VocalBench: Benchmarking the Vocal Conversational Abilities for Speech Interaction Models
作者: Heyang Liu, Yuhao Wang, Ziyang Cheng, Hongcheng Liu, Yiqi Li, Yixuan Hou, Ronghua Wu, Qunshan Gu, Yanfeng Wang, Yu Wang
分类: cs.CL
发布日期: 2025-05-21 (更新: 2026-01-13)
💡 一句话要点
VocalBench:用于评估语音交互模型会话能力的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音交互模型 会话能力评估 基准数据集 语音大语言模型 人机对话
📋 核心要点
- 现有语音交互模型评估缺乏真实场景模拟,且侧重于独立方面性能,缺乏综合能力对比。
- VocalBench旨在通过构建包含多维度、多角色的语音会话数据集,全面评估语音交互模型的会话能力。
- 实验结果揭示了现有模型在语义理解、声学处理、会话流畅性和鲁棒性方面的共性挑战。
📝 摘要(中文)
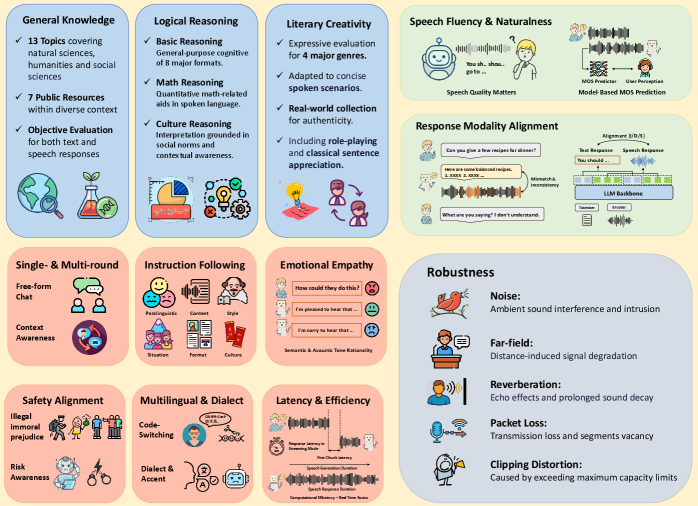
语音大语言模型(SpeechLLMs)已将人机交互从文本模态扩展到动态语音领域。口语对话传递多种信息,包括语义概念、声学变化、副语言线索和环境背景。然而,现有对语音交互模型的评估缺乏模拟真实场景的实例,并且主要侧重于对不同方面的性能评估,缺乏对当前方法之间关键能力的全面比较。为了解决这一差距,我们提出了VocalBench来评估语音会话能力,它包含约24k个精心策划的英语和普通话实例,涵盖四个关键维度——语义质量、声学性能、会话能力和鲁棒性,覆盖14个面向用户的角色。对27个主流模型的实验揭示了当前方法的常见挑战,并强调了对下一代语音交互系统的新见解的需求。
🔬 方法详解
问题定义:现有语音交互模型的评估方法主要存在两个痛点。一是缺乏足够真实和全面的测试用例,难以准确反映模型在实际应用中的表现。二是评估指标过于单一,通常只关注语义理解或语音识别的准确率,忽略了会话的流畅性、自然度和鲁棒性等重要方面。
核心思路:VocalBench的核心思路是构建一个高质量、多维度的语音会话数据集,并设计相应的评估指标,从而全面评估语音交互模型的会话能力。该数据集模拟了真实的人机对话场景,涵盖了不同的用户角色、对话主题和环境噪声,旨在更真实地反映模型在实际应用中的性能。
技术框架:VocalBench的整体框架包括数据收集、数据标注、数据划分和评估指标设计四个主要阶段。首先,通过众包和人工录制等方式收集大量的语音会话数据。然后,对数据进行多维度的标注,包括语义信息、声学特征、会话上下文和用户角色等。接着,将数据划分为训练集、验证集和测试集。最后,设计一系列评估指标,用于衡量模型在语义质量、声学性能、会话能力和鲁棒性等方面的表现。
关键创新:VocalBench的关键创新在于其数据集的全面性和评估指标的多样性。与现有数据集相比,VocalBench涵盖了更多的用户角色、对话主题和环境噪声,能够更真实地反映模型在实际应用中的性能。此外,VocalBench还设计了一系列新的评估指标,用于衡量模型在会话流畅性、自然度和鲁棒性等方面的表现,从而更全面地评估模型的会话能力。
关键设计:VocalBench数据集包含约24k个英语和普通话实例,涵盖14个面向用户的角色。评估指标包括语义质量(如语义准确率、信息完整性)、声学性能(如语音识别准确率、语音合成质量)、会话能力(如对话轮数、上下文一致性)和鲁棒性(如抗噪声能力、抗口音能力)。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
VocalBench对27个主流模型进行了评估,揭示了当前语音交互模型在语义理解、声学处理、会话流畅性和鲁棒性方面的共性挑战。实验结果表明,现有模型在处理复杂对话场景和噪声环境时表现不佳,需要进一步改进。具体的性能数据和提升幅度在摘要中未提及,属于未知信息。
🎯 应用场景
VocalBench可用于评估和改进各种语音交互系统,如智能助手、语音客服、智能家居等。通过使用VocalBench进行评估,可以发现现有模型的不足之处,并指导模型的改进方向,从而提升语音交互系统的用户体验和实用价值。该基准的发布将促进语音交互技术的进一步发展。
📄 摘要(原文)
Speech large language models (SpeechLLMs) have extended human-machine interactions from the text modality to the dynamic speech domain. Spoken dialogues convey diverse information, including semantic concepts, acoustic variations, paralanguage cues, and environmental context. However, existing evaluations of speech interaction models lack instances mimicking real scenarios and predominantly focus on the performance of distinct aspects, lacking a comprehensive comparison of critical capabilities between current routines. To address this gap, we propose VocalBench to assess the speech conversational abilities, comprising around 24k carefully curated instances of both English and Mandarin across four key dimensions - semantic quality, acoustic performance, conversational abilities, and robustness, covering 14 user-oriented characters. Experiments on 27 mainstream models reveal the common challenges for current routes, and highlight the need for new insights into next-generation speech interactive systems.