A quantitative analysis of semantic information in deep representations of text and images
作者: Santiago Acevedo, Andrea Mascaretti, Riccardo Rende, Matéo Mahaut, Marco Baroni, Alessandro Laio
分类: cs.CL, cs.LG, physics.comp-ph
发布日期: 2025-05-21 (更新: 2025-12-05)
💡 一句话要点
提出一种量化方法,分析文本和图像深度表征中的语义信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义信息 深度表征 大型语言模型 视觉Transformer 互信息 跨模态学习 信息论 量化分析
📋 核心要点
- 现有方法缺乏对跨模态和跨语言语义信息在深度表征中量化分析的能力。
- 通过测量语义相关数据的表征的相对信息含量,探究语义信息在模型中的编码方式。
- 实验表明,大型LLM能提取更多通用信息,且图像和文本表征间存在信息不对称性。
📝 摘要(中文)
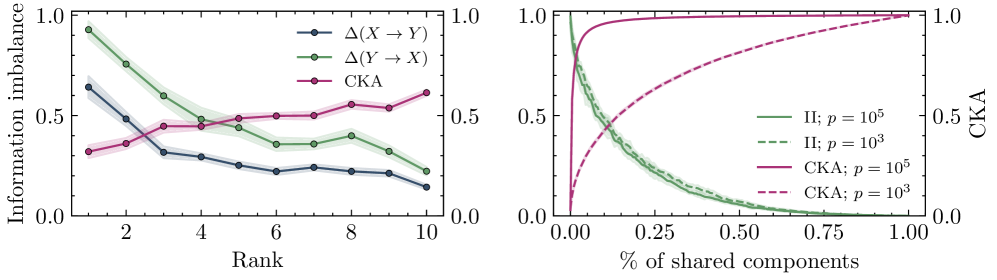
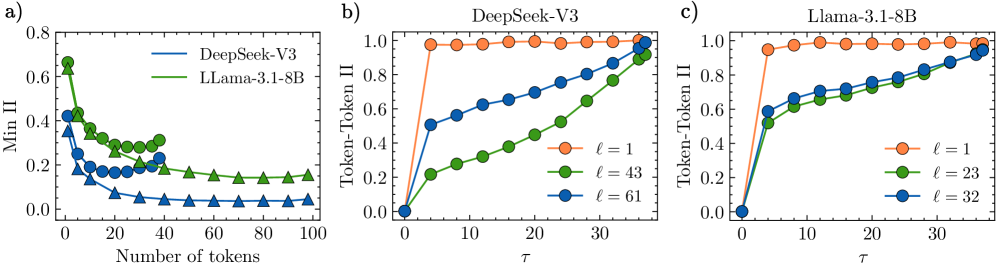
本文提出了一种量化方法,用于研究深度神经网络中语义相关数据的相似表征现象,即使这些数据来自不同领域,例如图像及其描述,或不同语言的相同文本。该方法通过测量语义相关数据的表征的相对信息含量,并探究其如何编码到大型语言模型(LLM)和视觉Transformer的多个token中。首先,研究了LLM如何处理翻译后的句子对,识别出包含最多语言可迁移信息的内部“语义”层。研究发现,在这些层上,较大的LLM(DeepSeek-V3)比小的LLM(Llama3.1-8B)提取的更通用的信息。英语文本的语义信息分布在许多token中,其特征在于token之间的长距离相关性以及因果的从左到右(即过去-未来)不对称性。此外,还识别了视觉Transformer中编码语义信息的层。结果表明,LLM语义层中的标题表征可以预测相应图像的视觉表征。观察到图像和文本表征之间存在显著且模型依赖的信息不对称性。
🔬 方法详解
问题定义:现有方法难以量化分析深度神经网络中,特别是大型语言模型和视觉Transformer中,文本和图像等不同模态数据在语义层面的信息表征和传递。缺乏对跨语言、跨模态语义信息如何编码以及不同模型之间差异的深入理解。
核心思路:核心在于通过信息论的方法,量化不同层级、不同模态的表征所包含的语义信息量。通过测量语义相关数据(如翻译文本、图像及其描述)的表征之间的互信息,来评估语义信息的保留程度和传递效率。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:构建语义相关的文本和图像数据集,例如翻译后的句子对、图像及其对应的文本描述。2) 表征提取:使用预训练的LLM和视觉Transformer提取文本和图像在不同层的表征。3) 信息量化:使用互信息等信息论指标,量化不同层级表征中包含的语义信息量。4) 信息传递分析:分析语义信息在不同层级之间的传递过程,以及不同模态之间的信息交互。
关键创新:该方法的核心创新在于提出了一种量化语义信息的方法,能够对深度神经网络中的语义表征进行细粒度的分析。通过这种方法,可以识别出模型中负责语义信息处理的关键层级,并评估不同模型在语义信息处理方面的能力差异。
关键设计:在量化语义信息时,论文可能采用了互信息(Mutual Information)或者其他相关的信息论指标。对于LLM,关注不同token之间的相关性,以及从左到右的因果关系对语义信息编码的影响。对于视觉Transformer,关注不同视觉token之间的关系,以及图像和文本表征之间的对齐方式。具体的参数设置和损失函数取决于所使用的LLM和视觉Transformer的架构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,较大的LLM(DeepSeek-V3)比小的LLM(Llama3.1-8B)提取的更通用的信息。此外,LLM语义层中的标题表征可以预测相应图像的视觉表征,揭示了跨模态语义信息传递的可能性。观察到图像和文本表征之间存在显著且模型依赖的信息不对称性。
🎯 应用场景
该研究成果可应用于提升跨语言机器翻译的质量,改进图像描述生成模型的语义一致性,以及优化多模态学习模型的性能。通过理解模型如何编码和传递语义信息,可以设计更高效、更鲁棒的AI系统,并促进不同模态信息之间的无缝融合。
📄 摘要(原文)
Deep neural networks are known to develop similar representations for semantically related data, even when they belong to different domains, such as an image and its description, or the same text in different languages. We present a method for quantitatively investigating this phenomenon by measuring the relative information content of the representations of semantically related data and probing how it is encoded into multiple tokens of large language models (LLMs) and vision transformers. Looking first at how LLMs process pairs of translated sentences, we identify inner ``semantic'' layers containing the most language-transferable information. We find moreover that, on these layers, a larger LLM (DeepSeek-V3) extracts significantly more general information than a smaller one (Llama3.1-8B). Semantic information of English text is spread across many tokens and it is characterized by long-distance correlations between tokens and by a causal left-to-right (i.e., past-future) asymmetry. We also identify layers encoding semantic information within visual transformers. We show that caption representations in the semantic layers of LLMs predict visual representations of the corresponding images. We observe significant and model-dependent information asymmetries between image and text representations.