Can Large Language Models be Effective Online Opinion Miners?
作者: Ryang Heo, Yongsik Seo, Junseong Lee, Dongha Lee
分类: cs.CL
发布日期: 2025-05-21 (更新: 2025-10-22)
备注: Accepted to EMNLP 2025 Main
💡 一句话要点
提出OOMB基准数据集,评估大语言模型在在线意见挖掘中的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线意见挖掘 大型语言模型 基准数据集 自然语言处理 用户生成内容
📋 核心要点
- 现有意见挖掘方法难以处理在线内容的多样性、复杂性和上下文依赖性。
- 论文提出OOMB基准数据集和评估协议,用于评估LLM在在线意见挖掘中的能力。
- 通过OOMB,分析了LLM在意见挖掘中的优势和不足,为未来研究提供方向。
📝 摘要(中文)
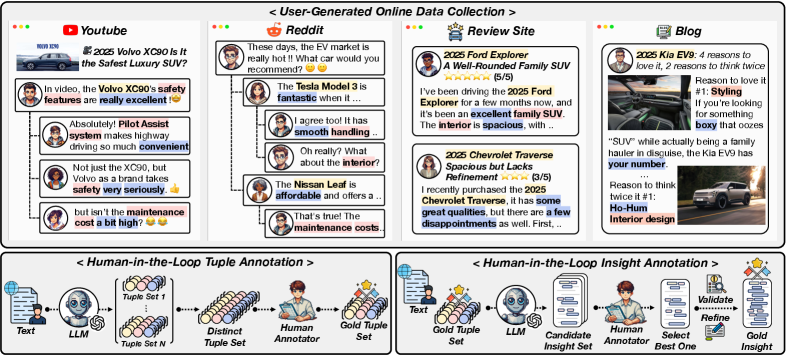
用户生成的在线内容蕴含着丰富的客户偏好和市场趋势洞察。然而,这些内容的高度多样性、复杂性和富含上下文的特性,给传统的意见挖掘方法带来了巨大的挑战。为了解决这个问题,我们引入了在线意见挖掘基准(OOMB),这是一个新颖的数据集和评估协议,旨在评估大型语言模型(LLM)从多样化和复杂的在线环境中有效挖掘意见的能力。OOMB提供了广泛的(实体、特征、意见)元组标注和一个全面的以意见为中心的摘要,突出了每个内容中的关键意见主题,从而能够评估模型的抽取和抽象能力。通过我们提出的基准,我们对哪些方面仍然具有挑战性以及LLM在哪些方面表现出适应性进行了全面分析,以探索它们是否可以有效地充当现实在线场景中的意见挖掘者。这项研究为基于LLM的意见挖掘奠定了基础,并讨论了该领域未来研究的方向。
🔬 方法详解
问题定义:论文旨在解决传统意见挖掘方法在处理复杂、多样化的在线用户生成内容时遇到的困难。现有方法难以有效提取和概括用户对特定实体和特征的意见,无法充分利用在线内容的上下文信息,导致挖掘结果的准确性和完整性不足。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的自然语言理解和生成能力,直接从在线内容中提取和总结意见。通过构建高质量的基准数据集OOMB,为LLM提供训练和评估的平台,从而推动基于LLM的在线意见挖掘技术的发展。
技术框架:论文主要包含以下几个部分:1)构建OOMB数据集,包含(实体、特征、意见)元组标注和以意见为中心的摘要;2)设计评估协议,用于评估LLM的抽取和抽象能力;3)使用OOMB数据集对现有LLM进行评估,分析其在在线意见挖掘中的表现;4)讨论未来研究方向,例如如何提高LLM在特定领域的意见挖掘能力。
关键创新:论文的关键创新在于提出了OOMB基准数据集,该数据集专门针对在线意见挖掘任务设计,包含了丰富的标注信息和全面的意见摘要,能够有效评估LLM在真实场景下的表现。此外,论文还对现有LLM在OOMB数据集上的表现进行了深入分析,揭示了LLM在意见挖掘方面的优势和不足。
关键设计:OOMB数据集包含多个领域的在线用户生成内容,例如产品评论、社交媒体帖子等。每个内容都标注了多个(实体、特征、意见)元组,以及一个以意见为中心的摘要,该摘要概括了内容中最重要的意见主题。评估协议包括抽取式评估和抽象式评估,分别评估LLM提取和总结意见的能力。论文没有特别提到损失函数或网络结构等技术细节,重点在于数据集的构建和评估协议的设计。
🖼️ 关键图片


📊 实验亮点
论文构建了包含丰富标注信息的OOMB数据集,并对多个LLM进行了评估。实验结果表明,LLM在抽取式意见挖掘方面表现良好,但在抽象式意见挖掘方面仍有提升空间。该研究为未来基于LLM的在线意见挖掘研究提供了重要的基准和参考。
🎯 应用场景
该研究成果可应用于舆情监控、产品评价分析、市场趋势预测等领域。通过利用LLM自动挖掘和总结在线用户意见,企业可以更好地了解客户需求,改进产品和服务,提升市场竞争力。政府部门可以利用该技术进行舆情分析,及时发现和应对社会问题。
📄 摘要(原文)
The surge of user-generated online content presents a wealth of insights into customer preferences and market trends. However, the highly diverse, complex, and context-rich nature of such contents poses significant challenges to traditional opinion mining approaches. To address this, we introduce Online Opinion Mining Benchmark (OOMB), a novel dataset and evaluation protocol designed to assess the ability of large language models (LLMs) to mine opinions effectively from diverse and intricate online environments. OOMB provides extensive (entity, feature, opinion) tuple annotations and a comprehensive opinion-centric summary that highlights key opinion topics within each content, thereby enabling the evaluation of both the extractive and abstractive capabilities of models. Through our proposed benchmark, we conduct a comprehensive analysis of which aspects remain challenging and where LLMs exhibit adaptability, to explore whether they can effectively serve as opinion miners in realistic online scenarios. This study lays the foundation for LLM-based opinion mining and discusses directions for future research in this field.