Deciphering Trajectory-Aided LLM Reasoning: An Optimization Perspective
作者: Junnan Liu, Hongwei Liu, Linchen Xiao, Shudong Liu, Taolin Zhang, Zihan Ma, Songyang Zhang, Kai Chen
分类: cs.CL, cs.AI
发布日期: 2025-05-26
💡 一句话要点
从元学习视角解读:将LLM推理轨迹视为参数优化的伪梯度下降
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM推理 元学习 梯度下降 模型优化
📋 核心要点
- 现有方法难以解释LLM推理能力,缺乏对其内在机制的深入理解。
- 将LLM推理轨迹视为参数的伪梯度下降,类比元学习中的模型参数更新过程。
- 实验验证了LLM推理与元学习的关联性,并探索了元学习视角下的关键问题。
📝 摘要(中文)
本文提出了一种新颖的框架,通过元学习的视角来理解大型语言模型(LLM)的推理能力。该框架将推理轨迹概念化为LLM参数的伪梯度下降更新,从而识别出LLM推理与各种元学习范式之间的相似之处。我们将推理任务的训练过程形式化为一个元学习设置,其中每个问题都被视为一个单独的任务,而推理轨迹则作为内部循环优化,用于调整模型参数。一旦在各种问题上进行训练,LLM就会发展出可以推广到以前未见过的问题的基本推理能力。广泛的实证评估证实了LLM推理与元学习之间的紧密联系,并从元学习的角度探讨了几个重要的兴趣问题。我们的工作不仅增强了对LLM推理的理解,还为通过已建立的元学习技术改进这些模型提供了实用的见解。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)的推理能力。现有方法缺乏对LLM推理过程的深入理解,难以解释其内在机制,并且缺乏有效的改进策略。论文将LLM的推理过程视为一个黑盒,希望通过元学习的视角来揭示其内部运作机制。
核心思路:论文的核心思路是将LLM的推理轨迹视为模型参数的伪梯度下降更新。具体来说,每个推理步骤都被看作是对LLM参数的一次微调,类似于元学习中的内部循环优化。通过这种类比,可以将LLM的推理过程与元学习中的模型适应过程联系起来,从而利用元学习的理论和方法来分析和改进LLM的推理能力。
技术框架:论文将推理任务的训练过程形式化为一个元学习设置。整体框架包含以下几个主要步骤:1) 将每个问题视为一个独立的任务;2) 将推理轨迹作为内部循环优化,用于调整模型参数;3) 在大量不同的问题上训练LLM,使其学习到通用的推理能力;4) 使用元学习的评估方法来评估LLM的推理能力。
关键创新:论文最重要的技术创新点在于将LLM的推理轨迹与元学习中的伪梯度下降更新联系起来。这种联系为理解LLM的推理能力提供了一个新的视角,并为利用元学习的理论和方法来改进LLM的推理能力提供了可能性。与现有方法相比,该方法更加注重对LLM内部机制的理解,而不是仅仅关注其外部表现。
关键设计:论文的关键设计包括:1) 如何将推理轨迹映射到伪梯度下降更新;2) 如何选择合适的元学习算法来训练LLM;3) 如何设计有效的评估指标来衡量LLM的推理能力。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

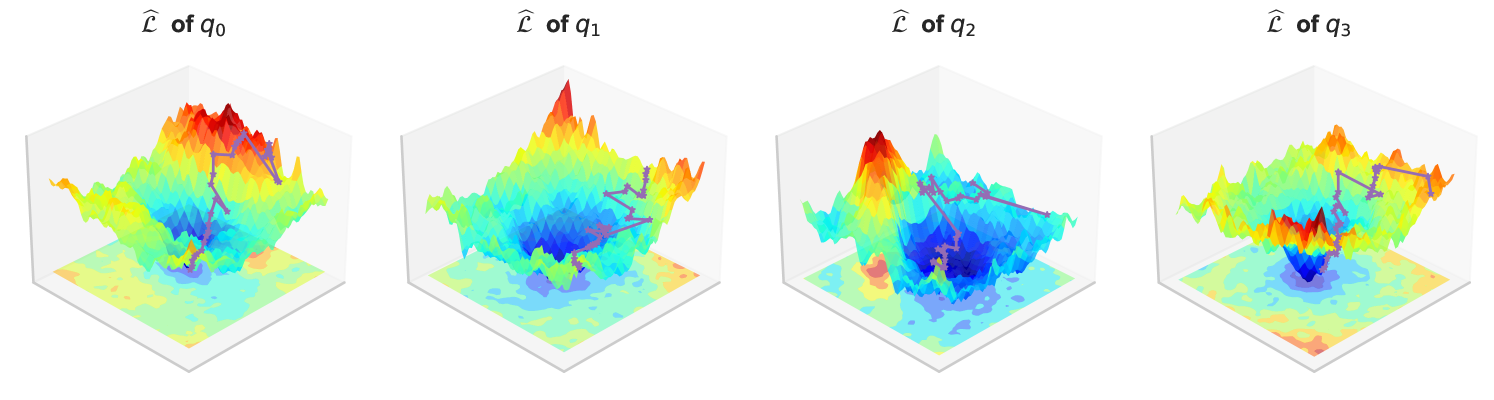
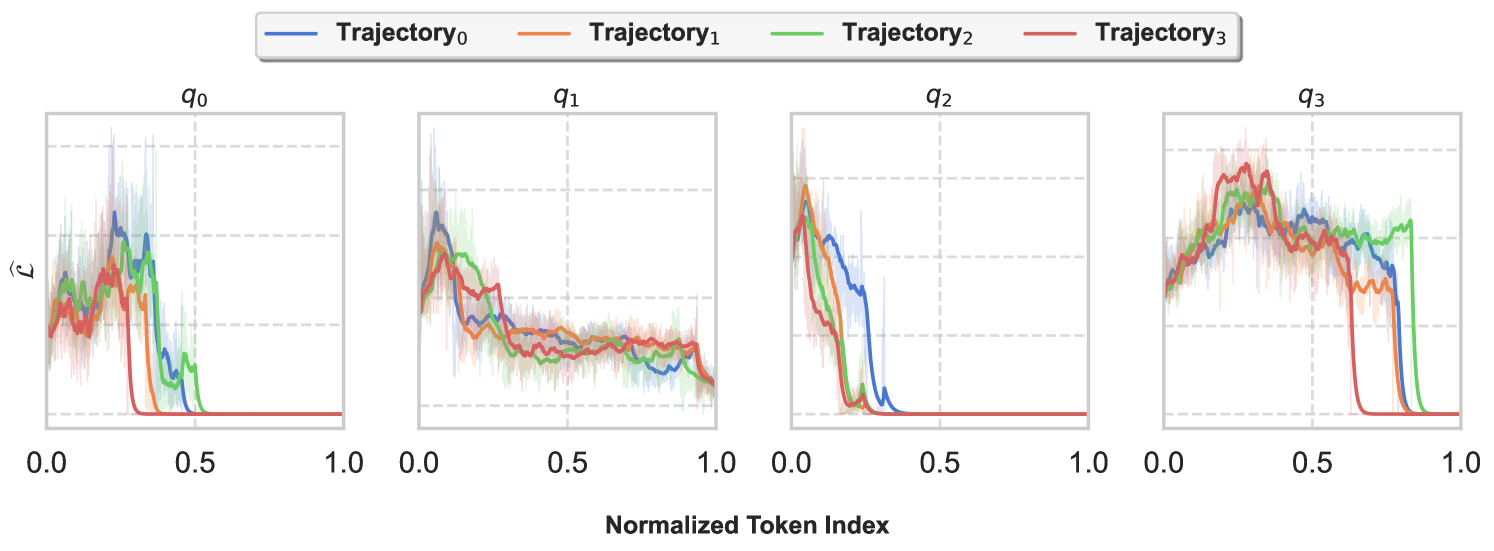
📊 实验亮点
论文通过实验验证了LLM推理与元学习之间的紧密联系。具体的性能数据、对比基线和提升幅度等信息在摘要中未提及,属于未知信息。但论文强调,实验结果证实了该框架的有效性,并为理解和改进LLM的推理能力提供了有价值的见解。
🎯 应用场景
该研究成果可应用于提升LLM的推理能力,例如改进问答系统、对话系统和知识图谱推理等应用。通过利用元学习的理论和方法,可以训练出更具泛化能力和鲁棒性的LLM,从而在各种实际应用中取得更好的效果。此外,该研究还可以为LLM的架构设计和训练策略提供新的思路。
📄 摘要(原文)
We propose a novel framework for comprehending the reasoning capabilities of large language models (LLMs) through the perspective of meta-learning. By conceptualizing reasoning trajectories as pseudo-gradient descent updates to the LLM's parameters, we identify parallels between LLM reasoning and various meta-learning paradigms. We formalize the training process for reasoning tasks as a meta-learning setup, with each question treated as an individual task, and reasoning trajectories serving as the inner loop optimization for adapting model parameters. Once trained on a diverse set of questions, the LLM develops fundamental reasoning capabilities that can generalize to previously unseen questions. Extensive empirical evaluations substantiate the strong connection between LLM reasoning and meta-learning, exploring several issues of significant interest from a meta-learning standpoint. Our work not only enhances the understanding of LLM reasoning but also provides practical insights for improving these models through established meta-learning techniques.