Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
作者: Hanting Chen, Jiarui Qin, Jialong Guo, Tao Yuan, Yichun Yin, Huiling Zhen, Yasheng Wang, Jinpeng Li, Xiaojun Meng, Meng Zhang, Rongju Ruan, Zheyuan Bai, Yehui Tang, Can Chen, Xinghao Chen, Fisher Yu, Ruiming Tang, Yunhe Wang
分类: cs.CL
发布日期: 2025-05-26
💡 一句话要点
Pangu Light:通过权重重初始化加速和压缩大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型压缩 结构化剪枝 权重重初始化 模型加速
📋 核心要点
- 现有大语言模型压缩方法在进行激进的宽度和深度剪枝时,容易导致模型性能显著下降。
- Pangu Light通过结构化剪枝和创新的权重重初始化技术,为剪枝后的模型提供更好的训练起点,从而缓解性能下降。
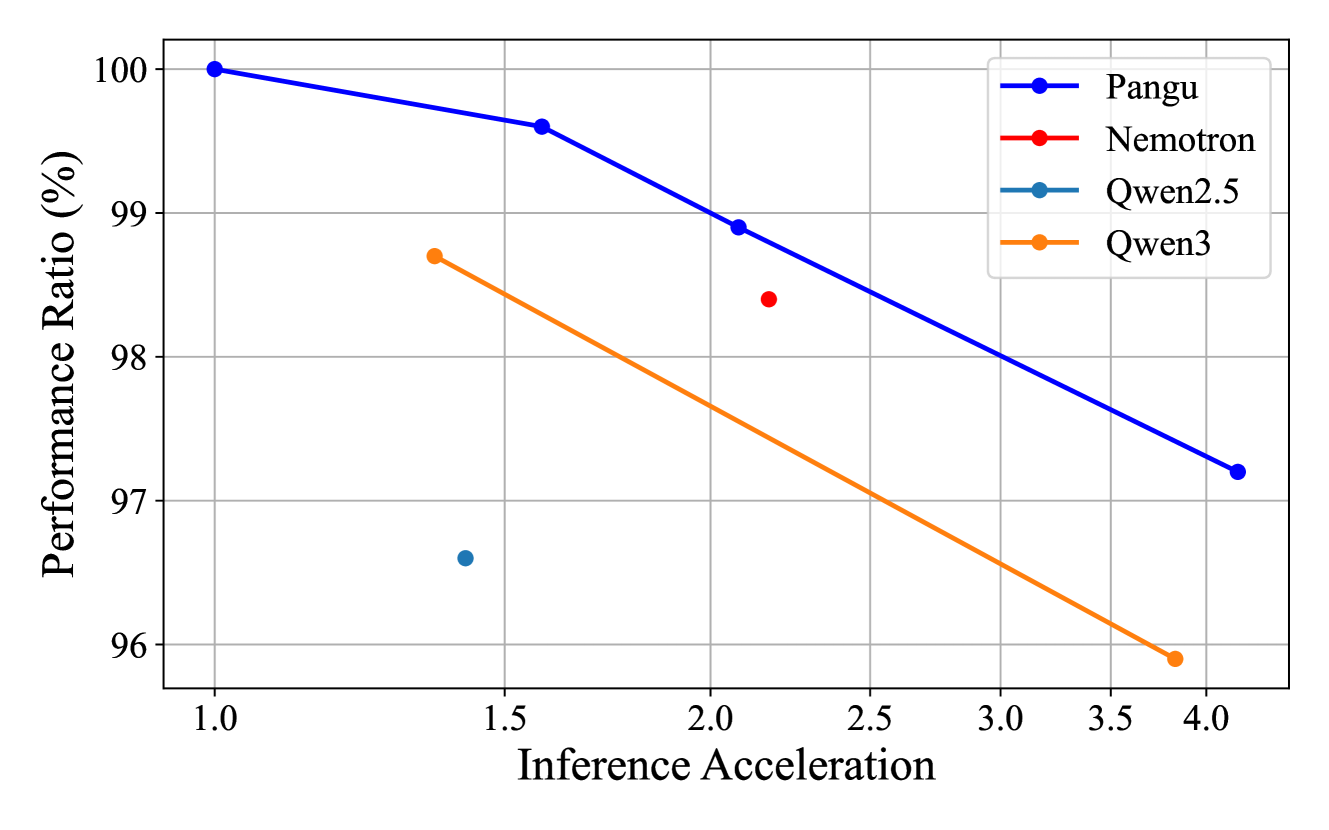
- Pangu Light在Ascend NPU上表现出卓越的精度-效率权衡,优于Nemotron和Qwen3等基线模型。
📝 摘要(中文)
大型语言模型(LLMs)在众多任务中展现了卓越的性能,但其庞大的规模和推理成本对实际部署提出了严峻的计算挑战。结构化剪枝为模型压缩提供了一条有希望的途径,但现有方法通常难以应对激进的宽度和深度同步缩减带来的不利影响,导致性能显著下降。本文认为,使这种激进的联合剪枝可行的关键在于对剩余权重进行策略性的重初始化和调整,以提高剪枝后模型的训练精度。我们提出了Pangu Light,一个以结构化剪枝为中心的LLM加速框架,结合了新颖的权重重初始化技术,旨在解决这个“缺失的一环”。我们的框架系统地针对多个维度,包括模型宽度、深度、注意力头和RMSNorm,其有效性源于诸如跨层注意力剪枝(CLAP)和稳定LayerNorm剪枝(SLNP)等新颖的重初始化方法,这些方法通过为网络提供更好的训练起点来减轻性能下降。为了进一步提高效率,Pangu Light结合了专门的优化,例如吸收Post-RMSNorm计算,并根据Ascend NPU的特性定制其策略。Pangu Light模型始终表现出卓越的精度-效率权衡,优于Nemotron等突出的基线剪枝方法和Qwen3系列等已建立的LLM。例如,在Ascend NPU上,Pangu Light-32B的81.6平均分和2585 tokens/s吞吐量超过了Qwen3-32B的80.9平均分和2225 tokens/s。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在部署时面临的计算资源挑战,特别是如何通过结构化剪枝在大幅压缩模型的同时,避免严重的性能下降。现有方法在进行激进的宽度和深度剪枝时,往往忽略了剪枝后权重初始化对模型训练的重要性,导致性能损失。
核心思路:论文的核心思路是,在结构化剪枝后,通过策略性的权重重初始化和调整,为剩余的权重提供一个更好的训练起点,从而减轻性能下降。这种重初始化策略旨在弥补因剪枝而损失的信息,并帮助模型更快地收敛到更好的局部最优解。
技术框架:Pangu Light框架主要包含以下几个阶段:1) 结构化剪枝:系统地剪除模型宽度、深度、注意力头和RMSNorm等多个维度的冗余参数。2) 权重重初始化:采用创新的重初始化方法,如CLAP和SLNP,对剩余权重进行初始化。3) 优化:结合特定硬件(Ascend NPU)的优化,如吸收Post-RMSNorm计算。4) 微调:对剪枝后的模型进行微调,以恢复性能。
关键创新:论文的关键创新在于提出了两种新颖的权重重初始化方法:Cross-Layer Attention Pruning (CLAP) 和 Stabilized LayerNorm Pruning (SLNP)。CLAP可能涉及跨层信息传递以补偿剪枝造成的注意力机制损失,而SLNP则专注于稳定LayerNorm层的训练过程,从而提高剪枝后模型的性能。与现有方法相比,Pangu Light更加关注剪枝后的权重初始化,并针对性地设计了重初始化策略。
关键设计:论文的关键设计包括:1) 针对不同维度的结构化剪枝策略。2) CLAP和SLNP的具体实现细节(论文中可能包含,但摘要未明确说明)。3) 针对Ascend NPU的优化策略,例如Post-RMSNorm计算的吸收。4) 微调过程中的学习率、batch size等超参数设置。
🖼️ 关键图片


📊 实验亮点
Pangu Light模型在Ascend NPU上表现出卓越的精度-效率权衡。例如,Pangu Light-32B的平均分为81.6,吞吐量为2585 tokens/s,超过了Qwen3-32B的80.9平均分和2225 tokens/s。这表明Pangu Light在保证模型性能的同时,显著提高了推理速度。
🎯 应用场景
Pangu Light的研究成果可应用于各种需要部署大语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过模型压缩和加速,可以降低推理成本,提高用户体验,并促进大语言模型在更广泛领域的应用,例如智能助手、自然语言处理、机器翻译等。
📄 摘要(原文)
Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.