LyapLock: Bounded Knowledge Preservation in Sequential Large Language Model Editing
作者: Peng Wang, Biyu Zhou, Xuehai Tang, Jizhong Han, Songlin Hu
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-10-26)
备注: EMNLP 2025 main
🔗 代码/项目: GITHUB
💡 一句话要点
LyapLock:序列大语言模型编辑中保证有界知识保留的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型编辑 知识保留 序列编辑 Lyapunov优化 排队论 约束优化 模型更新
📋 核心要点
- 现有模型编辑方法在序列编辑中性能下降,原因是缺乏长期知识保留机制。
- LyapLock将序列编辑建模为约束随机规划,利用排队论和Lyapunov优化分解问题。
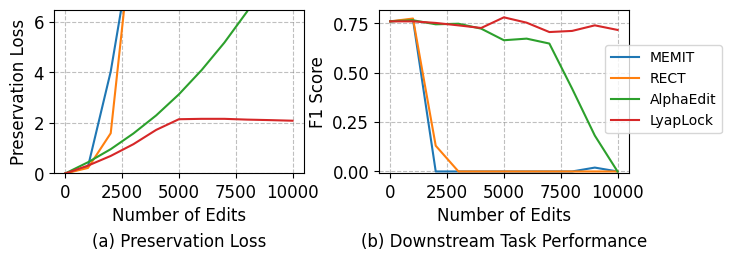
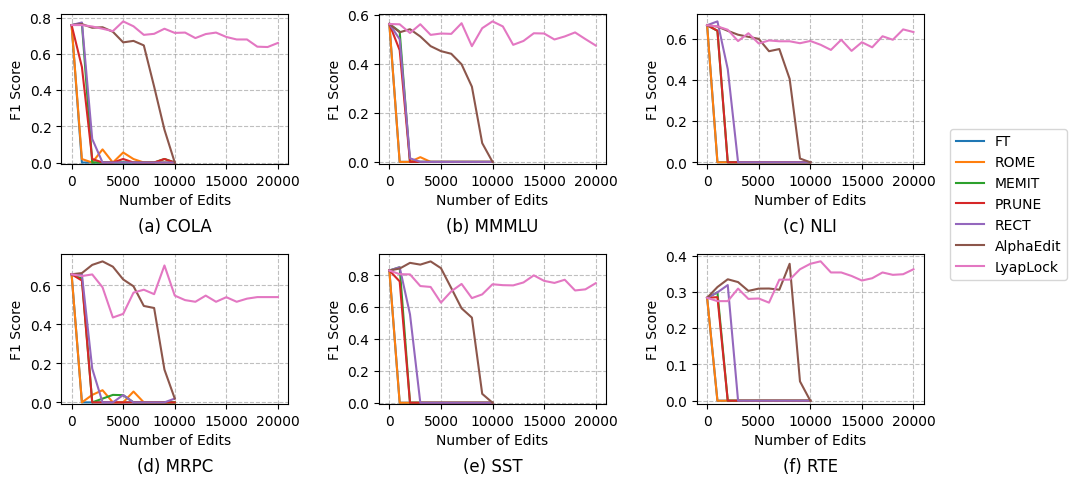
- 实验表明,LyapLock能扩展编辑能力至10000次以上,并提升编辑效果11.89%。
📝 摘要(中文)
大型语言模型常常包含不正确或过时的知识,因此需要模型编辑方法来进行精确的知识更新。然而,当前主流的“定位-编辑”方法在序列编辑过程中表现出性能逐渐下降的趋势,这是由于缺乏长期知识保留的有效机制。为了解决这个问题,我们将序列编辑建模为一个约束随机规划问题。考虑到累积保留误差约束和逐渐揭示的编辑任务带来的挑战,我们提出了 extbf{LyapLock}。它整合了排队论和Lyapunov优化,将长期约束规划分解为易于处理的逐步子问题,从而实现高效求解。这是第一个具有严格理论保证的模型编辑框架,在满足长期知识保留约束的同时,实现了渐近最优的编辑性能。实验结果表明,我们的框架可以将序列编辑能力扩展到超过10,000次编辑,同时稳定通用能力,并将平均编辑效果比SOTA基线提高11.89%。此外,它还可以用于增强基线方法的性能。我们的代码已在https://github.com/caskcsg/LyapLock上发布。
🔬 方法详解
问题定义:论文旨在解决序列大语言模型编辑中的知识遗忘问题。现有“定位-编辑”方法在多次连续编辑后,由于缺乏有效的长期知识保留机制,会导致模型性能显著下降,无法保证编辑的可靠性和一致性。
核心思路:论文的核心思路是将序列编辑过程视为一个约束随机规划问题,目标是在满足长期知识保留约束的前提下,最大化编辑的有效性。通过引入排队论和Lyapunov优化,将复杂的长期约束问题分解为一系列易于求解的子问题,从而实现高效的在线编辑。
技术框架:LyapLock框架主要包含以下几个模块:1) 编辑任务队列:用于存储待编辑的知识条目。2) Lyapunov优化器:负责根据当前模型状态和编辑任务队列,动态调整编辑策略,以满足长期知识保留约束。3) 模型编辑模块:采用现有的模型编辑方法(如LoRA、FT等)对模型进行知识更新。4) 知识评估模块:用于评估模型在编辑后的知识保留情况,并将评估结果反馈给Lyapunov优化器。
关键创新:LyapLock的关键创新在于其将排队论和Lyapunov优化引入到模型编辑领域,从而能够对长期知识保留进行建模和优化。与现有方法相比,LyapLock具有严格的理论保证,能够确保在序列编辑过程中,模型的知识不会被过度遗忘。此外,LyapLock还能够自适应地调整编辑策略,以应对不同的编辑任务和模型状态。
关键设计:LyapLock的关键设计包括:1) Lyapunov函数的设计:用于衡量模型的知识保留状态,并作为优化目标的一部分。2) 虚拟队列的设计:用于模拟知识的流入和流出,从而能够对长期知识保留进行建模。3) 编辑策略的优化:通过求解一系列子问题,动态调整编辑策略,以满足长期知识保留约束。具体而言,论文使用漂移-惩罚框架,将长期约束转化为短期优化目标,并使用梯度下降等方法求解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LyapLock能够显著提高序列编辑的性能。在超过10,000次编辑的场景下,LyapLock能够稳定模型的通用能力,并将平均编辑效果比SOTA基线方法提高11.89%。此外,LyapLock还可以作为一种通用框架,用于增强现有模型编辑方法的性能。
🎯 应用场景
LyapLock可应用于需要频繁更新知识的大语言模型,例如聊天机器人、知识问答系统等。通过保证长期知识的准确性和一致性,可以提高这些应用的用户体验和可靠性。此外,该方法还可以用于构建更加可信赖和安全的AI系统,避免因知识错误而导致的潜在风险。
📄 摘要(原文)
Large Language Models often contain factually incorrect or outdated knowledge, giving rise to model editing methods for precise knowledge updates. However, current mainstream locate-then-edit approaches exhibit a progressive performance decline during sequential editing, due to inadequate mechanisms for long-term knowledge preservation. To tackle this, we model the sequential editing as a constrained stochastic programming. Given the challenges posed by the cumulative preservation error constraint and the gradually revealed editing tasks, \textbf{LyapLock} is proposed. It integrates queuing theory and Lyapunov optimization to decompose the long-term constrained programming into tractable stepwise subproblems for efficient solving. This is the first model editing framework with rigorous theoretical guarantees, achieving asymptotic optimal editing performance while meeting the constraints of long-term knowledge preservation. Experimental results show that our framework scales sequential editing capacity to over 10,000 edits while stabilizing general capabilities and boosting average editing efficacy by 11.89\% over SOTA baselines. Furthermore, it can be leveraged to enhance the performance of baseline methods. Our code is released on https://github.com/caskcsg/LyapLock.