Are LLMs reliable? An exploration of the reliability of large language models in clinical note generation
作者: Kristine Ann M. Carandang, Jasper Meynard P. Araña, Ethan Robert A. Casin, Christopher P. Monterola, Daniel Stanley Y. Tan, Jesus Felix B. Valenzuela, Christian M. Alis
分类: cs.CL
发布日期: 2025-05-21
DOI: 10.18653/v1/2025.acl-industry.99
💡 一句话要点
评估大型语言模型在临床笔记生成中的可靠性,推荐本地部署小型开源模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 临床笔记生成 可靠性评估 语义一致性 数据隐私 医疗文档 自然语言处理
📋 核心要点
- 临床笔记生成对准确性和隐私性要求高,但大型语言模型响应的可变性带来了挑战。
- 通过评估多个LLM在生成临床笔记时的一致性、语义相似性和正确性来衡量其可靠性。
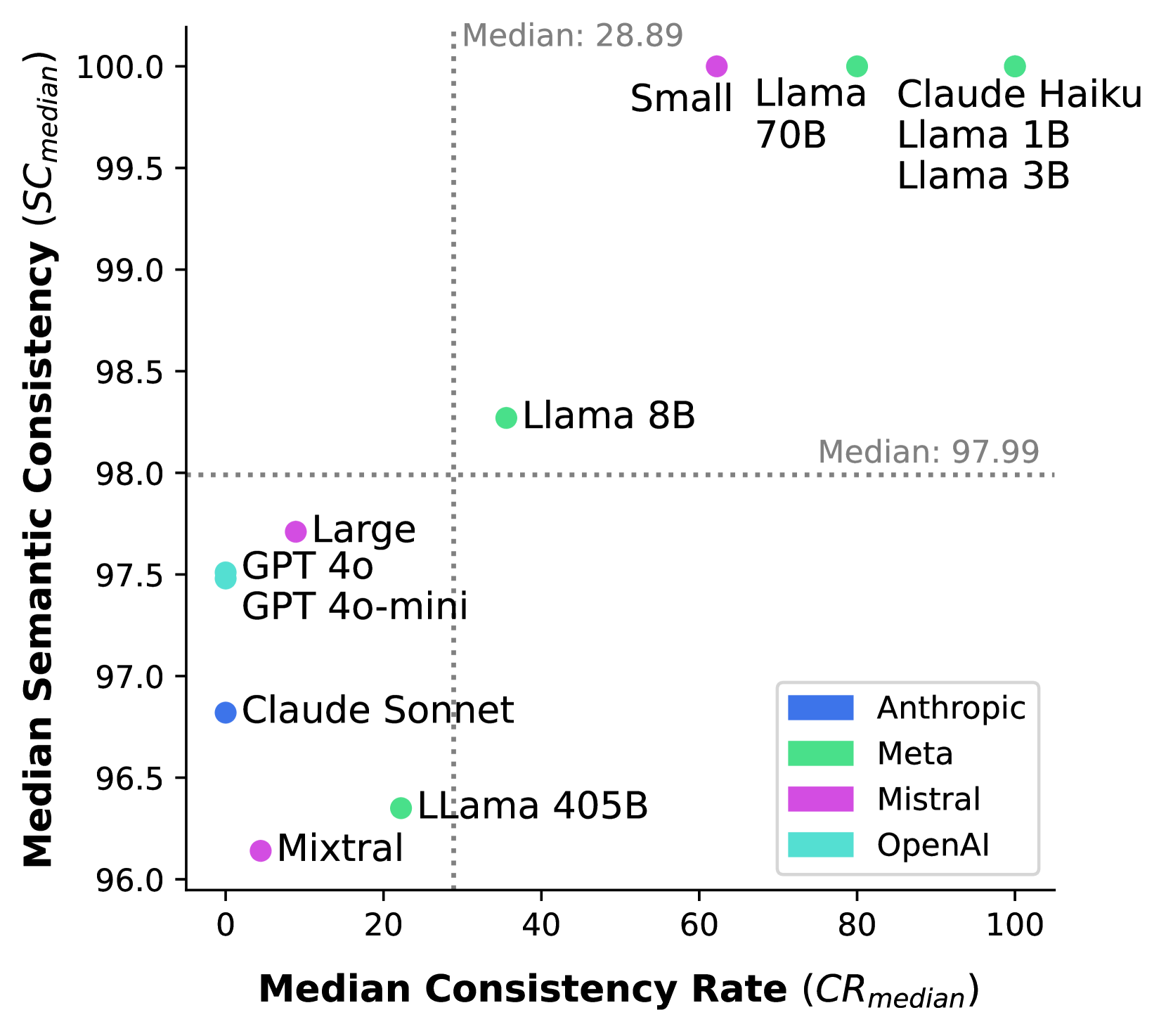
- 实验表明Meta的Llama 70B和Mistral的Small模型表现出色,推荐本地部署以保障数据隐私。
📝 摘要(中文)
由于医疗服务提供者(HCPs)在准确记录和保护患者数据隐私方面负有法律和伦理责任,大型语言模型(LLMs)响应的自然可变性给将LLM驱动的临床笔记生成(CNG)系统整合到实际临床流程中带来了挑战。CNG中文本的详细性质进一步加剧了这种复杂性。为了增强HCPs对LLM驱动工具的信心,本研究评估了来自Anthropic、Meta、Mistral和OpenAI的12个开源和专有LLM在CNG中的可靠性,从它们在多次迭代中使用相同提示时生成字符串等效(一致性率)、具有相同含义(语义一致性)和正确(语义相似性)的笔记的能力方面进行评估。结果表明,(1)来自所有模型系列的LLM都是稳定的,因此它们的响应在语义上是一致的,尽管以各种方式编写,以及(2)大多数LLM生成的笔记接近专家制作的相应笔记。总的来说,Meta的Llama 70B是最可靠的,其次是Mistral的Small模型。根据这些发现,我们建议本地部署这些相对较小的开源模型用于CNG,以确保符合数据隐私法规,并提高HCPs在临床文档中的效率。
🔬 方法详解
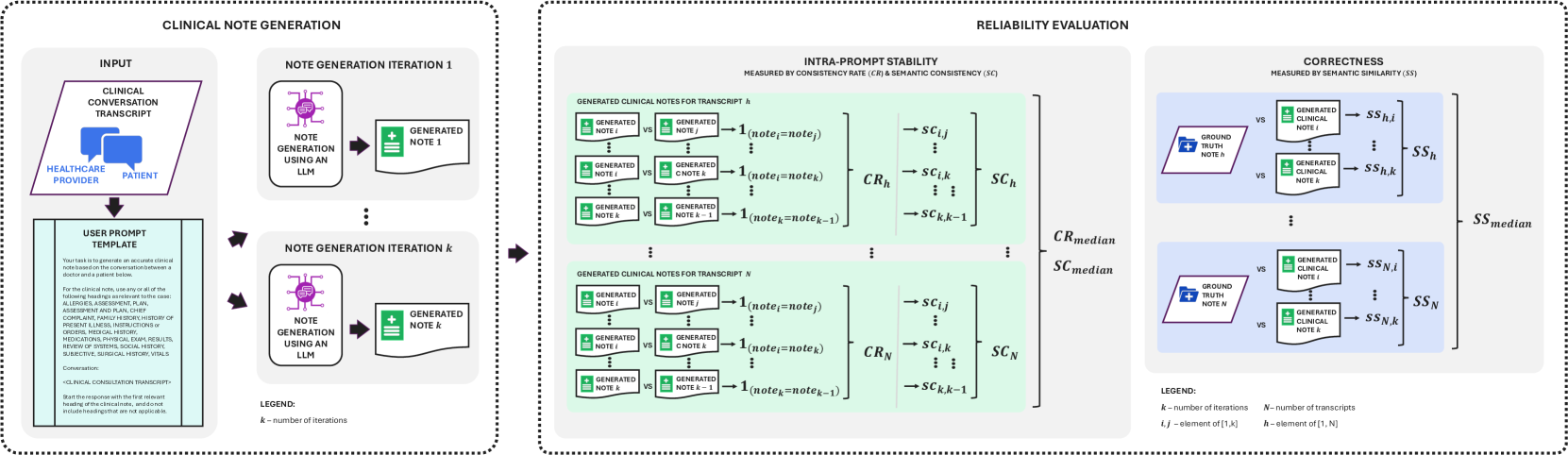
问题定义:论文旨在解决大型语言模型(LLMs)在临床笔记生成(CNG)中应用时,由于其响应的自然可变性而导致的可靠性问题。现有方法难以保证生成笔记的一致性、准确性和语义相似性,从而影响医疗服务提供者(HCPs)对LLM工具的信任,并可能违反数据隐私法规。
核心思路:论文的核心思路是通过定量评估多个LLM在CNG任务中的可靠性,从而为HCPs选择合适的LLM提供依据。具体来说,论文关注LLM在多次迭代中使用相同提示时,生成笔记的字符串等效性(一致性率)、语义一致性和语义相似性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择12个来自不同模型家族(Anthropic, Meta, Mistral, OpenAI)的LLM,包括开源和专有模型;2) 使用相同的提示,让每个LLM生成多次临床笔记;3) 使用字符串匹配、语义相似度计算等方法,评估生成笔记的一致性、语义一致性和语义相似性;4) 分析实验结果,找出在CNG任务中表现最可靠的LLM。
关键创新:该研究的关键创新在于系统性地评估了多个LLM在CNG任务中的可靠性,并提出了具体的评估指标(一致性率、语义一致性和语义相似性)。此外,该研究还推荐了本地部署小型开源模型用于CNG,以确保符合数据隐私法规。
关键设计:论文的关键设计包括:1) 选择了具有代表性的LLM模型,覆盖了不同的模型架构和规模;2) 使用了标准化的提示,以确保实验的可重复性;3) 采用了多种评估指标,从不同角度衡量生成笔记的可靠性;4) 考虑了数据隐私问题,推荐本地部署小型开源模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Meta的Llama 70B模型在临床笔记生成任务中表现出最高的可靠性,其次是Mistral的Small模型。这些模型在多次迭代中能够生成语义一致且与专家笔记相似的文本。研究推荐本地部署这些相对较小的开源模型,以兼顾性能和数据隐私。
🎯 应用场景
该研究成果可应用于临床文档辅助生成系统,帮助医疗服务提供者更高效、准确地记录患者信息。通过选择可靠的LLM,可以提高临床笔记的质量,减少医疗错误,并确保患者数据的隐私安全。未来,该研究可扩展到其他医疗文本生成任务,如病历摘要、诊断报告等。
📄 摘要(原文)
Due to the legal and ethical responsibilities of healthcare providers (HCPs) for accurate documentation and protection of patient data privacy, the natural variability in the responses of large language models (LLMs) presents challenges for incorporating clinical note generation (CNG) systems, driven by LLMs, into real-world clinical processes. The complexity is further amplified by the detailed nature of texts in CNG. To enhance the confidence of HCPs in tools powered by LLMs, this study evaluates the reliability of 12 open-weight and proprietary LLMs from Anthropic, Meta, Mistral, and OpenAI in CNG in terms of their ability to generate notes that are string equivalent (consistency rate), have the same meaning (semantic consistency) and are correct (semantic similarity), across several iterations using the same prompt. The results show that (1) LLMs from all model families are stable, such that their responses are semantically consistent despite being written in various ways, and (2) most of the LLMs generated notes close to the corresponding notes made by experts. Overall, Meta's Llama 70B was the most reliable, followed by Mistral's Small model. With these findings, we recommend the local deployment of these relatively smaller open-weight models for CNG to ensure compliance with data privacy regulations, as well as to improve the efficiency of HCPs in clinical documentation.