Generalizable Process Reward Models via Formally Verified Training Data
作者: Ryo Kamoi, Yusen Zhang, Nan Zhang, Sarkar Snigdha Sarathi Das, Rui Zhang
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-09-27)
备注: Datasets, models, and code are provided at https://github.com/psunlpgroup/FoVer. Please also refer to our project website at https://fover-prm.github.io/
🔗 代码/项目: GITHUB
💡 一句话要点
提出FoVer,通过形式化验证自动生成训练数据,提升通用过程奖励模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 形式化验证 自动化标注 推理验证 大型语言模型
📋 核心要点
- 现有过程奖励模型依赖昂贵的人工标注,且泛化能力有限,主要集中在数学推理领域。
- FoVer利用形式化验证工具自动生成高质量训练数据,无需人工标注,并提升模型泛化能力。
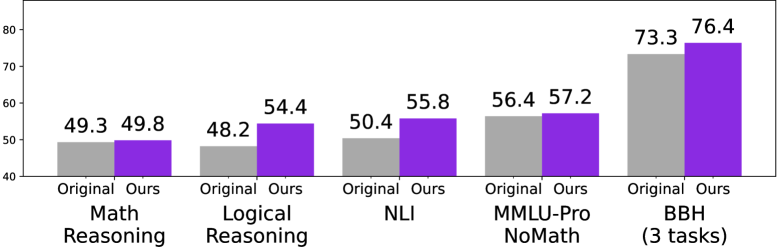
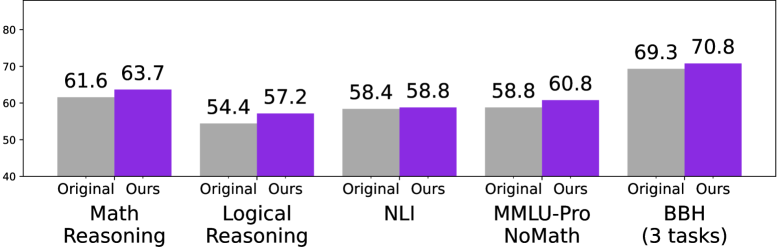
- 实验表明,FoVer训练的PRM在多种推理任务上优于现有方法,并在ProcessBench和多个基准测试中取得领先。
📝 摘要(中文)
过程奖励模型(PRMs)为大型语言模型(LLM)生成的推理轨迹提供步骤级别的反馈,正受到越来越多的关注。然而,仍然存在两个关键的研究空白:创建PRM训练数据需要昂贵的人工标注来标记准确的步骤级别错误,并且现有的PRM仅限于数学推理领域。为了解决这些问题,本文旨在实现自动合成准确的PRM训练数据,并将PRM推广到数学推理之外的各种推理任务。我们提出了FoVer,一种通过形式化验证工具(如Z3和Isabelle)自动标注准确的步骤级别错误标签来合成PRM训练数据的方法。为了展示FoVer的实际有效性,我们通过标注LLM对形式逻辑和定理证明任务的响应中的步骤级别错误标签来合成训练数据集,而无需依赖人工标注。虽然FoVer创建的训练数据与形式化验证兼容的符号任务,但我们的实验表明,在我们的数据集上训练的PRM表现出跨任务泛化能力,使单个PRM能够有效地执行跨各种推理任务的验证。具体而言,使用FoVer训练的基于LLM的PRM显著优于基于原始LLM的PRM,并且在ProcessBench上的步骤级别验证以及包括MATH、AIME、ANLI、MMLU和BBH在内的12个推理基准测试中的Best-of-K性能方面,与最先进的PRM相比,实现了具有竞争力或更优越的结果。数据集和代码在补充材料中,并将公开。
🔬 方法详解
问题定义:现有过程奖励模型(PRM)的训练依赖于大量人工标注的步骤级错误数据,成本高昂。此外,现有PRM的泛化能力不足,主要集中在数学推理领域,难以应用于更广泛的推理任务。因此,如何自动生成高质量的训练数据,并提升PRM在不同推理任务上的泛化能力是本文要解决的核心问题。
核心思路:本文的核心思路是利用形式化验证工具(如Z3和Isabelle)来自动标注LLM生成的推理步骤中的错误。形式化验证能够提供精确的、可信的错误标签,从而避免人工标注的成本和主观性。通过在这些自动标注的数据上训练PRM,可以提升模型对推理过程的理解和泛化能力。
技术框架:FoVer方法包含以下几个主要步骤:1) 使用LLM生成对形式逻辑和定理证明任务的推理轨迹;2) 使用形式化验证工具对每个推理步骤进行验证,自动标注错误;3) 使用标注后的数据训练PRM;4) 使用训练好的PRM对新的推理任务进行步骤级验证。整体流程无需人工干预,实现了训练数据的自动生成和PRM的训练。
关键创新:FoVer的关键创新在于利用形式化验证工具自动生成PRM的训练数据。与传统的人工标注方法相比,FoVer能够提供更准确、更可靠的错误标签,并且大大降低了数据标注的成本。此外,通过在形式逻辑和定理证明等符号任务上进行训练,可以提升PRM的泛化能力,使其能够应用于更广泛的推理任务。
关键设计:FoVer的关键设计包括:1) 选择合适的LLM作为推理轨迹的生成器;2) 选择合适的的形式化验证工具,并设计相应的验证规则;3) 设计合适的PRM网络结构,例如使用Transformer模型来捕捉推理步骤之间的依赖关系;4) 设计合适的损失函数,例如使用交叉熵损失来训练PRM对错误进行分类。
🖼️ 关键图片
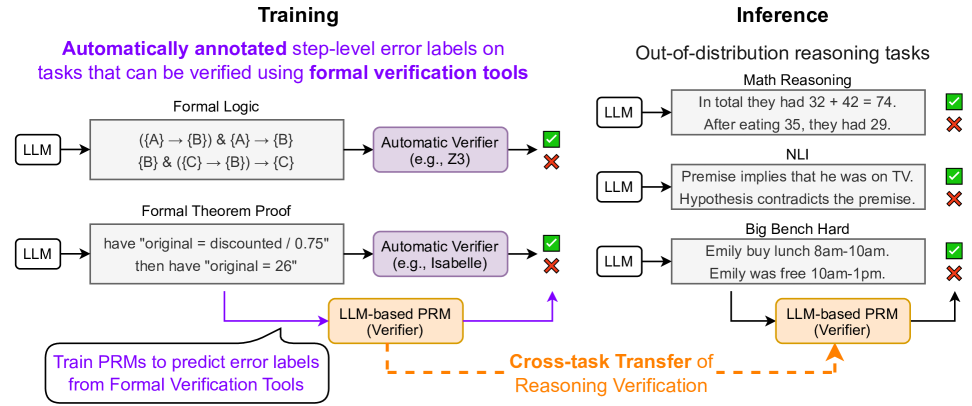
📊 实验亮点
实验结果表明,使用FoVer训练的PRM在ProcessBench上的步骤级别验证中取得了显著的性能提升,并且在包括MATH、AIME、ANLI、MMLU和BBH在内的12个推理基准测试中,与最先进的PRM相比,实现了具有竞争力或更优越的结果。这表明FoVer能够有效地提升PRM的性能和泛化能力。
🎯 应用场景
该研究成果可应用于自动化推理验证、智能教育辅导、代码调试等领域。通过自动评估LLM的推理过程,可以提高LLM的可靠性和安全性。在教育领域,可以为学生提供个性化的学习反馈,帮助他们更好地理解和掌握知识。在代码调试领域,可以自动检测代码中的逻辑错误,提高开发效率。
📄 摘要(原文)
Process Reward Models (PRMs), which provide step-level feedback on reasoning traces generated by Large Language Models (LLMs), are receiving increasing attention. However, two key research gaps remain: creating PRM training data requires costly human annotation to label accurate step-level errors, and existing PRMs are limited to math reasoning domains. In response to these gaps, this paper aims to enable automatic synthesis of accurate PRM training data and the generalization of PRMs to diverse reasoning tasks beyond math reasoning. We propose FoVer, an approach to synthesize PRM training data with accurate step-level error labels automatically annotated by formal verification tools, such as Z3 and Isabelle. To show the practical effectiveness of FoVer, we synthesize a training dataset by annotating step-level error labels on LLM responses to formal logic and theorem proving tasks, without relying on human annotation. While FoVer creates training data with symbolic tasks compatible with formal verification, our experiments show that PRMs trained on our dataset exhibit cross-task generalization, enabling a single PRM to effectively perform verification across diverse reasoning tasks. Specifically, LLM-based PRMs trained with FoVer significantly outperform PRMs based on the original LLMs and achieve competitive or superior results compared to state-of-the-art PRMs, as measured by step-level verification on ProcessBench and Best-of-K performance across 12 reasoning benchmarks, including MATH, AIME, ANLI, MMLU, and BBH. The dataset and code are in the supplementary material and will be made public. The datasets, models, and code are provided at https://github.com/psunlpgroup/FoVer.