From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
作者: Chen Shani, Liron Soffer, Dan Jurafsky, Yann LeCun, Ravid Shwartz-Ziv
分类: cs.CL, cs.AI, cs.IT
发布日期: 2025-05-21 (更新: 2025-12-01)
💡 一句话要点
对比人类与LLM概念结构,揭示LLM压缩语义的特性及局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 概念表示 信息瓶颈 语义理解 认知建模
📋 核心要点
- 大型语言模型在语言能力上表现出色,但其概念表示与人类的差异尚不明确,尤其是在压缩与语义丰富性之间的权衡上。
- 论文采用信息瓶颈框架,对比人类和LLM的概念结构,分析LLM在压缩信息和保留语义细微差别方面的表现。
- 研究发现LLM倾向于过度压缩,牺牲语义丰富性以实现更高的信息效率,与人类的“低效”但更具适应性的表示形成对比。
📝 摘要(中文)
人类将知识组织成紧凑的概念类别,以平衡压缩和语义丰富性。大型语言模型(LLM)表现出令人印象深刻的语言能力,但它们是否也遵循这种压缩与意义之间的权衡尚不清楚。我们应用信息瓶颈框架,使用经典分类基准,将人类概念结构与40多个LLM的嵌入进行比较。我们发现,LLM在很大程度上与人类的类别边界对齐,但在细粒度的语义区分方面有所欠缺。与人类保持“低效”的表示以保留上下文细微差别不同,LLM会积极压缩,以牺牲语义丰富性为代价来实现更优的信息论压缩。令人惊讶的是,编码器模型在人类对齐方面优于更大的解码器模型,这表明理解和生成依赖于不同的表示机制。训练动态分析揭示了一个两阶段的轨迹:快速的初始概念形成,然后是架构重组,在此期间,随着模型发现越来越高效、稀疏的编码,语义处理从深层网络层迁移到中间层。这些不同的策略,即LLM优化压缩,而人类优化自适应效用,揭示了人工智能和自然智能之间的根本差异。这突出了对能够保留人类理解必不可少的概念“低效”的模型的需求。
🔬 方法详解
问题定义:现有大型语言模型(LLM)虽然在语言任务上表现出色,但其内部的概念表示机制与人类存在差异。一个关键问题是,LLM是否像人类一样,在压缩信息和保留语义丰富性之间进行权衡?现有方法缺乏对LLM概念表示的深入分析,以及与人类概念结构的直接比较。
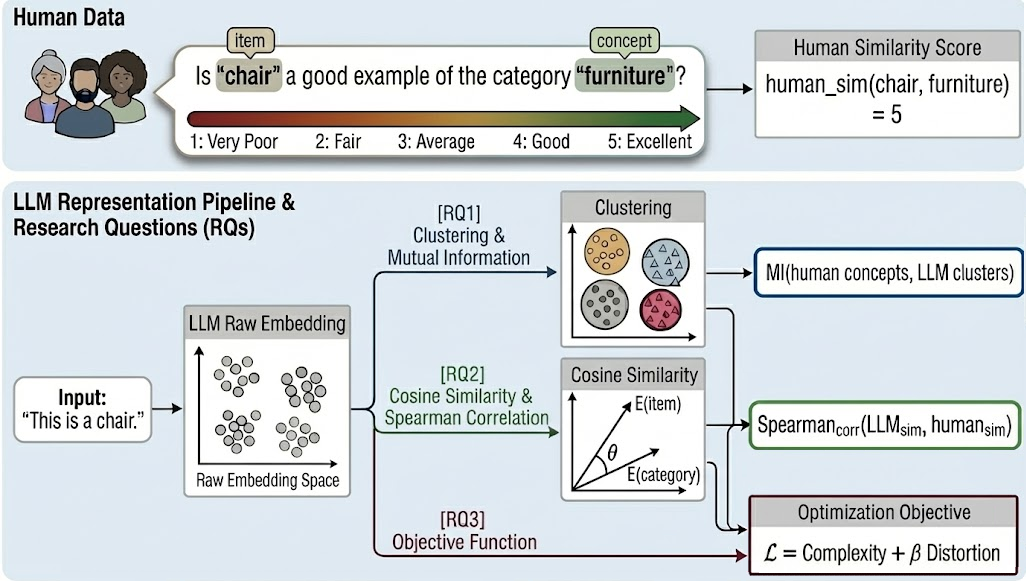
核心思路:论文的核心思路是利用信息瓶颈(Information Bottleneck)框架,量化LLM在学习概念表示时的信息压缩程度和语义保留能力。通过将LLM的嵌入与人类的分类数据进行比较,可以揭示LLM在概念表示上的特点和局限性。这种方法能够帮助我们理解LLM如何处理语义信息,以及其与人类认知的差异。
技术框架:整体框架包括以下几个主要步骤:1) 选择多个预训练的LLM(包括编码器和解码器模型);2) 使用经典的概念分类基准数据集(例如动物分类);3) 提取LLM在处理这些数据时的嵌入表示;4) 使用信息瓶颈框架,计算LLM嵌入的信息压缩程度和语义保留能力;5) 将LLM的结果与人类的分类数据进行比较,分析差异。
关键创新:该研究的关键创新在于:1) 将信息瓶颈框架应用于分析LLM的概念表示,提供了一种量化压缩和语义保留的手段;2) 首次系统性地比较了多种LLM(包括不同架构和规模)与人类的概念结构,揭示了LLM在概念表示上的普遍趋势;3) 发现编码器模型在人类对齐方面优于解码器模型,暗示了理解和生成可能依赖于不同的表示机制。
关键设计:论文的关键设计包括:1) 使用了多个经典的概念分类数据集,保证了实验的可靠性和可重复性;2) 选择了40多个不同架构和规模的LLM,覆盖了广泛的模型类型;3) 使用信息瓶颈框架中的互信息(Mutual Information)来量化信息压缩和语义保留;4) 分析了LLM训练过程中的动态变化,揭示了语义处理从深层到中间层的迁移现象。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在概念分类上与人类具有一定程度的对齐,但在细粒度语义区分上不如人类。LLM倾向于过度压缩信息,以牺牲语义丰富性为代价。令人惊讶的是,编码器模型在人类对齐方面优于解码器模型。训练动态分析显示,语义处理会从深层网络层迁移到中间层,表明模型在学习过程中不断优化信息表示。
🎯 应用场景
该研究成果可应用于改进LLM的语义理解能力,使其更接近人类的认知方式。通过理解LLM在概念表示上的局限性,可以设计更有效的训练方法和模型架构,提升LLM在需要细粒度语义理解的任务中的表现,例如对话系统、信息检索和知识推理。此外,该研究也为人工智能的认知建模提供了新的视角。
📄 摘要(原文)
Humans organize knowledge into compact conceptual categories that balance compression with semantic richness. Large Language Models (LLMs) exhibit impressive linguistic abilities, but whether they navigate this same compression-meaning trade-off remains unclear. We apply an Information Bottleneck framework to compare human conceptual structure with embeddings from 40+ LLMs using classic categorization benchmarks. We find that LLMs broadly align with human category boundaries, yet fall short on fine-grained semantic distinctions. Unlike humans, who maintain
inefficient'' representations that preserve contextual nuance, LLMs aggressively compress, achieving more optimal information-theoretic compression at the cost of semantic richness. Surprisingly, encoder models outperform much larger decoder models in human alignment, suggesting that understanding and generation rely on distinct representational mechanisms. Training-dynamics analysis reveals a two-phase trajectory: rapid initial concept formation followed by architectural reorganization, during which semantic processing migrates from deep to mid-network layers as the model discovers increasingly efficient, sparser encodings. These divergent strategies, where LLMs optimize for compression and humans for adaptive utility, reveal fundamental differences between artificial and natural intelligence. This highlights the need for models that preserve the conceptualinefficiencies'' essential for human-like understanding.