From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning
作者: David Dinucu-Jianu, Jakub Macina, Nico Daheim, Ido Hakimi, Iryna Gurevych, Mrinmaya Sachan
分类: cs.CL, cs.AI
发布日期: 2025-05-21 (更新: 2025-10-12)
备注: Accepted to EMNLP 2025 Main as an oral presentation. David Dinucu-Jianu and Jakub Macina contributed equally. Code available: https://github.com/eth-lre/PedagogicalRL
💡 一句话要点
提出基于强化学习的LLM教学对齐框架,提升问题解决教学效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 教育应用 教学对齐 智能导师
📋 核心要点
- 现有LLM在教育应用中倾向于直接给出答案,忽略了教学过程中的引导和启发。
- 提出基于强化学习的在线对齐框架,通过模拟师生互动,优化LLM的教学能力。
- 实验表明,该方法训练的7B模型性能接近更大的专有模型,并能平衡教学支持和学生准确率。
📝 摘要(中文)
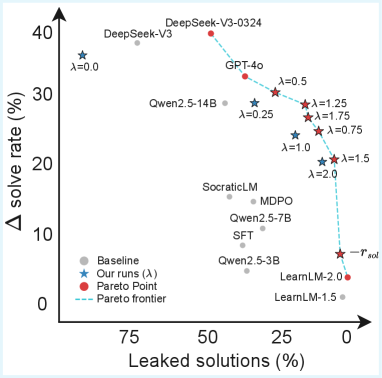
大型语言模型(LLM)可以变革教育,但其针对直接问答的优化往往损害了有效的教学法,而有效的教学法需要策略性地保留答案。为了缓解这个问题,我们提出了一个基于在线强化学习(RL)的对齐框架,该框架可以通过模拟学生-导师互动,快速地将LLM转变为有效的导师,强调教学质量和引导式问题解决,而不是简单地给出答案。我们使用我们的方法训练了一个7B参数的导师模型,无需人工标注,其性能与更大的专有模型(如LearnLM)相似。我们引入了一种可控的奖励加权,以平衡教学支持和学生解决问题的准确性,从而使我们能够追踪这两个目标之间的帕累托前沿。我们的模型比单轮SFT基线更好地保留了推理能力,并且可以选择通过思考标签来增强可解释性,从而暴露模型的教学计划。
🔬 方法详解
问题定义:论文旨在解决LLM在教育场景中,过度关注直接给出答案而忽略教学过程的问题。现有方法,如直接微调(SFT),虽然可以提高LLM的问答准确率,但往往损害其引导学生思考和解决问题的能力,不利于学生的长期学习效果。这种“给答案”式的教学方式,无法有效培养学生的独立思考和问题解决能力。
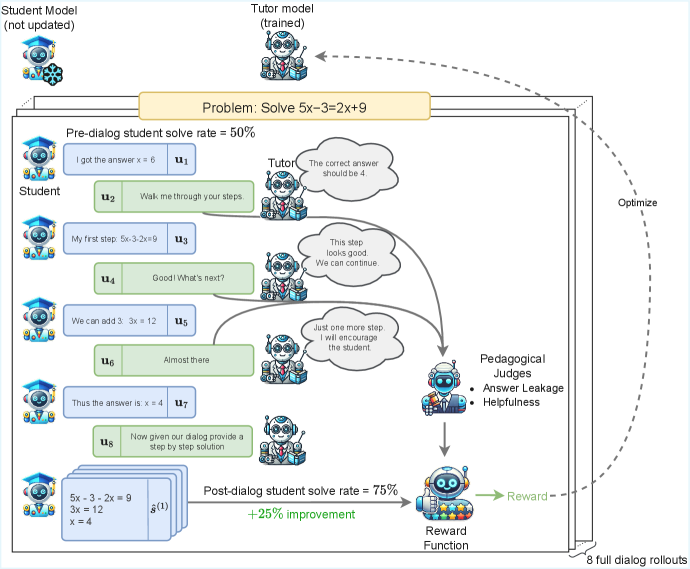
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其能够像一个优秀的导师一样,在与学生的互动过程中,逐步引导学生思考,而不是直接给出答案。通过设计合适的奖励函数,鼓励LLM提供有价值的教学提示和指导,同时惩罚直接给出答案的行为,从而使LLM学会如何在教学支持和学生解决问题能力之间取得平衡。
技术框架:该框架主要包含以下几个部分:1)模拟学生环境:通过预先训练或规则定义的方式模拟学生的行为和反应。2)导师模型:使用LLM作为导师模型,负责生成教学提示和指导。3)强化学习算法:使用在线强化学习算法(具体算法未知)来更新导师模型的参数。4)奖励函数:设计奖励函数,用于评估导师模型的教学效果,包括学生解决问题的准确率、教学提示的质量等。整个流程是一个循环迭代的过程,导师模型根据学生环境的反馈不断调整其教学策略。
关键创新:该论文的关键创新在于将强化学习应用于LLM的教学对齐,使其能够自动学习如何进行有效的教学。与传统的监督学习方法相比,强化学习能够更好地模拟师生互动过程,并根据学生的反馈动态调整教学策略。此外,论文还提出了可控的奖励加权方法,允许用户根据实际需求,调整教学支持和学生解决问题能力之间的平衡。
关键设计:论文中奖励函数的设计是关键。奖励函数需要综合考虑多个因素,例如学生是否正确解决了问题、导师提供的提示是否有效、提示的难度是否适中等。具体奖励函数的细节未知。此外,论文还使用了“思考标签”来增强模型的可解释性,这些标签可以揭示模型的教学计划,帮助用户理解模型的决策过程。具体实现细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法训练的7B参数导师模型,在没有人工标注的情况下,达到了与更大的专有模型(如LearnLM)相似的性能。此外,该模型比单轮SFT基线更好地保留了推理能力,并且可以通过可控的奖励加权,灵活调整教学支持和学生解决问题能力之间的平衡。该模型还通过思考标签增强了可解释性。
🎯 应用场景
该研究成果可应用于智能 tutoring 系统、在线教育平台和个性化学习工具等领域。通过将LLM训练成优秀的导师,可以为学生提供更加个性化、高效和互动的学习体验,帮助学生更好地掌握知识和技能,并培养独立思考和问题解决能力。未来,该技术有望进一步发展,实现更加智能和自适应的教学。
📄 摘要(原文)
Large language models (LLMs) can transform education, but their optimization for direct question-answering often undermines effective pedagogy which requires strategically withholding answers. To mitigate this, we propose an online reinforcement learning (RL)-based alignment framework that can quickly adapt LLMs into effective tutors using simulated student-tutor interactions by emphasizing pedagogical quality and guided problem-solving over simply giving away answers. We use our method to train a 7B parameter tutor model without human annotations which reaches similar performance to larger proprietary models like LearnLM. We introduce a controllable reward weighting to balance pedagogical support and student solving accuracy, allowing us to trace the Pareto frontier between these two objectives. Our models better preserve reasoning capabilities than single-turn SFT baselines and can optionally enhance interpretability through thinking tags that expose the model's instructional planning.