Thinking with Visual Abstract: Enhancing Multimodal Reasoning via Visual Abstraction
作者: Dairu Liu, Ziyue Wang, Minyuan Ruan, Fuwen Luo, Chi Chen, Peng Li, Yang Liu
分类: cs.CL
发布日期: 2025-05-26 (更新: 2025-12-15)
💡 一句话要点
提出视觉抽象思维(VAT)方法,提升多模态大语言模型在视觉推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉推理 视觉摘要 大语言模型 抽象思维
📋 核心要点
- 现有方法在处理多模态信息时,冗余的视觉细节会降低模型的推理性能,增加计算负担。
- 论文提出视觉抽象思维(VAT)方法,通过提供视觉摘要引导模型关注关键视觉元素,提升推理效率。
- 实验表明,VAT在视觉感知和推理任务中优于GPT-5和CoT等方法,且使用更少的token。
📝 摘要(中文)
图像通常比文本传达更丰富的细节,但也包含冗余信息,这可能会降低多模态推理性能。受人类将复杂信息抽象成简洁摘要的认知策略启发,本文提出了一种新的范式,即视觉抽象思维(VAT)。VAT通过向多模态大语言模型(MLLM)提供视觉摘要,而不是明确的语言描述或详细指导,从而实现更高效的视觉推理机制。与思维链(CoT)和工具使用等方法相比,VAT鼓励模型关注更重要的视觉元素、概念和结构特征,减少冗余信息,避免了通过冗长的中间步骤和外部知识增加推理过程的复杂性。实验结果表明,VAT能够持续提升不同MLLM在视觉感知和推理任务中的性能,平均超过GPT-5基线2.21%,优于CoT方法。此外,VAT使用更少的token,同时实现了更高的性能。这些发现突出了视觉抽象思维的有效性,并鼓励从人类认知的角度进一步探索更多样化的推理范式。
🔬 方法详解
问题定义:多模态大语言模型在处理视觉信息时,面临着图像细节冗余的问题。现有方法如CoT等,虽然试图通过引入中间步骤或外部知识来辅助推理,但反而增加了推理的复杂性,降低了效率。因此,如何让模型更有效地提取和利用关键视觉信息,是本文要解决的核心问题。
核心思路:受到人类认知过程中抽象思维的启发,论文提出使用视觉摘要来引导多模态大语言模型进行推理。视觉摘要能够去除冗余信息,突出关键视觉元素和结构特征,从而使模型能够更专注于重要的信息,提高推理效率和准确性。
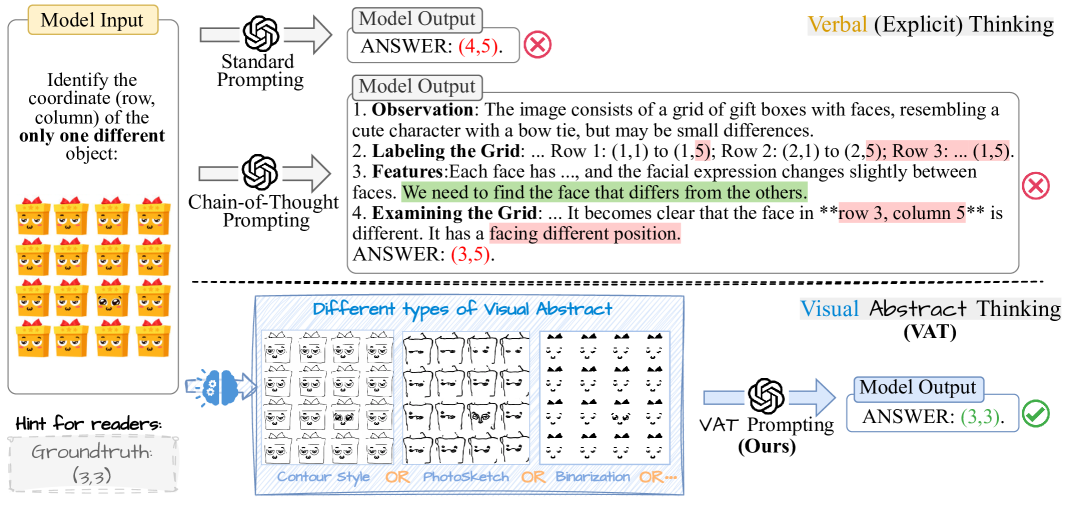
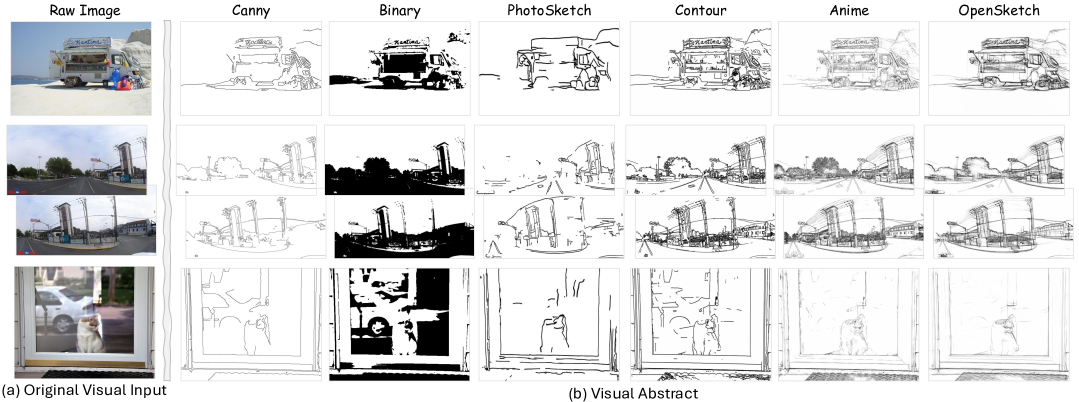
技术框架:VAT方法的核心在于使用视觉摘要作为多模态大语言模型的输入,替代原始图像或详细的文本描述。整体流程包括:1) 输入原始图像;2) 生成视觉摘要(具体生成方法未知);3) 将视觉摘要输入多模态大语言模型;4) 模型基于视觉摘要进行推理并输出结果。
关键创新:VAT方法的关键创新在于将人类的抽象思维引入到多模态大语言模型的推理过程中。与传统的CoT等方法相比,VAT避免了引入冗长的中间步骤和外部知识,而是直接通过视觉摘要引导模型关注关键信息,从而简化了推理过程,提高了效率。
关键设计:论文中并未详细描述视觉摘要的具体生成方法,以及如何针对不同的任务设计视觉摘要。这部分是实现VAT方法的关键,但具体的技术细节未知。论文侧重于验证VAT这种范式的有效性,而非具体的视觉摘要生成算法。
🖼️ 关键图片
📊 实验亮点
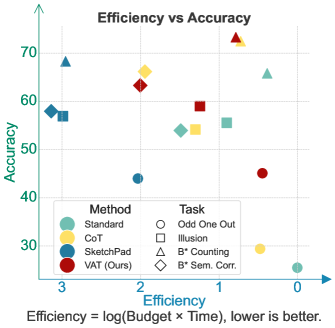
实验结果表明,VAT方法在视觉感知和推理任务中取得了显著的性能提升,平均超过GPT-5基线2.21%,并且优于CoT方法。更重要的是,VAT在实现更高性能的同时,还使用了更少的token,这表明VAT方法不仅提高了推理的准确性,还提高了推理的效率。这些结果充分证明了视觉抽象思维在多模态推理中的有效性。
🎯 应用场景
VAT方法具有广泛的应用前景,可以应用于图像理解、视觉问答、机器人导航等领域。通过提升多模态大语言模型在视觉推理任务中的性能,VAT可以帮助开发更智能、更高效的视觉系统,例如智能监控、自动驾驶、医疗影像诊断等。未来,VAT有望成为多模态人工智能领域的重要研究方向。
📄 摘要(原文)
Images usually convey richer detail than text, but often include redundant information, which potentially downgrades multimodal reasoning performance. When faced with lengthy or complex messages, humans tend to employ abstract thinking to convert them into simple and concise abstracts. Inspired by this cognitive strategy, we introduce a novel paradigm to elicit the ability to Think with Visual Abstract (VAT), by prompting Multimodal Large Language Models (MLLMs) with visual abstract instead of explicit verbal thoughts or elaborate guidance, permitting a more efficient visual reasoning mechanism via concentrated perception. VAT encourages models to focus on more essential visual elements, concepts and structural features by undermining redundant information compared with explicit thinking methods, such as Chain-of-thought (CoT) and tool-using approaches, that increase the complexity of reasoning process via inserting verbose intermediate steps and external knowledge. Experimental results show that VAT consistently empowers different MLLMs in visual perception and reasoning tasks. VAT achieves an average gain of $2.21\%$ over GPT-5 baseline, surpassing the gain of CoT, demonstrating that VAT better enhances multimodal task performance of MLLMs. Additionally, VAT spends fewer tokens while achieving higher performance. These findings highlight the effectiveness of visual abstract thinking and encourage further exploration of more diverse reasoning paradigms from the perspective of human cognition.