GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
作者: Yuqi Zhou, Sunhao Dai, Shuai Wang, Kaiwen Zhou, Qinglin Jia, Jun Xu
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-05-21 (更新: 2025-05-22)
🔗 代码/项目: GITHUB
💡 一句话要点
提出GUI-G1以解决GUI代理视觉定位中的训练挑战
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图形用户界面 强化学习 视觉定位 推理链 奖励机制 模型优化 智能代理
📋 核心要点
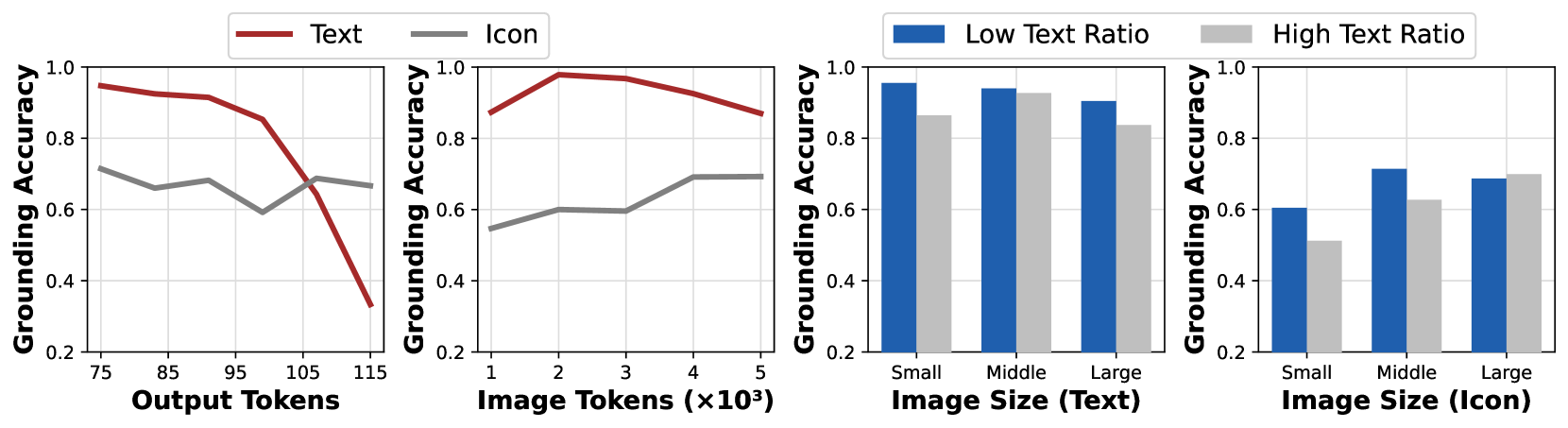
- 现有方法在GUI代理的视觉定位中面临输入设计、输出评估和策略更新等多方面的挑战,导致性能不佳。
- 论文提出的解决方案包括快速思维模板、框大小约束和难度感知的RL目标调整,旨在优化训练过程。
- 实验结果显示,GUI-G1-3B在多个基准测试中表现优异,准确率显著高于现有模型,验证了方法的有效性。
📝 摘要(中文)
近年来,图形用户界面(GUI)代理通过结合在线强化学习(RL)和明确的推理链来复制R1-Zero范式,从而在对象定位上取得了显著的性能提升。本文首先对该训练流程的三个关键组成部分进行了广泛的分析实验:输入设计、输出评估和策略更新,揭示了在未针对GUI定位任务进行适应时,盲目应用通用RL所带来的不同挑战。为了解决这些问题,我们提出了三种针对性的解决方案,包括采用快速思维模板、引入框大小约束以及调整RL目标。我们的GUI-G1-3B在17K公共样本上训练,达到了ScreenSpot 90.3%的准确率和ScreenSpot-Pro 37.1%的准确率,超越了所有类似规模的先前模型,甚至超过了更大的UI-TARS-7B,确立了GUI代理定位的新状态。
🔬 方法详解
问题定义:本文旨在解决在图形用户界面(GUI)代理的视觉定位任务中,现有强化学习方法在输入设计、输出评估和策略更新方面的不足,导致模型性能不佳。
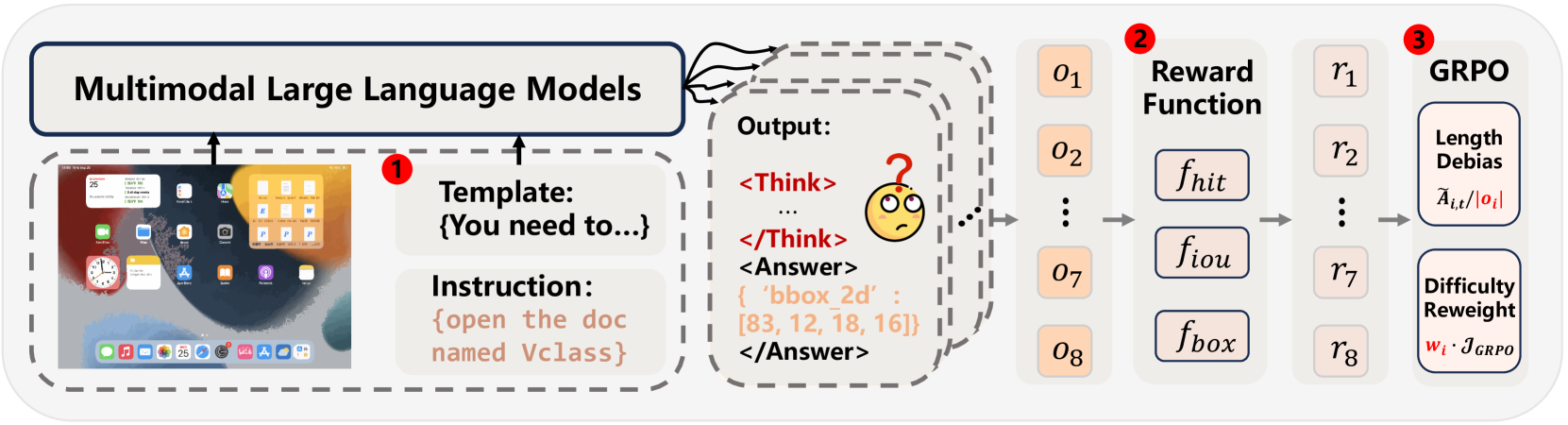
核心思路:通过引入快速思维模板以减少过度推理,结合框大小约束和难度感知的目标调整,来优化训练过程,从而提高模型在复杂任务中的表现。
技术框架:整体架构包括输入设计模块、输出评估模块和策略更新模块。输入设计模块负责生成推理链,输出评估模块评估模型的定位精度,策略更新模块则根据反馈调整模型策略。
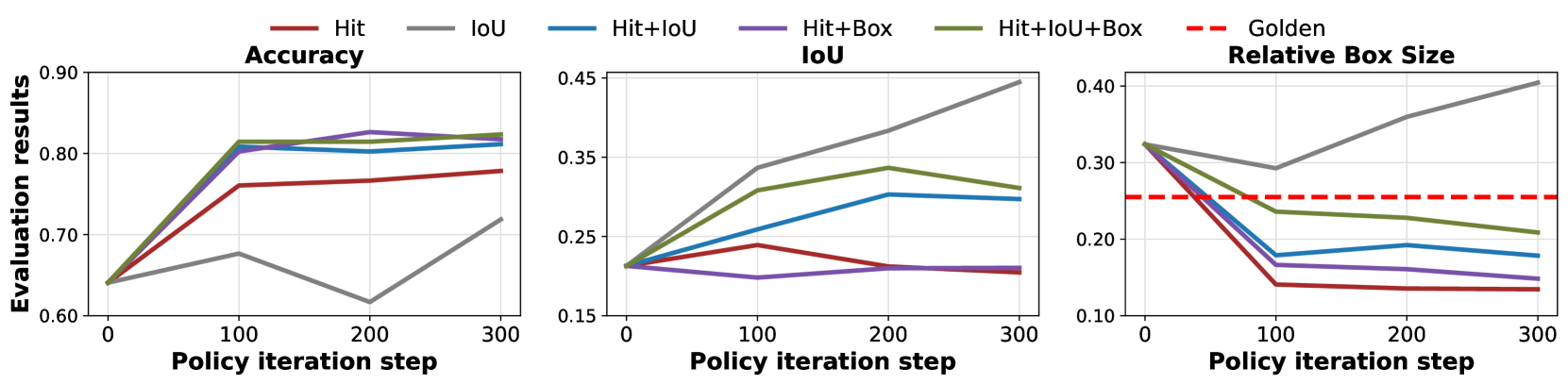
关键创新:最重要的技术创新在于提出了快速思维模板和框大小约束,这些设计有效防止了奖励黑客行为并提升了模型在困难样本上的优化能力。
关键设计:在损失函数中引入了长度归一化和难度感知的缩放因子,确保模型在训练时能够更好地处理不同难度的样本,同时优化了奖励函数以减少对框大小的依赖。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GUI-G1-3B在ScreenSpot基准测试中达到了90.3%的准确率,在ScreenSpot-Pro中达到了37.1%的准确率,超越了所有类似规模的模型,甚至在性能上超过了更大的UI-TARS-7B,确立了新的技术领先地位。
🎯 应用场景
该研究的潜在应用领域包括智能助手、自动化测试和用户界面设计等。通过提高GUI代理的视觉定位能力,可以显著提升用户交互体验和系统的智能化水平,未来可能在各类人机交互场景中发挥重要作用。
📄 摘要(原文)
Recent Graphical User Interface (GUI) agents replicate the R1-Zero paradigm, coupling online Reinforcement Learning (RL) with explicit chain-of-thought reasoning prior to object grounding and thereby achieving substantial performance gains. In this paper, we first conduct extensive analysis experiments of three key components of that training pipeline: input design, output evaluation, and policy update-each revealing distinct challenges arising from blindly applying general-purpose RL without adapting to GUI grounding tasks. Input design: Current templates encourage the model to generate chain-of-thought reasoning, but longer chains unexpectedly lead to worse grounding performance. Output evaluation: Reward functions based on hit signals or box area allow models to exploit box size, leading to reward hacking and poor localization quality. Policy update: Online RL tends to overfit easy examples due to biases in length and sample difficulty, leading to under-optimization on harder cases. To address these issues, we propose three targeted solutions. First, we adopt a Fast Thinking Template that encourages direct answer generation, reducing excessive reasoning during training. Second, we incorporate a box size constraint into the reward function to mitigate reward hacking. Third, we revise the RL objective by adjusting length normalization and adding a difficulty-aware scaling factor, enabling better optimization on hard samples. Our GUI-G1-3B, trained on 17K public samples with Qwen2.5-VL-3B-Instruct, achieves 90.3% accuracy on ScreenSpot and 37.1% on ScreenSpot-Pro. This surpasses all prior models of similar size and even outperforms the larger UI-TARS-7B, establishing a new state-of-the-art in GUI agent grounding. The project repository is available at https://github.com/Yuqi-Zhou/GUI-G1.