MiniLongBench: The Low-cost Long Context Understanding Benchmark for Large Language Models
作者: Zhongzhan Huang, Guoming Ling, Shanshan Zhong, Hefeng Wu, Liang Lin
分类: cs.CL
发布日期: 2025-05-26 (更新: 2025-07-30)
备注: Accepted by ACL'25 main track
🔗 代码/项目: GITHUB
💡 一句话要点
提出MiniLongBench,一种低成本的长文本理解大语言模型评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大型语言模型 评测基准 数据压缩 低成本评估
📋 核心要点
- 现有长文本理解基准测试成本高昂,测试时间和推理费用巨大,阻碍了相关研究的快速发展。
- 论文提出一种数据压缩方法,通过剪枝LongBench创建MiniLongBench,显著降低评估成本。
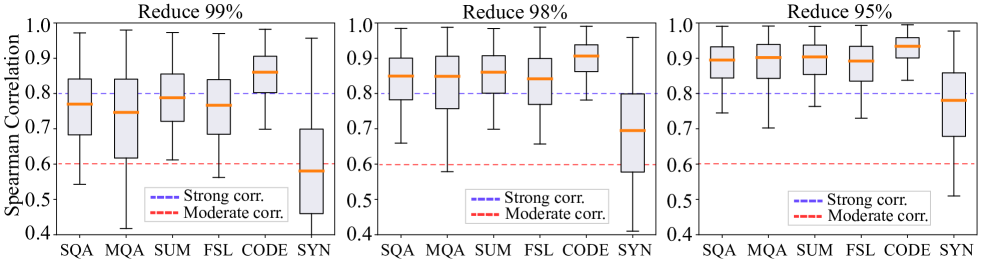
- MiniLongBench在保持与LongBench高度相关性的前提下,将评估成本降低至原来的4.5%。
📝 摘要(中文)
长文本理解(LCU)是当前大型语言模型(LLMs)研究的关键领域。然而,由于长文本数据固有的长度,现有的LLM的LCU基准测试通常导致过高的评估成本,例如测试时间和推理费用。通过广泛的实验,我们发现现有的LCU基准测试存在显著的冗余,这意味着评估效率低下。在本文中,我们提出了一种为具有稀疏信息特征的长文本数据量身定制的简洁数据压缩方法。通过修剪著名的LCU基准LongBench,我们创建了MiniLongBench。该基准包括六个主要任务类别和21个不同任务中的237个测试样本。通过对60多个LLM的实证分析,MiniLongBench实现的平均评估成本仅为原始成本的4.5%,同时与LongBench结果保持0.97的平均等级相关系数。因此,我们的MiniLongBench作为一种低成本的基准,具有极大的潜力来推动未来对LLM的LCU能力的研究。
🔬 方法详解
问题定义:现有长文本理解(LCU)基准,如LongBench,在评估大型语言模型(LLMs)时,由于长文本的特性,导致评估成本过高,包括测试时间和推理费用。这使得研究人员难以快速迭代和探索新的模型和方法。现有基准存在冗余,效率低下。
核心思路:论文的核心思路是通过数据压缩,减少评估所需的样本数量,从而降低评估成本。关键在于找到一种方法,在减少样本数量的同时,保持评估结果与原始基准的相关性。通过分析现有基准的特性,发现长文本数据具有稀疏信息特征,即并非所有文本片段都包含关键信息。
技术框架:整体流程包括:1) 分析现有长文本理解基准LongBench的数据特性;2) 设计一种数据压缩方法,用于剪枝LongBench数据集;3) 使用压缩后的数据集MiniLongBench评估多个LLM;4) 将MiniLongBench的评估结果与LongBench的评估结果进行比较,验证MiniLongBench的有效性。
关键创新:关键创新在于提出了一种针对长文本数据稀疏信息特征的数据压缩方法。该方法能够有效地减少数据集的规模,同时保持评估结果与原始数据集的相关性。这使得研究人员可以使用更小的计算资源和更短的时间来评估LLM的长文本理解能力。
关键设计:论文中没有详细描述数据压缩方法的具体技术细节,例如剪枝策略、信息重要性评估方法等。但是,实验部分提到,MiniLongBench包含237个测试样本,覆盖6个主要任务类别和21个不同任务。与LongBench相比,样本数量大幅减少,但仍能保持较高的评估结果相关性。
🖼️ 关键图片


📊 实验亮点
MiniLongBench在包含237个测试样本的情况下,实现了平均评估成本仅为原始LongBench的4.5%。同时,MiniLongBench与LongBench的评估结果保持了0.97的平均等级相关系数。该结果表明,MiniLongBench能够在显著降低评估成本的同时,保持评估结果的可靠性。
🎯 应用场景
MiniLongBench可用于快速评估和比较不同大型语言模型在长文本理解方面的能力。研究人员和开发者可以使用该基准来优化模型结构、训练方法和推理策略,从而提高LLM在处理长文本任务时的性能。该基准还可用于开发新的长文本理解任务和数据集。
📄 摘要(原文)
Long Context Understanding (LCU) is a critical area for exploration in current large language models (LLMs). However, due to the inherently lengthy nature of long-text data, existing LCU benchmarks for LLMs often result in prohibitively high evaluation costs, like testing time and inference expenses. Through extensive experimentation, we discover that existing LCU benchmarks exhibit significant redundancy, which means the inefficiency in evaluation. In this paper, we propose a concise data compression method tailored for long-text data with sparse information characteristics. By pruning the well-known LCU benchmark LongBench, we create MiniLongBench. This benchmark includes only 237 test samples across six major task categories and 21 distinct tasks. Through empirical analysis of over 60 LLMs, MiniLongBench achieves an average evaluation cost reduced to only 4.5% of the original while maintaining an average rank correlation coefficient of 0.97 with LongBench results. Therefore, our MiniLongBench, as a low-cost benchmark, holds great potential to substantially drive future research into the LCU capabilities of LLMs. See https://github.com/MilkThink-Lab/MiniLongBench for our code, data and tutorial.