,我们提出策略性地选择NLI微调数据,优先考虑更复杂的例子或用LLM生成的数据替换现有的训练例子。优先考虑更复杂的训练例子可以提高在具有挑战性的OOD NLI数据集上的性能,而使用合成数据进行训练可以显著提高在更容易的OOD数据集上的性能。我们发现合成例子通常过于简单,通过提示LLM创建更复杂的合成数据,我们可以提高在简单和具有挑战性的OOD数据集上的性能。最后,我们表明,与编码器模型相比,最近的自回归LLM在分布偏移方面具有更强的鲁棒性,并且应该是未来研究的首选基线。
🔬 方法详解
问题定义:论文旨在解决闭源LLM在自然语言推理(NLI)任务中,微调后在异分布(OOD)数据上泛化能力显著下降的问题。现有提升鲁棒性的方法,如修改微调过程或大规模数据增强,由于闭源LLM的API限制和高昂成本,无法直接应用。
核心思路:论文的核心思路是通过策略性地选择微调数据来提升OOD性能,而不是改变微调过程本身。具体而言,包括优先选择更复杂的训练样本,以及使用LLM生成更具复杂性的合成数据来替换或补充现有训练数据。这样可以在不违反闭源LLM API约束的前提下,提高模型的泛化能力。
技术框架:整体框架包括以下几个阶段:1) 分析现有NLI数据集的复杂性;2) 设计策略,优先选择或生成更复杂的训练样本;3) 使用选定的数据对闭源LLM进行微调;4) 在OOD数据集上评估微调后的模型性能。其中,数据选择策略是核心模块,包括基于规则的复杂性度量和基于LLM的合成数据生成。
关键创新:最重要的创新点在于提出了针对闭源LLM的策略性数据选择方法,该方法不需要修改微调过程或进行大规模数据增强,而是通过优化训练数据的质量和多样性来提升OOD性能。与现有方法相比,该方法更具可行性和成本效益。
关键设计:关键设计包括:1) 使用启发式规则(例如句子长度、词汇多样性)来衡量NLI样本的复杂性,并优先选择更复杂的样本进行微调;2) 通过提示工程,引导LLM生成更复杂的合成NLI样本,例如要求LLM生成包含更多否定词、条件语句或假设的样本;3) 实验中对比了不同数据选择策略对OOD性能的影响,并分析了自回归LLM和编码器模型在鲁棒性方面的差异。
🖼️ 关键图片
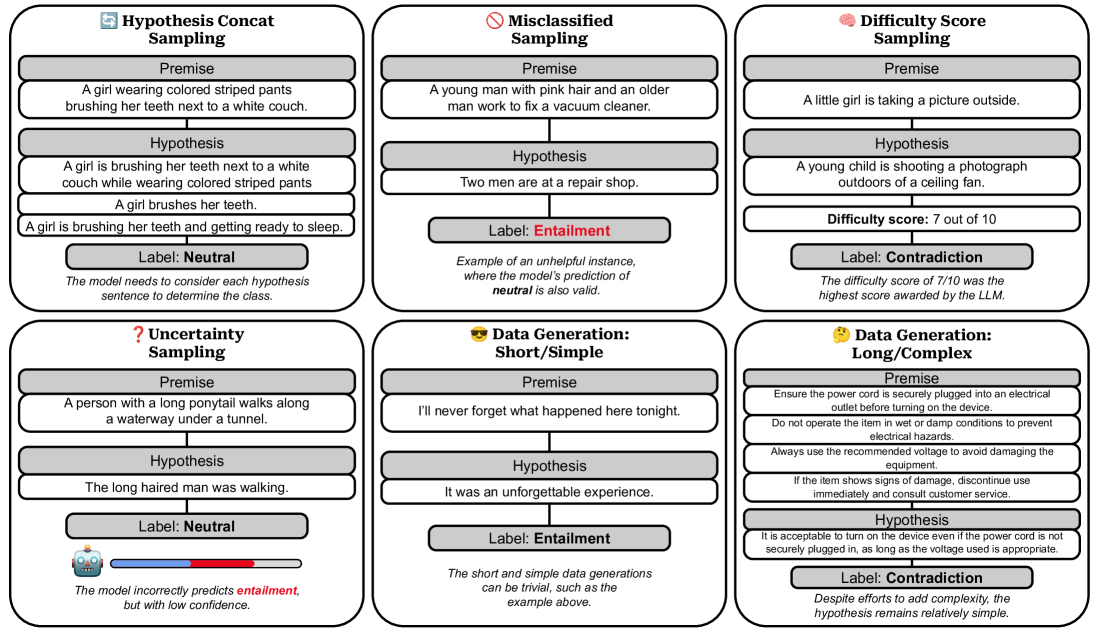

📊 实验亮点
实验结果表明,优先选择复杂样本进行微调可以提升在具有挑战性的OOD NLI数据集上的性能,而使用LLM生成的合成数据可以显著提高在简单的OOD数据集上的性能。通过提示LLM生成更复杂的合成数据,可以在简单和具有挑战性的OOD数据集上都获得提升。此外,实验还发现,自回归LLM比编码器模型更具鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要使用闭源LLM进行自然语言理解和推理的场景,例如智能客服、情感分析、文本蕴含识别等。通过提升LLM的OOD泛化能力,可以减少模型在实际应用中出现错误或偏差的可能性,提高系统的可靠性和用户体验。此外,该方法也为其他受API约束的模型的鲁棒性提升提供了借鉴。
📄 摘要(原文)
We investigate the robustness of fine-tuned Large Language Models (LLMs) for the task of Natural Language Inference (NLI), finding that the in-distribution gains from fine-tuning correspond to a large drop in out-of-distribution (OOD) performance. Despite the widespread use of closed-source LLMs, there are no robustness mitigation methods that work under their API fine-tuning constraints. Existing methods to improve robustness typically require changing the fine-tuning process or large-scale data augmentation, methods that are infeasible or cost prohibitive for closed-source models. To address this, we propose strategically selecting the NLI fine-tuning data, prioritising more complex examples or replacing existing training examples with LLM-generated data. Prioritising more complex training examples improves performance on challenging OOD NLI datasets, while training with synthetic data leads to substantial improvements on easier OOD datasets. We find that synthetic examples are often too simple, and by prompting LLMs to create more complex synthetic data we can improve performance on both easy and challenging OOD datasets. Finally, we show that recent autoregressive LLMs are substantially more robust to distributional shifts compared to encoder models, and should be a preferred baseline for future research.