Large Language Models Meet Knowledge Graphs for Question Answering: Synthesis and Opportunities
作者: Chuangtao Ma, Yongrui Chen, Tianxing Wu, Arijit Khan, Haofen Wang
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-05-26 (更新: 2025-09-22)
备注: Accepted at EMNLP 2025 Main
💡 一句话要点
综述性研究:探讨大型语言模型与知识图谱融合在问答任务中的方法与机遇
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 问答系统 自然语言处理 信息检索 知识推理 综述研究
📋 核心要点
- 现有基于大型语言模型的问答系统在复杂推理、知识更新和避免幻觉方面存在不足,限制了其应用。
- 该研究提出了一种新的结构化分类法,根据问答类型和知识图谱的角色对现有融合方法进行分类。
- 通过对比分析现有方法的优缺点和知识图谱需求,为未来研究方向提供了指导和潜在机遇。
📝 摘要(中文)
大型语言模型(LLM)凭借其在自然语言理解和生成方面的卓越能力,在问答(QA)任务中表现出显著的性能。然而,基于LLM的QA在复杂的QA任务中面临挑战,原因在于其推理能力不足、知识过时以及存在幻觉。最近的一些工作将LLM和知识图谱(KG)结合起来用于QA,以应对上述挑战。在本综述中,我们提出了一个新的结构化分类法,根据QA的类别以及KG在与LLM集成时的作用,对LLM和KG结合用于QA的方法进行分类。我们系统地调研了LLM和KG结合用于QA的最新方法,并从优势、局限性和KG需求等方面对这些方法进行了比较和分析。然后,我们将这些方法与QA对齐,并讨论这些方法如何应对不同复杂QA的主要挑战。最后,我们总结了进展、评估指标和基准数据集,并强调了开放的挑战和机遇。
🔬 方法详解
问题定义:现有基于大型语言模型的问答系统在处理复杂问题时,面临推理能力不足、知识更新滞后以及容易产生幻觉等问题。这些问题严重影响了问答系统的准确性和可靠性,限制了其在实际场景中的应用。因此,如何有效地将大型语言模型与知识图谱相结合,以提升问答系统的性能,是一个重要的研究问题。
核心思路:该综述的核心思路是对现有的大型语言模型与知识图谱融合的问答方法进行系统性的梳理和分类,并分析其优缺点。通过对不同方法的比较,找出其在不同类型问答任务中的适用性,并探讨如何更好地利用知识图谱来增强大型语言模型的推理能力和知识储备,从而提高问答系统的整体性能。
技术框架:该综述的技术框架主要包括以下几个步骤:首先,提出一种新的结构化分类法,用于对现有方法进行分类。该分类法基于问答的类型以及知识图谱在与大型语言模型集成时的作用。其次,系统地调研现有方法,并从优势、局限性和知识图谱需求等方面进行比较和分析。然后,将这些方法与不同的问答类型对齐,并讨论它们如何应对不同复杂问答的主要挑战。最后,总结现有进展、评估指标和基准数据集,并强调开放的挑战和机遇。
关键创新:该综述的关键创新在于提出了一个新的结构化分类法,该分类法能够更清晰地对现有的大型语言模型与知识图谱融合的问答方法进行分类。此外,该综述还对现有方法的优缺点进行了深入的分析,并指出了未来研究的潜在方向。
关键设计:该综述的关键设计在于其结构化的分类方法和系统性的分析框架。具体的参数设置、损失函数、网络结构等技术细节取决于被调研的各个方法,该综述主要关注的是这些方法的整体框架和设计思想。
🖼️ 关键图片
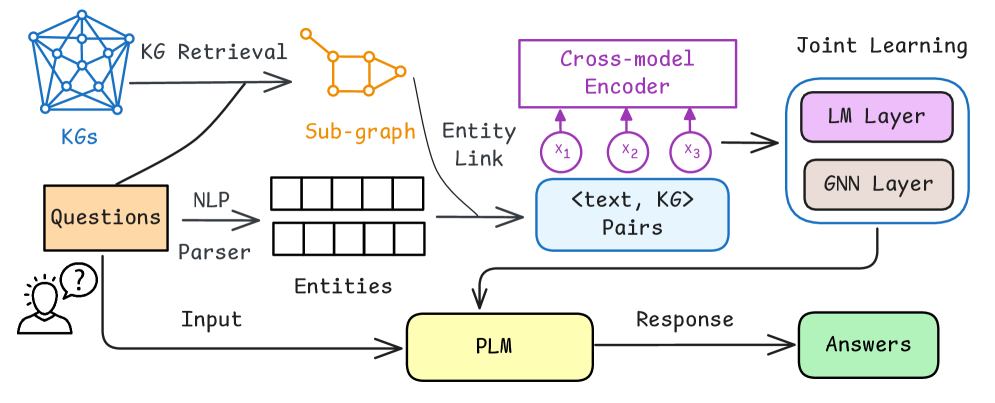
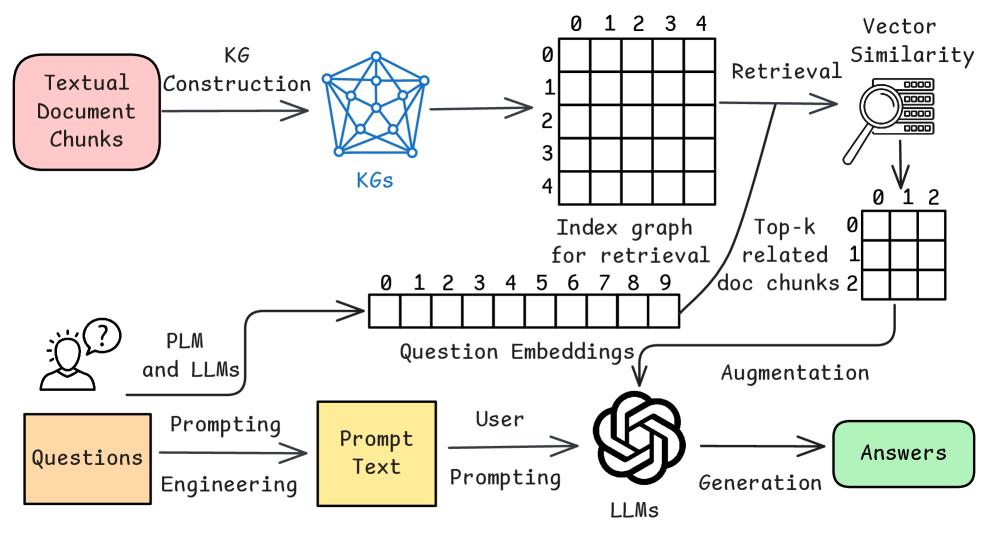
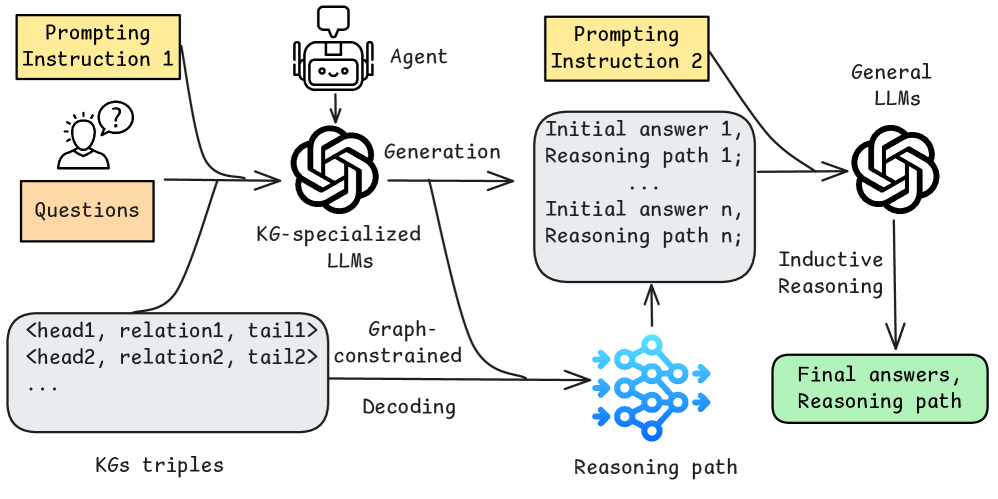
📊 实验亮点
该综述系统地调研了现有的大型语言模型与知识图谱融合的问答方法,并提出了一个新的结构化分类法。通过对现有方法的比较和分析,指出了不同方法在不同类型问答任务中的适用性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于智能客服、知识库问答、医疗诊断辅助等领域。通过融合大型语言模型和知识图谱,可以构建更准确、更可靠的问答系统,提升用户体验,并为决策提供更有效的支持。未来的研究可以进一步探索如何自动构建和更新知识图谱,以及如何更有效地将知识图谱与大型语言模型进行融合。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance on question-answering (QA) tasks because of their superior capabilities in natural language understanding and generation. However, LLM-based QA struggles with complex QA tasks due to poor reasoning capacity, outdated knowledge, and hallucinations. Several recent works synthesize LLMs and knowledge graphs (KGs) for QA to address the above challenges. In this survey, we propose a new structured taxonomy that categorizes the methodology of synthesizing LLMs and KGs for QA according to the categories of QA and the KG's role when integrating with LLMs. We systematically survey state-of-the-art methods in synthesizing LLMs and KGs for QA and compare and analyze these approaches in terms of strength, limitations, and KG requirements. We then align the approaches with QA and discuss how these approaches address the main challenges of different complex QA. Finally, we summarize the advancements, evaluation metrics, and benchmark datasets and highlight open challenges and opportunities.