TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
作者: Yanshu Li, Jianjiang Yang, Tian Yun, Pinyuan Feng, Jinfa Huang, Ruixiang Tang
分类: cs.CL, cs.CV
发布日期: 2025-05-21 (更新: 2025-10-20)
备注: EMNLP2025 Main, 28 pages, 11 figures, 19 tables
💡 一句话要点
TACO:通过任务映射引导序列配置,增强多模态上下文学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 上下文学习 任务映射 视觉-语言模型 序列配置
📋 核心要点
- 多模态上下文学习对输入序列质量敏感,尤其在复杂推理任务中,现有方法缺乏对模型如何利用上下文的理解。
- TACO通过任务映射视角,揭示演示序列中的局部和全局关系如何引导模型推理,从而动态配置ICL序列。
- 实验表明,TACO在多个LVLM和数据集上超越基线,证明了任务映射在多模态ICL中的价值。
📝 摘要(中文)
多模态上下文学习(ICL)已成为利用大型视觉-语言模型(LVLMs)能力的关键机制。然而,其有效性仍然对输入ICL序列的质量高度敏感,特别是对于涉及复杂推理或开放式生成的任务。一个主要的限制是我们对LVLMs在推理过程中如何利用这些序列的理解有限。为了弥合这一差距,我们通过任务映射的视角系统地解释多模态ICL,揭示了演示内部和之间的局部和全局关系如何引导模型推理。在此基础上,我们提出了TACO,一个轻量级的基于Transformer的模型,配备了任务感知注意力,可以动态配置ICL序列。通过将任务映射信号注入到自回归解码过程中,TACO在序列构建和任务推理之间创建了双向协同作用。在五个LVLMs和九个数据集上的实验表明,TACO在不同的ICL任务中始终优于基线。这些结果表明,任务映射是解释和改进多模态ICL的一种新颖且有价值的视角。
🔬 方法详解
问题定义:多模态上下文学习(ICL)的性能高度依赖于输入序列的质量,尤其是在需要复杂推理或开放式生成任务中。现有的方法缺乏对大型视觉-语言模型(LVLMs)如何利用上下文序列进行推理的深入理解,导致难以构建有效的ICL序列。这限制了LVLMs在实际应用中的潜力。
核心思路:论文的核心思路是通过任务映射(Task Mapping)来理解和指导ICL序列的构建。任务映射旨在揭示演示序列内部以及序列之间的局部和全局关系,从而理解这些关系如何影响模型的推理过程。基于此理解,设计一种机制来动态地配置ICL序列,以优化模型的推理性能。
技术框架:TACO模型是一个轻量级的基于Transformer的模型,它利用任务感知注意力机制来动态配置ICL序列。整体流程包括:1) 输入包含任务描述和候选演示序列;2) 使用任务感知注意力模块,该模块将任务映射信号注入到自回归解码过程中;3) 模型动态选择和排序演示序列,构建优化的ICL序列;4) LVLM利用构建的ICL序列进行推理。
关键创新:TACO的关键创新在于引入了任务映射的视角来指导ICL序列的构建。与现有方法不同,TACO不是简单地拼接演示序列,而是通过理解任务与演示之间的关系,动态地选择和排序演示,从而构建更有效的ICL序列。这种方法能够更好地利用LVLMs的推理能力。
关键设计:TACO的关键设计包括:1) 任务感知注意力模块,用于将任务映射信号注入到自回归解码过程中;2) 轻量级的Transformer架构,保证了模型的效率;3) 动态序列配置机制,允许模型根据任务需求灵活地选择和排序演示序列。具体的损失函数和网络结构细节在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片

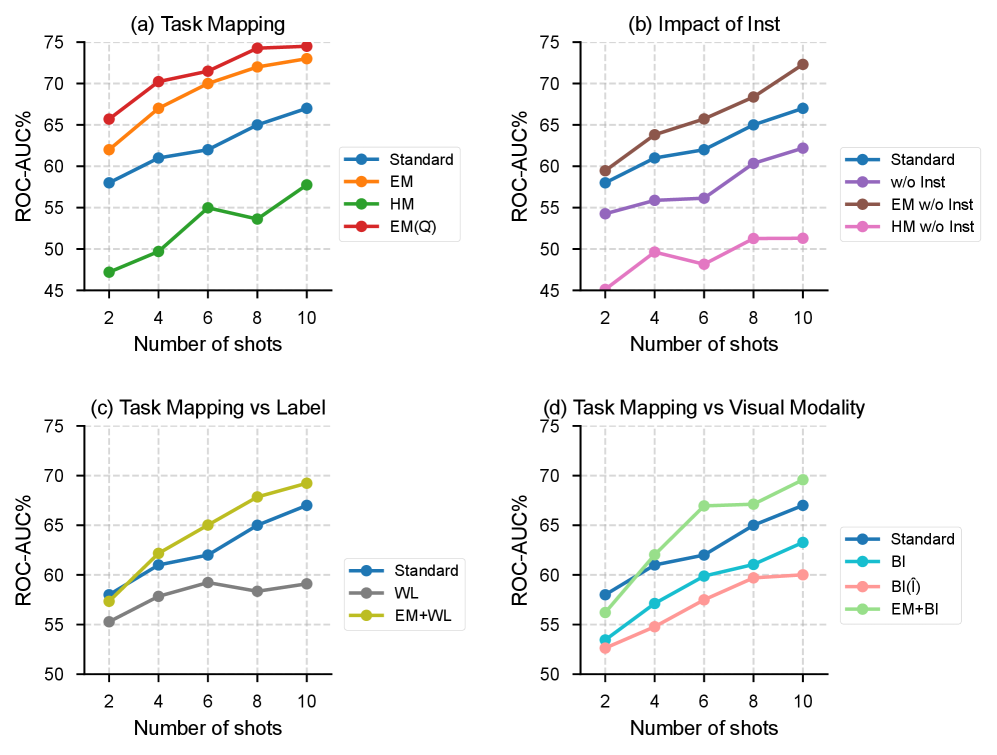
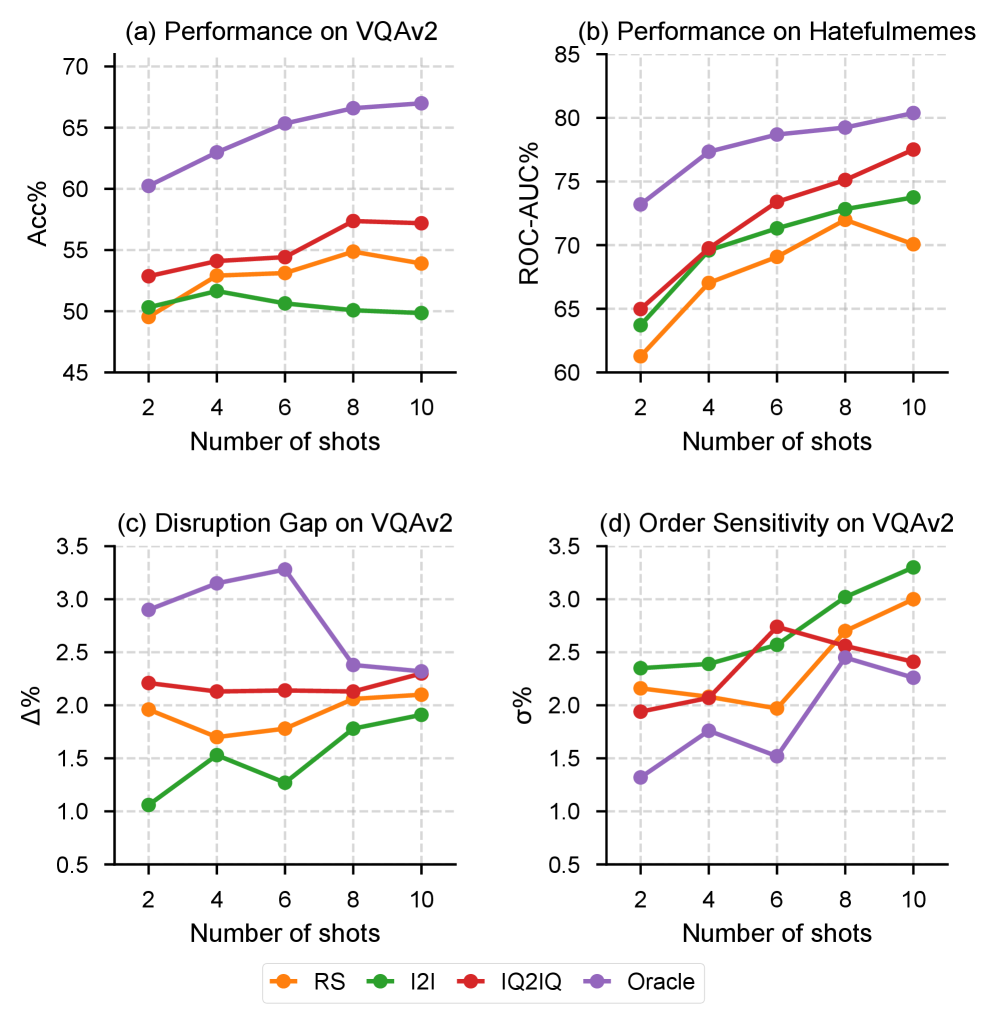
📊 实验亮点
TACO在五个LVLMs和九个数据集上进行了实验,结果表明TACO在不同的ICL任务中始终优于基线方法。具体性能提升幅度在摘要中未给出明确数据,但强调了TACO的一致性和有效性,证明了任务映射在多模态ICL中的价值。
🎯 应用场景
该研究成果可应用于各种需要多模态信息融合和复杂推理的场景,例如视觉问答、图像描述生成、机器人导航等。通过优化上下文学习序列,可以提升LVLMs在这些任务中的性能,从而实现更智能、更可靠的应用。
📄 摘要(原文)
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision-language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input ICL sequences, particularly for tasks involving complex reasoning or open-ended generation. A major limitation is our limited understanding of how LVLMs actually exploit these sequences during inference. To bridge this gap, we systematically interpret multimodal ICL through the lens of task mapping, which reveals how local and global relationships within and among demonstrations guide model reasoning. Building on this insight, we present TACO, a lightweight transformer-based model equipped with task-aware attention that dynamically configures ICL sequences. By injecting task-mapping signals into the autoregressive decoding process, TACO creates a bidirectional synergy between sequence construction and task reasoning. Experiments on five LVLMs and nine datasets demonstrate that TACO consistently surpasses baselines across diverse ICL tasks. These results position task mapping as a novel and valuable perspective for interpreting and improving multimodal ICL.