ResSVD: Residual Compensated SVD for Large Language Model Compression
作者: Haolei Bai, Siyong Jian, Tuo Liang, Yu Yin, Huan Wang
分类: cs.CL, cs.AI
发布日期: 2025-05-26 (更新: 2025-12-19)
💡 一句话要点
ResSVD:一种残差补偿的SVD大语言模型压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 奇异值分解 低秩近似 残差补偿 模型优化
📋 核心要点
- 现有基于SVD的LLM压缩方法忽略了截断残差,导致信息损失,且对所有层进行压缩会造成严重的性能下降。
- ResSVD利用截断过程中的残差矩阵来补偿截断损失,并选择性地压缩模型的最后几层以减少误差传播。
- 在多个LLM和数据集上的实验表明,ResSVD优于现有方法,证明了其有效性和实用性。
📝 摘要(中文)
大型语言模型(LLM)在各种下游自然语言处理任务中表现出令人印象深刻的能力。然而,它们庞大的规模和内存需求阻碍了实际部署,突显了开发高效压缩策略的重要性。奇异值分解(SVD)将矩阵分解为正交分量,从而实现高效的低秩近似。这特别适用于LLM压缩,因为权重矩阵通常表现出显著的冗余。然而,当前基于SVD的方法忽略了截断产生的残差矩阵,导致显著的截断损失。此外,压缩模型的所有层会导致严重的性能下降。为了克服这些限制,我们提出ResSVD,一种新的基于后训练SVD的LLM压缩方法。具体来说,我们利用截断过程中产生的残差矩阵来减少截断损失。此外,在固定的总体压缩率下,我们有选择地压缩模型的最后几层,这可以减轻误差传播并显著提高压缩模型的性能。对不同LLM系列和多个基准数据集的ResSVD的全面评估表明,ResSVD始终优于现有的同类方法,证明了其在实践中的有效性。
🔬 方法详解
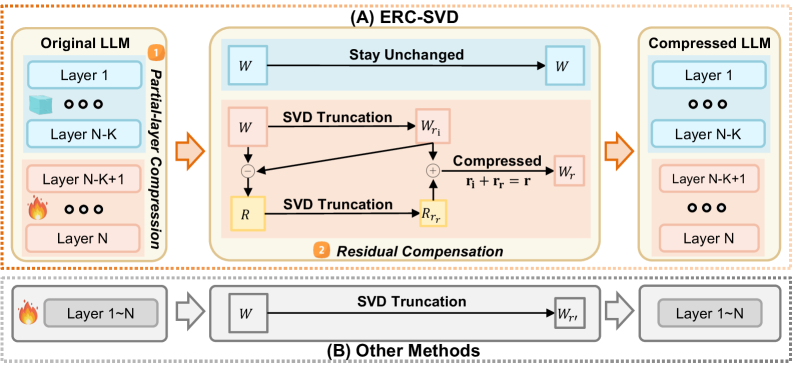
问题定义:现有基于SVD的大语言模型压缩方法在进行低秩近似时,会截断奇异值分解后的矩阵,产生残差矩阵。传统方法直接丢弃残差矩阵,导致信息损失,降低模型性能。此外,对模型所有层进行压缩会累积误差,进一步恶化性能。因此,如何在保证压缩率的同时,减少截断损失和误差传播是需要解决的关键问题。
核心思路:ResSVD的核心思路是通过利用截断过程中产生的残差矩阵来补偿截断损失,从而保留更多原始信息。同时,为了减少误差传播,ResSVD采用选择性压缩策略,只压缩模型的最后几层。这种策略旨在平衡压缩率和模型性能,在保证压缩效率的同时,尽可能减少性能损失。
技术框架:ResSVD的整体框架包括以下几个主要步骤:1) 对大语言模型进行奇异值分解(SVD),得到奇异值、左奇异向量和右奇异向量;2) 对奇异值进行截断,保留最重要的奇异值,并生成残差矩阵;3) 利用残差矩阵对截断后的矩阵进行补偿,减少截断损失;4) 选择性地压缩模型的最后几层,避免对所有层进行压缩;5) 对压缩后的模型进行微调,以恢复性能。
关键创新:ResSVD的关键创新在于两个方面:一是残差补偿机制,通过利用残差矩阵来减少截断损失,从而保留更多原始信息;二是选择性压缩策略,只压缩模型的最后几层,从而减少误差传播。这两个创新点共同作用,使得ResSVD能够在保证压缩率的同时,尽可能减少模型性能损失。与现有方法相比,ResSVD更加注重信息的保留和误差的控制。
关键设计:ResSVD的关键设计包括:1) 残差补偿的计算方式,如何有效地利用残差矩阵来补偿截断后的矩阵;2) 选择性压缩的层数选择,如何确定需要压缩的层数,以达到最佳的压缩效果;3) 微调策略,如何对压缩后的模型进行微调,以恢复性能。这些设计都需要根据具体的模型和数据集进行调整和优化。
🖼️ 关键图片


📊 实验亮点
ResSVD在多个LLM家族和基准数据集上进行了全面评估,结果表明ResSVD始终优于现有的同类方法。具体来说,ResSVD在保持相同压缩率的情况下,能够显著提高模型的性能,例如在某些数据集上,ResSVD的性能提升超过了5%。这些实验结果充分证明了ResSVD的有效性和实用性。
🎯 应用场景
ResSVD具有广泛的应用前景,尤其是在资源受限的环境中部署大型语言模型。例如,在移动设备、嵌入式系统或边缘计算设备上,可以使用ResSVD来压缩模型,从而降低内存占用和计算复杂度,使其能够在这些设备上运行。此外,ResSVD还可以用于加速模型的推理速度,提高用户体验。该研究的未来影响在于推动大语言模型在更多场景下的应用,并促进人工智能技术的普及。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive capabilities in a wide range of downstream natural language processing tasks. Nevertheless, their considerable sizes and memory demands hinder practical deployment, underscoring the importance of developing efficient compression strategies. Singular value decomposition (SVD) decomposes a matrix into orthogonal components, enabling efficient low-rank approximation. This is particularly suitable for LLM compression, where weight matrices often exhibit significant redundancy. However, current SVD-based methods neglect the residual matrix from truncation, resulting in significant truncation loss. Additionally, compressing all layers of the model results in severe performance degradation. To overcome these limitations, we propose ResSVD, a new post-training SVD-based LLM compression method. Specifically, we leverage the residual matrix generated during the truncation process to reduce truncation loss. Moreover, under a fixed overall compression ratio, we selectively compress the last few layers of the model, which mitigates error propagation and significantly improves the performance of compressed models. Comprehensive evaluations of ResSVD on diverse LLM families and multiple benchmark datasets indicate that ResSVD consistently achieves superior performance over existing counterpart methods, demonstrating its practical effectiveness.