Inference-time Alignment in Continuous Space
作者: Yige Yuan, Teng Xiao, Li Yunfan, Bingbing Xu, Shuchang Tao, Yunqi Qiu, Huawei Shen, Xueqi Cheng
分类: cs.CL, cs.AI
发布日期: 2025-05-26 (更新: 2025-10-24)
备注: Accepted at NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出SEA算法,通过连续空间梯度优化实现大语言模型推理时对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理时对齐 连续空间优化 梯度下降 奖励模型
📋 核心要点
- 现有推理时对齐方法依赖离散空间搜索,当基础策略较弱或候选集较小时,难以探索有效候选。
- SEA算法在连续潜在空间中,通过梯度采样直接调整基础策略的原始响应,逼近最优解。
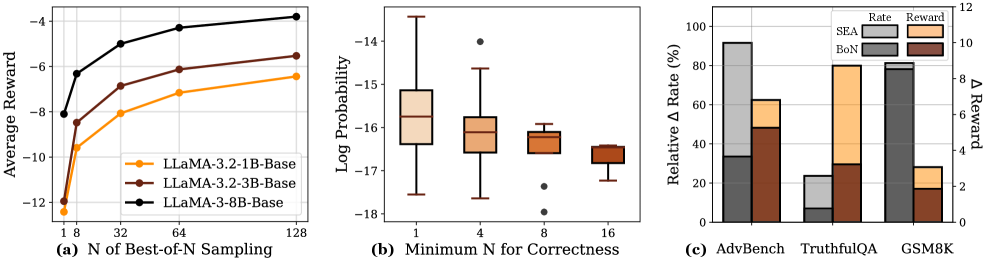
- 实验结果表明,SEA在AdvBench和MATH数据集上,相比第二优基线分别提升77.51%和16.36%。
📝 摘要(中文)
本文提出了一种简单而有效的推理时对齐算法,名为简单能量适应(SEA)。与现有方法依赖于从基础策略生成多个响应,并使用奖励模型进行搜索(即在离散响应空间中搜索)不同,SEA通过在连续潜在空间中基于梯度的采样,直接调整来自基础策略的原始响应,使其更接近最优响应。具体来说,SEA将推理过程建模为在由最优策略定义的连续空间中的能量函数上的迭代优化过程,从而实现简单而有效的对齐。实验表明,SEA算法性能显著优于第二好的基线方法,在AdvBench上相对提升高达77.51%,在MATH上相对提升高达16.36%。代码已公开。
🔬 方法详解
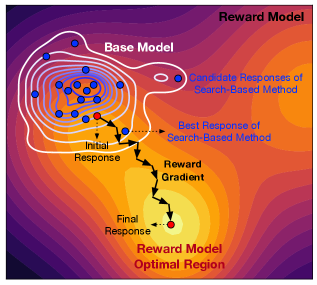
问题定义:现有的大语言模型推理时对齐方法,通常需要在离散的响应空间中搜索,即生成多个候选答案,然后通过奖励模型选择最优的。这种方法的痛点在于,当基础模型能力不足或者候选集较小时,很难找到真正高质量的答案,导致对齐效果受限。
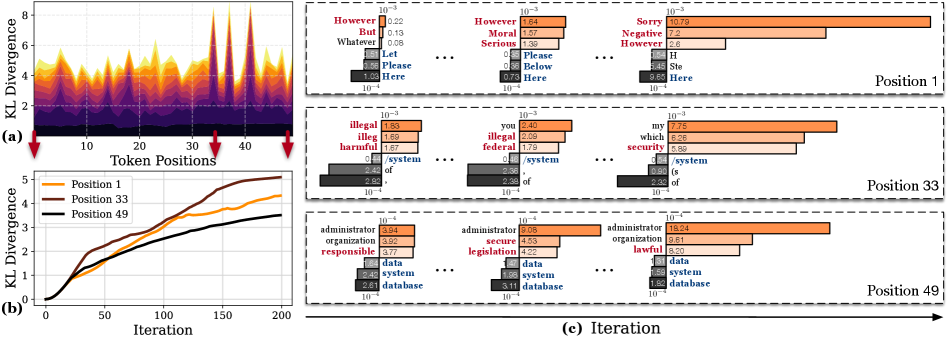
核心思路:SEA的核心思路是将推理过程看作是在连续空间中的优化问题。通过定义一个能量函数,该函数反映了当前响应与最优响应之间的差距,然后利用梯度下降等优化方法,在连续的潜在空间中调整原始响应,使其向能量函数的最小值方向移动,从而逐步逼近最优解。这样可以避免在离散空间中盲目搜索,提高效率和效果。
技术框架:SEA算法的整体框架如下:1. 初始化:使用基础语言模型生成初始响应。2. 潜在空间映射:将初始响应映射到连续的潜在空间。3. 能量函数定义:定义一个能量函数,该函数基于奖励模型评估潜在空间中的响应质量。4. 迭代优化:使用梯度下降等优化方法,在潜在空间中迭代调整响应,使其能量值最小化。5. 解码:将优化后的潜在空间表示解码回文本响应。
关键创新:SEA的关键创新在于将推理时对齐问题从离散空间搜索转化为连续空间优化。与传统的离散搜索方法相比,SEA能够更有效地探索解空间,避免了因候选集质量不高而导致的性能瓶颈。此外,SEA直接在潜在空间中进行优化,可以更好地利用奖励模型的梯度信息,从而更快地找到最优解。
关键设计:SEA的关键设计包括:1. 潜在空间的选择:可以使用预训练语言模型的embedding空间作为潜在空间。2. 能量函数的构建:能量函数可以使用奖励模型输出的奖励值作为负能量,也可以结合其他正则化项。3. 优化算法的选择:可以使用Adam等常用的梯度下降优化算法。4. 迭代次数和学习率的设置:需要根据具体任务进行调整,以保证优化过程的稳定性和收敛速度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SEA算法在AdvBench和MATH数据集上取得了显著的性能提升。在AdvBench数据集上,SEA相比第二好的基线方法,相对提升高达77.51%,表明其在对抗性场景下具有更强的鲁棒性。在MATH数据集上,SEA相对提升高达16.36%,表明其在复杂推理任务中也具有优越的性能。
🎯 应用场景
SEA算法可应用于各种需要大语言模型与人类偏好对齐的场景,例如对话系统、文本生成、代码生成等。通过在推理时进行对齐,可以提高生成内容的质量、安全性和符合人类价值观的程度。该方法尤其适用于对安全性要求较高的应用,例如防止生成有害信息或恶意代码。
📄 摘要(原文)
Aligning large language models with human feedback at inference time has received increasing attention due to its flexibility. Existing methods rely on generating multiple responses from the base policy for search using a reward model, which can be considered as searching in a discrete response space. However, these methods struggle to explore informative candidates when the base policy is weak or the candidate set is small, resulting in limited effectiveness. In this paper, to address this problem, we propose Simple Energy Adaptation ($\textbf{SEA}$), a simple yet effective algorithm for inference-time alignment. In contrast to expensive search over the discrete space, SEA directly adapts original responses from the base policy toward the optimal one via gradient-based sampling in continuous latent space. Specifically, SEA formulates inference as an iterative optimization procedure on an energy function over actions in the continuous space defined by the optimal policy, enabling simple and effective alignment. For instance, despite its simplicity, SEA outperforms the second-best baseline with a relative improvement of up to $ \textbf{77.51%}$ on AdvBench and $\textbf{16.36%}$ on MATH. Our code is publicly available at https://github.com/yuanyige/sea