Shared Path: Unraveling Memorization in Multilingual LLMs through Language Similarities
作者: Xiaoyu Luo, Yiyi Chen, Johannes Bjerva, Qiongxiu Li
分类: cs.CL, cs.AI
发布日期: 2025-05-21 (更新: 2026-01-06)
备注: 17 pages, 14 tables, 10 figures
期刊: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19372-19388, Suzhou, China
DOI: 10.18653/v1/2025.emnlp-main.978
💡 一句话要点
通过语言相似性揭示多语言LLM中的记忆现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 记忆 语言相似性 跨语言迁移 图神经网络
📋 核心要点
- 现有研究主要关注单语LLM的记忆,忽略了多语言场景下数据长尾分布带来的挑战。
- 论文提出一种基于图的跨语言相关性度量,利用语言相似性分析MLLM的记忆模式。
- 实验表明,相似语言中训练数据少的语言记忆程度更高,验证了语言相似性对记忆的影响。
📝 摘要(中文)
本文首次对多语言大型语言模型(MLLM)中的记忆现象进行了全面研究,使用不同规模、架构和记忆定义的模型分析了95种语言。随着MLLM的日益普及,理解其记忆行为至关重要。然而,以往的研究主要集中在单语模型上,使得多语言记忆现象未被充分探索,尽管训练语料本质上具有长尾特性。我们发现,认为记忆与训练数据可用性高度相关的普遍假设,无法完全解释MLLM中的记忆模式。我们假设,传统上对单语环境的关注,实际上是将语言孤立对待,这可能会掩盖记忆的真实模式。为了解决这个问题,我们提出了一种新的基于图的相关性度量,该度量结合了语言相似性来分析跨语言记忆。我们的分析表明,在相似的语言中,训练token较少的语言往往表现出更高的记忆,这种趋势只有在显式建模跨语言关系时才会出现。这些发现强调了在评估和减轻MLLM中的记忆漏洞时,采用“语言感知”视角的重要性。这也构成了经验证据,表明语言相似性既解释了MLLM中的记忆,又支撑了跨语言迁移能力,对多语言NLP具有广泛的影响。
🔬 方法详解
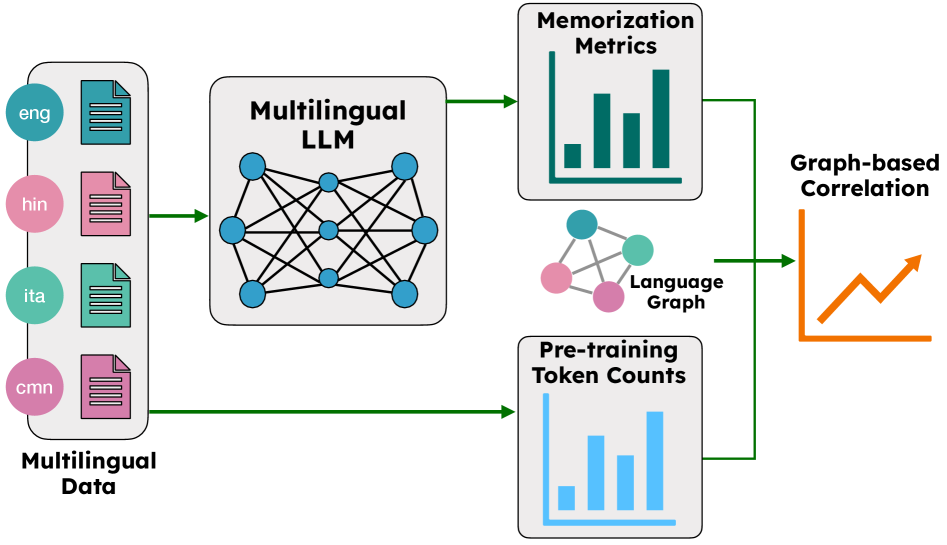
问题定义:现有的关于LLM记忆的研究主要集中在单语模型上,忽略了多语言LLM中由于训练数据分布不均(长尾分布)以及语言之间的相似性可能带来的影响。因此,如何理解和解释多语言LLM中的记忆现象,以及如何利用语言之间的关系来更好地评估和减轻记忆带来的风险,是本文要解决的核心问题。现有方法未能充分考虑语言相似性对记忆的影响,导致对多语言LLM记忆行为的理解不完整。
核心思路:本文的核心思路是,语言之间的相似性会影响MLLM的记忆行为。具体来说,如果两种语言很相似,那么模型在一种语言上学到的知识可能会迁移到另一种语言上,从而影响模型在不同语言上的记忆程度。因此,本文提出了一种基于图的跨语言相关性度量,将语言之间的相似性纳入考虑,从而更准确地分析MLLM的记忆模式。这样设计的目的是为了克服传统方法将语言孤立对待的局限性,揭示多语言LLM中更深层次的记忆规律。
技术框架:本文的技术框架主要包括以下几个步骤:1) 选择多个不同规模和架构的MLLM;2) 收集95种语言的训练数据和测试数据;3) 使用不同的记忆定义来评估MLLM在不同语言上的记忆程度;4) 构建一个语言相似性图,其中节点代表语言,边代表语言之间的相似性;5) 使用基于图的相关性度量来分析跨语言记忆的相关性;6) 分析实验结果,验证语言相似性对记忆的影响。
关键创新:本文最重要的技术创新点在于提出了基于图的跨语言相关性度量。与传统的单语相关性度量相比,该度量能够将语言之间的相似性纳入考虑,从而更准确地分析MLLM的记忆模式。这种方法能够揭示传统方法无法发现的跨语言记忆现象,例如,相似语言中训练数据少的语言记忆程度更高。
关键设计:在构建语言相似性图时,本文使用了多种语言相似性度量,例如基于语言学特征的相似性、基于词汇重叠的相似性等。在计算基于图的相关性时,本文使用了图神经网络来学习语言之间的关系,并将其用于预测MLLM在不同语言上的记忆程度。此外,本文还使用了不同的记忆定义,例如精确匹配、模糊匹配等,以评估MLLM在不同情况下的记忆行为。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在相似的语言中,训练token较少的语言往往表现出更高的记忆,这一趋势只有在显式建模跨语言关系时才会显现。这表明传统的单语视角可能会低估低资源语言的记忆风险。通过引入基于图的跨语言相关性度量,该研究能够更准确地评估MLLM在不同语言上的记忆程度,并为减轻记忆漏洞提供新的思路。
🎯 应用场景
该研究成果可应用于多语言LLM的安全性评估和风险控制,帮助开发者更好地理解和减轻模型中的记忆漏洞。通过考虑语言相似性,可以更有效地识别和缓解模型在低资源语言上的过拟合问题,提升MLLM在各种语言环境下的可靠性和公平性。此外,该研究也为跨语言迁移学习提供了新的视角,有助于开发更高效的多语言学习算法。
📄 摘要(原文)
We present the first comprehensive study of Memorization in Multilingual Large Language Models (MLLMs), analyzing 95 languages using models across diverse model scales, architectures, and memorization definitions. As MLLMs are increasingly deployed, understanding their memorization behavior has become critical. Yet prior work has focused primarily on monolingual models, leaving multilingual memorization underexplored, despite the inherently long-tailed nature of training corpora. We find that the prevailing assumption, that memorization is highly correlated with training data availability, fails to fully explain memorization patterns in MLLMs. We hypothesize that the conventional focus on monolingual settings, effectively treating languages in isolation, may obscure the true patterns of memorization. To address this, we propose a novel graph-based correlation metric that incorporates language similarity to analyze cross-lingual memorization. Our analysis reveals that among similar languages, those with fewer training tokens tend to exhibit higher memorization, a trend that only emerges when cross-lingual relationships are explicitly modeled. These findings underscore the importance of a \textit{language-aware} perspective in evaluating and mitigating memorization vulnerabilities in MLLMs. This also constitutes empirical evidence that language similarity both explains Memorization in MLLMs and underpins Cross-lingual Transferability, with broad implications for multilingual NLP.